The and a sex: a replication
« previous post | next post »
On the basis of recent research in social psychology, I calculate that there is a 53% probability that Geoff Pullum is male. That estimate is based the percentage of the and a/an in a recent Language Log post, "Stupid canine lexical acquisition claims", 8/12/2009.
But we shouldn't get too excited about our success in correctly sexing Geoff: the same process, applied to Sarah Palin's recent "Death Panel" facebook post ("Statement on the Current Health Care Debate", 8/7/2009), estimates her probability of being male at 56%.
Although it's easy to make jokes about this, it's based on a solid and interesting result. A recent survey (Newman, M.L., Groom, C.J., Handelman, L.D., & Pennebaker, J.W., "Gender differences in language use: An analysis of 14,000 text samples", Discourse Processes, 45:211-236, 2008) looked at more than 50 "linguistic dimensions", and the difference in use of the/a/an was one of the largest sex differences found.
A few days ago, in a post on "Linguistic analysis in social science", I observed that
Traditional mass media are now nearly all digital; new media are documenting (and creating) social interactions at extraordinary scale and depth; more and more historical records are available in digital form. The digital shadow-universe is a more and more complete proxy for the real one. And in the areas that matter to the social sciences, much of the content of this digital universe exists in the form of digital text and speech.
As a result, I argued, data based on the analysis of speech and language will play an increasingly large role in the social sciences. The relevant effects are generally small ones, but they're easy to measure, and when properly characterized and measured, they can be quite reliable. Furthermore, they're similar in magnitude to effects measured with much greater trouble and expense using traditional social-science methods like surveys and tests. So for today's lunch experiment™ (I was busy with other things over breakfast…) I thought I'd see if I could replicate Newman et al.'s result on sex differences in article usage, using a completely different data set.
First, let's get clear on what Newman et al. found. Their abstract:
Differences in the ways that men and women use language have long been of interest in the study of discourse. Despite extensive theorizing, actual empirical investigations have yet to converge on a coherent picture of gender differences in language. A significant reason is the lack of agreement over the best way to analyze language. In this research, gender differences in language use were examined using standardized categories to analyze a database of over 14,000 text files from 70 separate studies. Women used more words related to psychological and social processes. Men referred more to object properties and impersonal topics.
The summary table of dimensions and effect sizes is on pages 19-20, reproduced for your convenience here. The results for percentages of the/a/an, in particular, were:
| Female mean (stddev) | Male mean (stddev) | Effect Size |
| 6.00 (2.73) | 6.70 (2.94) | d = -.24 |
The "effect size" here is estimated using "Cohen's d", which is the difference in means divided by the pooled standard deviation. This difference in article-use percentage is on the large side, not only among sexual-textual characteristics, but also among cognitive sex differences in general, for example the measures of verbal ability in meta-analytic studies like Janet Shibley Hyde and Marcia C. Linn, "Gender Differences in Verbal Ability: A Meta-Analysis", Psychological Bulletin, 104:1 53-69 (1988).
For more on the interpretation of effect sizes in general, see "Gabby guys: the effect size", 9/23/2006. In this case, if we assume that the distribution of article-use percentages by sex is "normal", then over a large collection of writing-samples, the cited means and standard deviations would yield a distribution of percentages like this:

It's important to be clear that this is not a very big effect, when you look at it from the point of view of men and women as individuals. Since the correlation ("Pearson's r") is related to Cohen's d as
r = d/sqrt(d^2 + 1/(p*q))
(where p and q are the proportions of the two groups being compared), and since their sample was about 58% female, the correlation between sex and article use should be about r = 0.119 — and thus the percent of variance in article use that is accounted for by sex, in their dataset, is about r^2 = 1.4%.
Looking at it from the other side, you'd have around a 55% chance of guessing sex from the percentage of the/a/an in random examples drawn from a population with equal numbers of males and females exhibiting these distributions of article-usage by sex.
And there are bigger differences due to genre and topic — the rate of the/a/an usage in formal written text will generally be much higher than in informal conversation, for example, and the expected magnitude of that difference is more than twice as great as the sex effect.
So this sex difference in article usage (like other perceptual and cognitive sex differences) doesn't provide any meaningful scientific support (in my opinion) for Dr. Leonard Sax's single-sex-education movement. On the other hand, differences of this magnitude can be quite important in some contexts. This much of an edge in investing or gambling, for example, would be a reliable source of income. Similarly, in politics or in marketing, effects of this size can be highly useful. (I don't mean that article-usage distributions per se are of any interest to investers, politicos, or marketeers; but other reliable effects of this size certainly would be.)
And a correlation of about 0.12 is right in the mix, for effects in published social-science research. Compared to the values in a recent meta-analysis (F.D. Richard, C.F. Bond, and J.J. Stokes-Zoota, "One hundred years of social psychology quantitatively described", Review of General Psychology, 2003), it's below the mean, but above the mode:
This article compiles results from a century of social psychological research, more than 25,000 studies of 8 million people. A large number of social psychological conclusions are listed alongside meta-analytic information about the magnitude and variability of the corresponding effects. References to 322 meta-analyses of social psychological phenomena are presented, as well as statistical effect-size summaries.
The distribution of r values that they found:
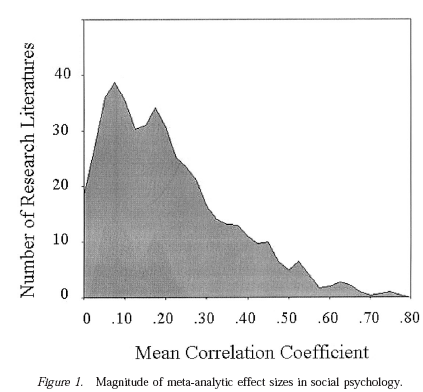
OK, on to the replication.
In order to show that this effect is reliable and easy to calculate, I took the transcripts and speaker demographics from the Fisher Corpus of conversational speech, a collection of more than 10,000 telephone conversations lasting up to 10 minutes each, recorded in 2003-2004 and published by the LDC.
In 9,789 conversational sides spoken by males, I found 9,409,848 words, of which 471,820 were the/a/an, for an overall percentage of 5.01%. In 13,007 conversational sides produced by females, there were 12,186,985 words spoken, including 554,827 articles, for an overall percentage of 4.55%.
These percentages are lower than in Newman et al.'s overall tabulation, as we expect given that this is informal conversation rather than written text.
What about the distribution of percentages across speakers? Here's a graphical representation of what I found (0.2%-wide bins from 0.1% to 10.1%):

And here's a table of the summary statistics
| Female mean (stddev) | Male mean (stddev) | Effect Size |
| 4.47 (1.16) | 4.89 (1.27) | d = -.34 |
Thus the effect is in the same direction, and the effect size is somewhat larger, consistent with Newman et al.'s observation that
Although these effects were largely consistent across different contexts, the pattern of variation suggests that gender differences are larger on tasks that place fewer constraints on language use.
The key thing is that this kind of analysis is now very easy to do. Starting from the raw Fisher-corpus transcripts and metadata files, writing and running the (gawk and R) scripts for this replication took me 17 minutes of wall clock time.
I haven't tried to persuade you that this effect is an interesting one, only that it's reliable (in the aggregate), comparable in size to many traditional social-psychological measures, and easy to compute. Though something might be learned by trying to figure out where this phenomenon comes from, it seems to me that it shouldn't be seen as an end in itself, but rather a feature that might help us understand other social and psychological differences.
There are hundreds of features that can now be calculated in similarly trivial ways. (And the resulting distributions show large age, class, and mood effects as well as sex effects, as Jamie Pennebaker and others have found — are there also effects of political philosophy, for example?)
As more and more text and speech become available, as better and more sophicated automatic analyzers are developed (such as those involved in "sentiment analysis"), and as the modeling of feature distributions in these larger datasets becomes more sophisticated, it's inevitable that the scope of such research will become broader, and the number of studies will increase.
I believe that the social value and intellectual interest of these studies will also increase — and I'll try to persuade you, in occasional future posts, that this is already happening.
[Update: D.O. in the comments asked about pronoun percentages. The numbers from Newman et al. are
| Female mean (stddev) | Male mean (stddev) | Effect Size |
| 14.24% (4.06) | 12.69% (4.63) | d = 0.36 |
I'm not sure that I've replicated their calculations exactly, because I'm not certain my list of pro-forms is the same as theirs. But for what it's worth, here's what I get for the Fisher data:
| Female mean (stddev) | Male mean (stddev) | Effect Size |
| 16.155% (2.352) | 15.496% (2.531) | d = 0.27 |
And here's the graphical version:

Again, the direction is the same, though there's an effect of genre that's larger than the effect of sex.]
Cosma said,
August 16, 2009 @ 2:03 pm
Am I missing something, or is it really the case that the accuracy of guessing sex by the articles (55%) is lower than the baseline accuracy of "always guess the more common sex" (58%)?
[(myl) I did the calculation assuming that we're trying to classify a sample from an a population where the numbers are equal, or at least where we don't know anything about what the proportions are. The point is that given the estimated distributions, the article-percentage that we find in an individual writing sample gives us some information about the author's sex, but not a lot. However, what I wrote was something else, and implied the calculation that you describe, which would indeed be a silly one. I'll fix it.
Alternatively, we could calculate how much better than 58% correct we could expect to do, given article-percentage information. But that's probably excessive nerdity in what's already an extremely nerdy post.]
D.O. said,
August 16, 2009 @ 3:38 pm
Prof. Liberman, can you explain the choice of the "detective marker" for sex as article. Pronouns have a larger effect according to Table 1 of the paper and they are easily countable.
Another point. When we use some marker for detective purposes, we have to be quite sure that there is a control for context. I know, you despise speculation, but if it's not to much, indulge me. Let's say we do not know whether a blog-post/twitter comment is a written text or a spoken word then article proportion of 5.5% will tell us that the person under investigation is more probably female, if it is written and more probably male if it is spoken (I took your data). Of course, we can use Bayesian approach for written/spoken spread, but the context can be guessed from the text itself. My question then is shouldn't we do it first?
[(myl) I didn't try replicating the pronoun finding since I'm not quite sure which forms were included in the overall pronoun counts. Once I find out, I'll try that too — it just takes a few minutes.
As for actually guessing the sex of an author, you'd want to use lots of features, including perhaps some hidden variables for genre and so on. My point here was just that there are some individual features that replicate pretty well, even if the effects are modest in size.]
Janice Huth Byer said,
August 16, 2009 @ 6:08 pm
At last, an objective explanation for the conventional slander we women talk more, despite research indicating men talk slightly more, as gauged by word count. This research suggests they merely make fewer points per word. Okay, I'm being reductive. I'll say no more…
Coby Lubliner said,
August 16, 2009 @ 11:56 pm
It strikes me as odd that a supposedly scientific study about "language use" deals only with English. Or should it?
Rick said,
August 17, 2009 @ 12:46 am
Ha! Latin has no articles and an abundance of pronominal forms. It really is the 'mother' tongue!
Graham said,
August 17, 2009 @ 6:26 am
If all we knew of Palin was that s/he was a professional politician, we could guess with 80% likelihood that she was male. (I suspect she is 80% blokey).
Genre effects presumably are led by topic: the standard discourses of, say, public policy would lean towards abstractions and impersonality, wouldn't they?
Faldone said,
August 17, 2009 @ 9:51 am
Her speeches could have been written by the First Dude. All in all I would say that examination of the pelvis or the skull would be a much better way of sexing an unknown person. I'd be willing to bet that even the femur is better than these language tests.
[(myl) The effect size for the sex/height relationship in adults is about 1.32, and femur length should be in proportion. The effect size for voice pitch is much larger, and would probably be the best single feature that doesn't require a physical examination.
But in any case, the point is not that this is a good way to determine sex — it isn't. The point is that there are lots of effects in text and speech that are subtle (and usually not noticed), but across large populations are as reproducible as typical social social measurement ever are.]
Helma said,
August 17, 2009 @ 2:31 pm
Readers may be interested in the latest issue of Digital Humanities Quarterly (http://digitalhumanities.org/dhq/index.html), with articles on gender distinctions in French literature (http://digitalhumanities.org/dhq/vol/3/2/000042.html) and gender, race and nationality in Black Drama (http://digitalhumanities.org/dhq/vol/3/2/000043.html). This followed on earlier work by Argamon and Kopel on gender of authors in the British National Corpus and by Argamon et al. on gender and the language of characters in Shakespeare.
I've experimented with this for Ancient Greek (characters in Greek drama). Pronouns showed distinctions; articles did not. But then, Greek doesn't have indefinite articles..