Bad Science
« previous post | next post »
There's an article in the current issue of The Economist that you should read carefully: "Trouble at the lab", 10/19/2013. If you're a regular reader of Language Log, you'll be familiar with the issues that it raises — lack of replication, inappropriate use of "statistical significance" testing, data dredging, the "file drawer effect", inadequate documentation of experimental methods and data-analysis procedures, failure to publish raw data, the role of ambition and ideology, and so on.
But all the same, I'm going to push back. The problems in science, though serious, are nothing new. And the alternative approaches to understanding and changing the world, including journalism, are much worse. In fact, some of the worst problems in science are the direct result, in my opinion, of the poor quality of science journalism. One of the key reasons that leading scientific journals publish bad papers is that both the authors and the editors are looking for media buzz, and can usually count on the media to oblige.
The article leads with a quote from Daniel Kahneman's open letter on problems with replication in social priming research –"I see a train wreck looming" — and generalizes his apprehension to the scientific enterprise as a whole, especially to the biomedical area. There's a beautifully clear explanation of John Ioannidis's statistical argument that a large proportion of published research findings are likely to be false, summarized in this graphic (or see this animation):
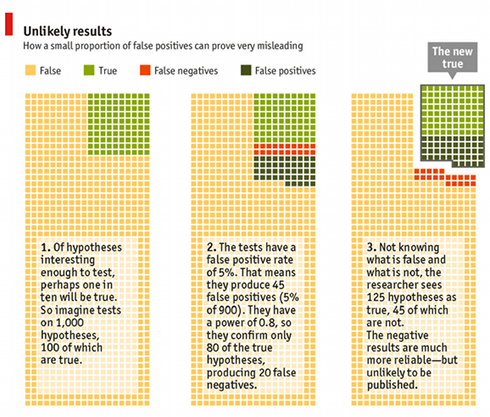
The article goes on to discuss inadequate "blinding" and the problem of confirmation bias in dataset creation, and the many opportunities that "Big Data" offers for researchers to fool themselves as well as others. There's an excellent discussion of the nature and status of replication in various sciences. And the article omits a few criticisms that cut even deeper, such as the demonstration that replicability is inversely correlated with impact factor.
Hanging over everything else in the article, there's an implicit threat of financial retaliation:
The governments of the OECD, a club of mostly rich countries, spent $59 billion on biomedical research in 2012, nearly double the figure in 2000. One of the justifications for this is that basic-science results provided by governments form the basis for private drug-development work. If companies cannot rely on academic research, that reasoning breaks down. When an official at America’s National Institutes of Health (NIH) reckons, despairingly, that researchers would find it hard to reproduce at least three-quarters of all published biomedical findings, the public part of the process seems to have failed.
But the private-sector part of the biomedical research enterprise suffers from all the same problems as the "public part of the process", perhaps to an even greater extent. And surely the appropriate way to evaluate public funding of research, biomedical and otherwise, is to look at its overall impact on a time scale of decades, not at the quality of individual research reports.
In the biomedical area specifically, $59 billion is only about 0.1% of the OECD's total 2012 GDP, whereas health care costs are running between 7% and 17% of OECD countires' GDP. The right question to ask about this research investment is not what proportion of published results can be replicated, but how much solid understanding and effective intervention emerges from the overall process. I'll leave it to others to make this judgment about biomedical research — but I'm confident that the much smaller public investment in areas that I know more about has been repaid many times over.
On the other hand, I agree that the poor quality of much published research is a problem worth trying to fix. My own opinion is that trying to tighten up on pre-publication review will make the problems worse, not better, and that the key to improvement is to focus on the things that happen after publication.
These include (informed) discussion, open examination of (obligatorily published) data and analysis code, attention paid to (non) replication efforts, and so on. All of this happens to some extent now — but it's comparatively starved of resources and attention. Most published studies now don't publish their experimental materials or or their raw data or the computer scripts that generate their cited numbers and tables and graphs, even when there's no serious impediment to doing so. Many important journals will not publish failures to replicate, apparently as a matter of principle, and give little or no serious attention to serious and expert objections to problematic published papers.
And researchers need to be reminded, early and often, of Feynman's observation that "The first principle is that you must not fool yourself", and of Hamming's warning that you should "beware of finding what you're looking for".
For those readers who would like to prolong their mood of righteous indignation, here's a small sample of previous LL posts on related topics:
"The secret sins of academics", 9/16/2004
"The apotheosis of bad science at the BBC", 5/27/2007
"Listening to Prozac, hearing effect sizes", 3/1/2008
"Winner's curse", 10/15/2008
"The business of newspapers is news", 9/10/2009
"The Happiness Gap is back is back is back is back", 9/20/2009
"We Need More Bad Science Writers", 6/7/2010
"'Vampirical' hypotheses", 4/28/2011
"Why most science news is false", 9/21/2012
"The open access hoax and other failures of peer review", 10/5/2013
"Annals of overgeneralization", 10/8/2013
Or see Geoff Pullum, "The Bad Science Reporting Effect", The Chronicle of Higher Education 3/15/2012.
peter said,
October 19, 2013 @ 9:04 am
Viewing the publication of experimental scientific results as transmission of messages through a noisy communications channel, Ionnidis uses standard (Neyman-Pearson) statistical hypothesis testing theory to estimate the expected noise levels in these messages. As he (and others before him) have noted, these noise levels are high, and, due to publication practices, higher than they need to be.
But these noise levels may have been even higher before the adoption of significance levels (and/or p-levels) became commonplace in scientific publishing. Indeed, before that adoption, such noise levels were not even readily estimatable. It should not be forgotten that whatever the failings of our current situation, we are in far better position than we were before (say) 1960.
The point here is that nothing about these practices is written on stone tablets by some God of Statistical Inference (something many non-statisticians seem to believe). Our current publication practices are just social conventions among scientists and journal editors, which have changed before and should do so again.
For reference to the problems in pharmacology before the adoption of Neyman-Pearson theory, see:
Irwin Bross (1971): "Critical levels, statistical language, and scientific inference". pp. 500-513 of V. Godambe and D. Sprott (Eds): Foundations of Statistical Inference. Toronto, Canada: Holt, Rinehart and Winston.
D.O. said,
October 19, 2013 @ 10:57 am
Well, of course if your prior of success is 0.1 things are 1) difficult and 2) require different p-levels.
bks said,
October 19, 2013 @ 11:00 am
The problem with publishing failures to replicate is that there are so bloody many ways to screw up an experiment.
–bks
Chris Waigl said,
October 19, 2013 @ 1:29 pm
This. Also, part of keeping things in perspective is to remind oneself that for example the International Congress on Peer Review and Biomedical Publication as well as most of the scientists quoted on the side of criticising blind trust in the reliability of scientific results are themselves part — usually well-established part — of the scientific community. And I have no doubt a lot of crap got published since the beginning of scientific journals, not only by our standards but also by those of the time, and that's actually ok with me to a degree if the scientific enterprise's job is seen to be also about figuring out what appropriate approaches *are* in the first place.
More problematic is the inclination of the general public, led by science media, to jump on every published result as if it was (highly likely to be) a true result. I much dislike this style of reporting: "Good morning everybody! On to our next topic, planetology! We've recently heard that the Moon might ACTUALLY be made of green cheese. Dr Whatsthename from the University of Somewhereorother is the author of a new paper in [prestigious journal] which found that most of the Moon's interior is made up by a highly elastic material which appears to be green in color. Dr Whatshisname's group used a new instrument called a super-orbital multiplexed hyperdihype spectrometer to derive their startling new results. We have to say that the planetary science community is still a bit sceptical, but here we have Dr Whatshisname on the line who can tell us all about this research…"
LinguaWatch said,
October 19, 2013 @ 1:53 pm
@bks: True, but publishing the failures that follow good research practice will be useful to understand the original study and its ability to account for the phenomenon under investigation. Not all failures should be published, just those that contribute to a better understanding of the research line. Admittedly, in some cases deciding which failures do contribute something important could be a judgment call, assuming that there isn't space to publish all the failures that follow good research practice. Journals or web sites devoted to replication studies would help; there have been calls for this type of publication recently.
the other Mark P said,
October 19, 2013 @ 2:14 pm
I agree that the real problem is not that journals publish material that is wrong, but rather that they are not interested in correcting errors.
That is largely because there is no money in correcting errors, and the system is set up by publishers to make money.
Colin Fine said,
October 20, 2013 @ 4:31 am
It's also the case that the Internet makes it easy for confirmation bias to be writ large.
I like to say (though I don't always observe) Never spread a story without checking it. But I sometimes add the rider Especially if you approve of it.
Daniel Barkalow said,
October 20, 2013 @ 3:07 pm
I think what would be really informative (and useful to the process) is a site where people who attempted to replicate studies would report their results, with somewhat less detail and fanfare than new papers, but in a way that contributes to the reputations (good or bad) of everyone involved. There's a ton of possible outcomes that could be found, from "this result is probably actually wrong", to "there are dependencies not discovered by the original research", to "the method is really hard to use", to "nobody in the field ever tried it again"; or from "couple of other labs replicated it", to "it is a reliable technique to base your experiments on", to "it's the basis for standard lab equipment". A lot of this information gets passed around in personal communication (i.e., scientists tell their friends that some system doesn't work, or has unexpected limitations, or that it is useful in their experience), but that doesn't get beyond point-to-point communication, and certainly not into the popular press.
[(myl) There's been some recent movement in this direction, e.g. here.]
J. W. Brewer said,
October 21, 2013 @ 3:36 pm
http://narrative.ly/pieces-of-mind/nick-brown-smelled-bull/ tells an interesting story (caveat: which I have not independently verified . . .) about how, among other things, a leading journal in a particular academic discipline was successfully convinced/pressured/guilt-tripped into publishing a piece debunking an oft-cited article the same journal had published some years earlier. "Oh, you say you have a deadline for responses to articles you've published and we're way past it? Don't you think it will be worse for your reputation if this debunking gets published by one of your rivals?"
Somewhere else, part 83 | Freakonometrics said,
October 21, 2013 @ 8:16 pm
[…] goes wrong" http://economist.com/news/leaders/… see also "Bad Science" http://languagelog.ldc.upenn.edu/7952 via http://srqm.tumblr.com/ […]
» The OutRamp Guide to Science and Technology: Episode #2 - The OutRamp said,
October 23, 2013 @ 8:05 am
[…] Bad Science […]