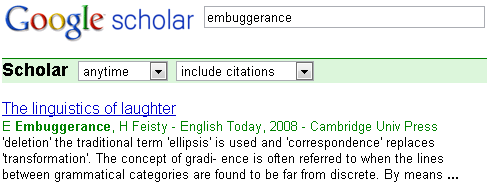
Following on the critiques of the faulty metadata in Google Books that I offered here and in the Chronicle of Higher Education, Peter Jacso of the University of Hawaii writes in the Library Journal that Google Scholar is laced with millions of metadata errors of its own. These include wildly inflated publication and citation counts (which Jacso compares to Bernie Madoff's profit reports), numerous missing author names, and phantom authors assigned by the parser that Google elected to use to extract metadata, rather than using the metadata offered them by scholarly publishers and indexing/abstracting services:
In its stupor, the parser fancies as author names (parts of) section titles, article titles, journal names, company names, and addresses, such as Methods (42,700 records), Evaluation (43,900), Population (23,300), Contents (25,200), Technique(s) (30,000), Results (17,900), Background (10,500), or—in a whopping number of records— Limited (234,000) and Ltd (452,000).
What makes this a serious problem is that many people regard the Google Scholar metadata as a reliable index of scholarly influence and reputation, particularly now that there are tools like the Google Scholar Citation Count gadget by Jan Feyereisl and the Publish or Perish software produced by Tarma Software, both of which take Google Scholar's metadata at face value. True, the data provided by traditional abstracting and indexing services are far from perfect, but their errors are dwarfed by those of Google Scholar, Jacso says.
Of course you could argue that Google's responsibilities with Google Scholar aren't quite analogous to those with Google Book, where the settlement has to pass federal scrutiny and where Google has obligations to the research libraries that provided the scans. Still, you have to feel sorry for any academic whose tenure or promotion case rests in part on the accuracy of one of Google's algorithms.