Affective demonstratives for everyone
« previous post | next post »
This is a follow-up to Mark's post earlier today on affective demonstratives, though I am going to move us even further than he did from Palin and towards the lexical/constructional pragmatics. The overall picture is this: this NOUN reliably signals that the speaker is in a heightened emotional state (or at least intends to convey that impression), whereas those NOUN sends quite a different signal. Our data are from upwards of 50,000 speakers.
Florian Schwarz and I have gathered distributional information from over 110,000 online product reviews from Amazon.com and Tripadvisor.com. Each of the reviews has associated with it a star rating, from one to five stars. As one might expect, the language in the extreme rating categories — one star and five star — is significantly more emotional than the language in the middle-of-the-road reviews. At the extreme ends, we find lots of exclamatives and expressives. Here, for example, is a picture of what a (what a hotel/dump/view/pleasure/disappointment) in the Tripadvisor data (it looks the same in Amazon):
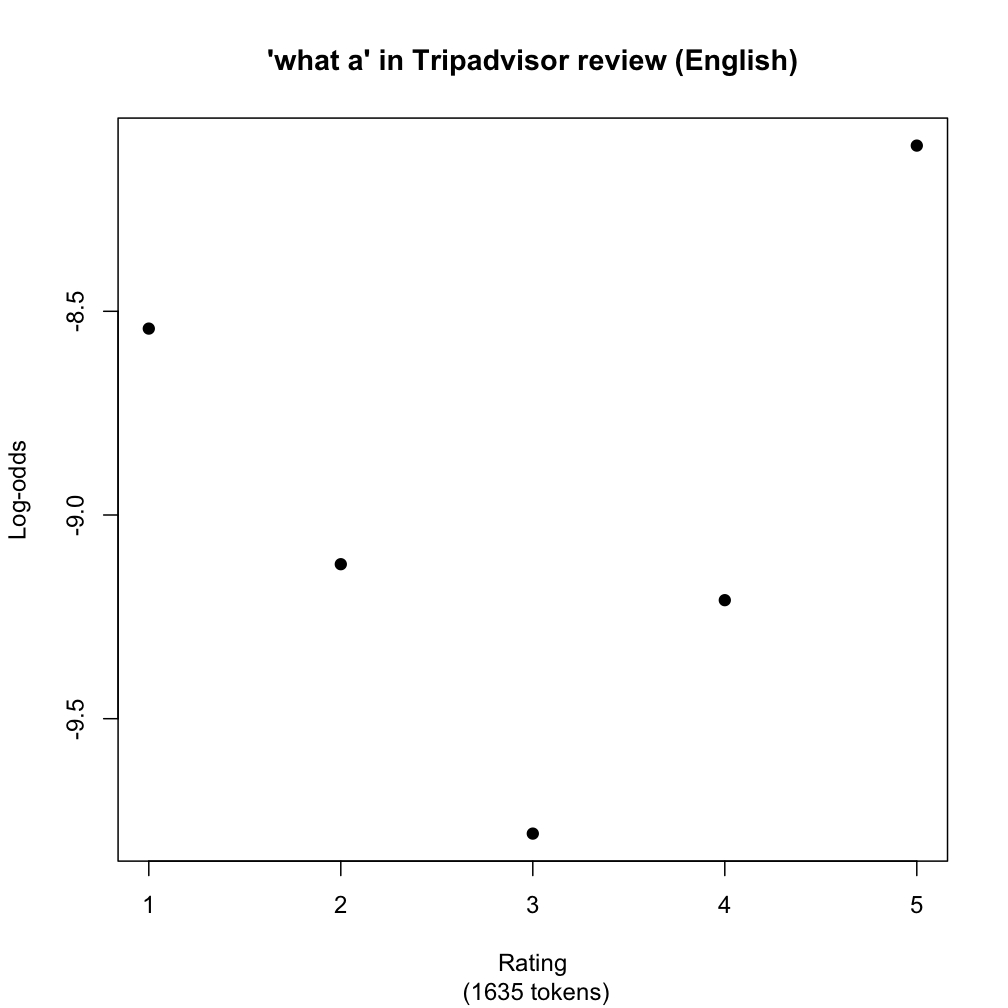
The rating categories are along the x-axis. The black dots give the distributional information, which is here given in terms of log-odds, so that we get a better picture of the relationships between these very small frequencies.
The noteworthy thing about this distribution is that it is U-shaped. The statistical models we build (which I touch on below) confirm this visual impression. Lots of lexical items have this 'heightened emotional' profile, with some showing biases for one extreme or the other. Basically, no one exclaims when writing balanced three-star reviews. They use such constructions when they loved it (five star) or hated it (one star).
Demonstratives sometimes show up on their own when we extract all the items with a particular shape from one of our corpora, but we'd never pursued the issue. Mark's post prompted me to probe a bit deeper.
Mark is careful to home in on the particular uses of this, that, these, and those that are of interest here, by looking just at those with nominal complements. Our data aren't tagged, but we can still get at these uses with reasonable accuracy. I pulled all the nominals from the tagged Brown corpus (21,429 elements), then gathered distributional information about occurrences of DEM NOUN in each of the five rating categories, where DEM is one of our demonstratives and NOUN is one of the nouns from the Brown corpus.
The picture for this NOUN is strikingly like the one for what a above. The following gives plots for both Amazon and Tripadvisor (click for a larger, more readable image):
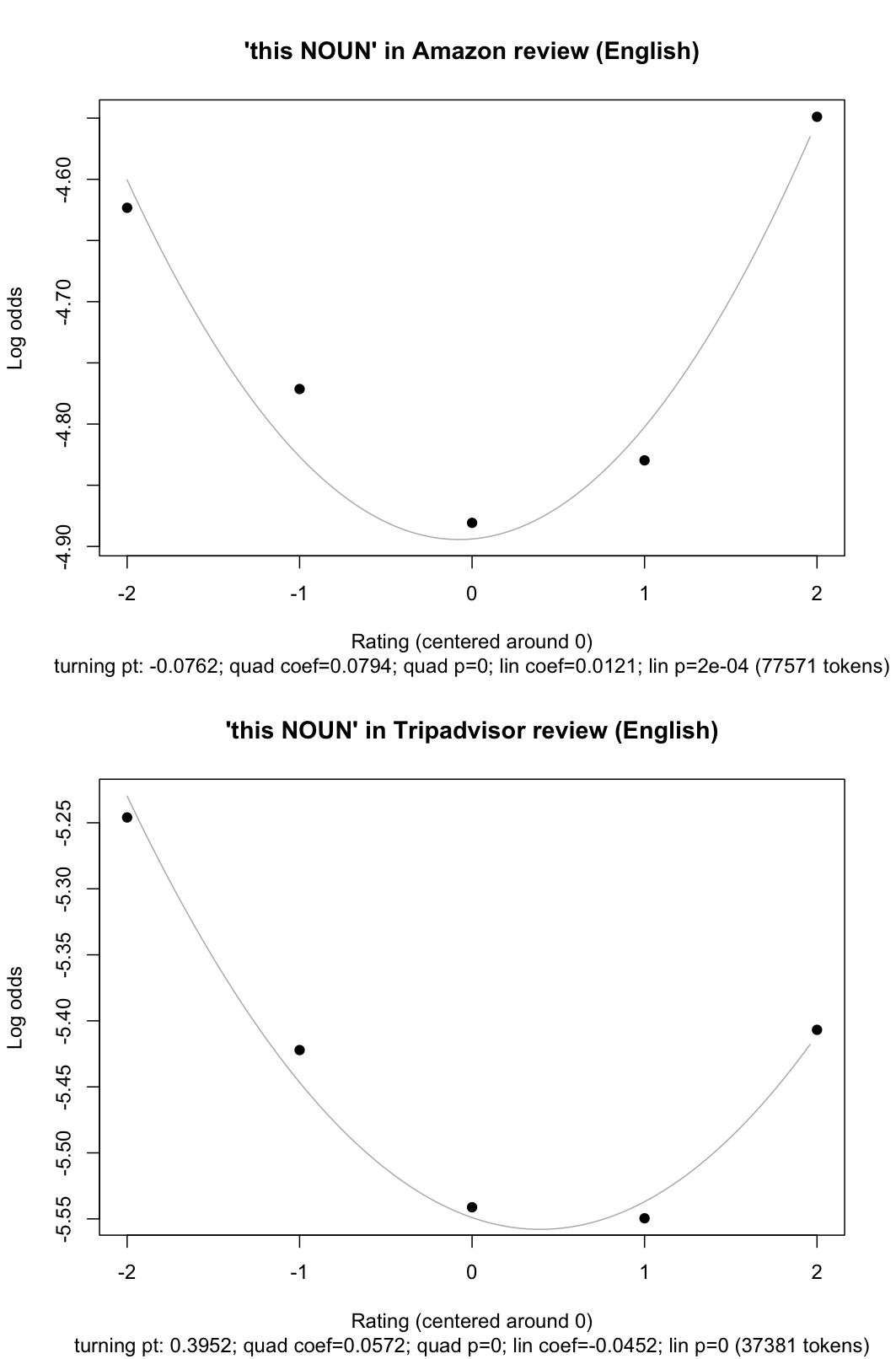
For this plot, the rating categories have been rescaled so that the middle point is 0. This is useful for detecting the nature of the curve. The plot also includes a quadratic regression line, along with some summary statistics from the logistic regression model involved. These numbers match well with the impression that the distribution is curved, with the uses confined mainly to the emotional reviews — without, though, a clear bias for positivitity or negativity.
Interestingly, those NOUN has a different profile: it is more like a Turned-U with a slight bias for positivity. The numbers are less clear for this case, but they are certainly suggestive:
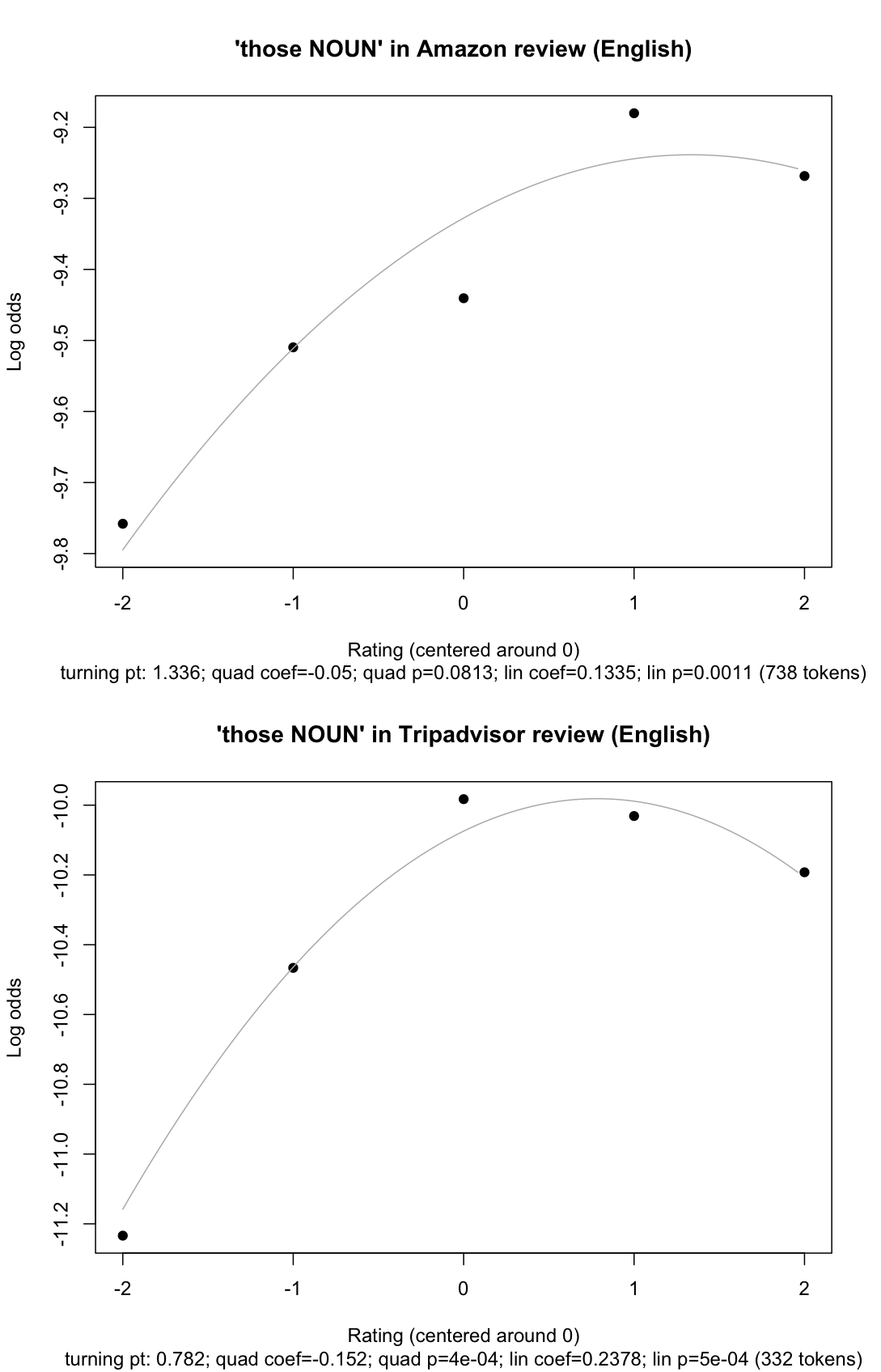
I tried to get similar data for that NP and those NP, but the shapes weren't consistent across our two largest data sets, so I think we need more refined methods for getting at the sort of uses we are interested in. (For instance, my method includes phrases that are part of examples like think that elephants are cute). I think the above suffices, though, to support Mark's contention that certain demonstrative constructions have an emotive component.
(I planned this as a Breakfast Experiment™, but I'm embarrassed to say that, even after pushing breakfast to mid-morning, I still couldn't get it posted at a Liberman pace.)
James C. said,
October 5, 2008 @ 4:47 pm
Perhaps you could use comments on IMDB as a source. Since their rating system uses ten stars rather than five your x-axis would be a bit more spread, and give you slightly less extrapolated curves. I’m sure there are other large websites offering user-supplied comments which use larger scale rating systems too, but IMDB is the first that came to mind.
Chris Potts said,
October 5, 2008 @ 6:45 pm
James C!
Many thanks for the suggestion to look at IMDB. Lillian Lee and her research group at Cornell have made some corpora available that are derived from IMBD, and we have used them in experiments on expressive content items like damn:
http://www.cs.cornell.edu/people/pabo/movie-review-data/
At present, we are also looking beyond English, to German, Chinese, and Japanese. I hope to post about this work in the near future.
Randy Alexander said,
October 5, 2008 @ 11:41 pm
Your difficulty in extracting suitable data should be a plea for corpus taggers to start tagging syntactic function (even by hand) and not just simply POS!
Claire said,
October 23, 2008 @ 1:52 am
Oh Chris Potts, it's okay! Not everyone can perform at Libermanian speeds.