Stroke order inputting
« previous post | next post »
Michael Carr writes, "While examining an iPhone dictionary app (KanjiDicPro), I got a laugh from the attached "bǐshùn biānhào' 笔顺编号." [VHM: bǐshùn biānhào' 笔顺编号 means "stroke order serial/code number"]
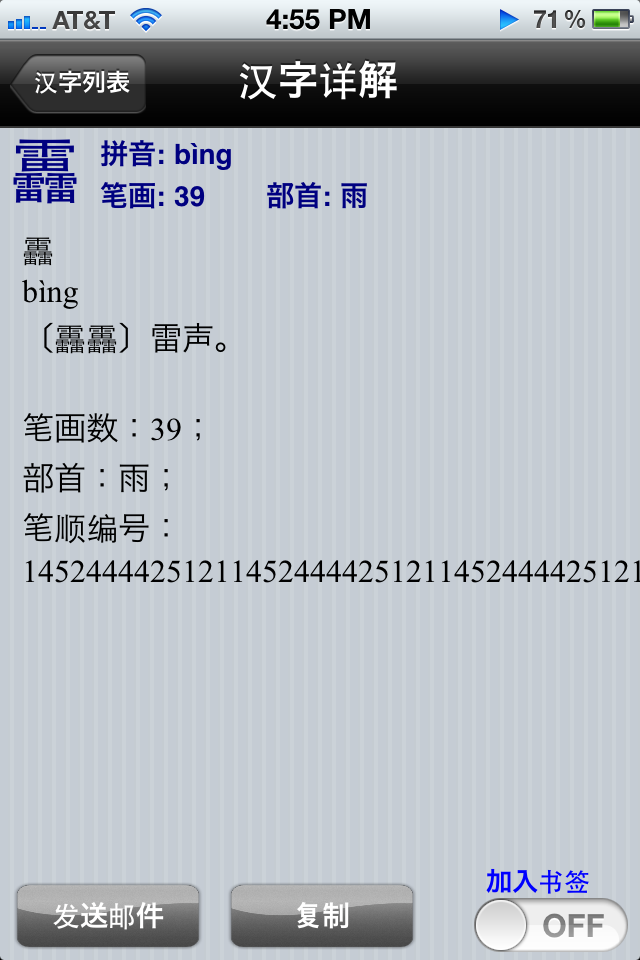
Before getting into the technicalities of how to input the character 靐, I had better explain how it is pronounced and what it means. Basically, bìng 靐 is an onomatopoetic word for the sound of thunder, and it normally occurs in the reduplicated form bìngbìng 靐靐 (somewhat comparable to "bang bang" or "bam bam"). So that means if you want to write this onomatopoetic expression for the sound of thunder, you'll have to squeeze 78 strokes into two small squares, no mean feat (not to mention that it takes quite a bit of time to do so)! Of course, not many people have the patience to write characters by hand any longer, especially not characters like 靐.
Admittedly, bìng 靐 is something of a monster. As you can see with your own eyes, squeezing 39 strokes into the same standard size space as for all other characters (e.g., hǎo 好 ["good"], huài 坏 ["bad"]) causes the density of the individual strokes to be so great that they inevitably blur together into a black blob. And yet bìng 靐 has lately become rather common on the internet.
The reason for the current popularity of bìng 靐 is that it is made up of three léi 雷 ("thunder") graphs. Now, one of the most fashionable of all internet locutions is léidǎole 雷倒了 or, with the passive signifier at the beginning, bèi léi dǎole 被雷倒了 ("bowled over; thunderstruck; astonished"), and léile 雷了 by itself can convey the same notion. (Grammar notes: dǎo 倒 is a resultative complement indicating that something or some person has fallen over; le 了 is a particle with many different functions [e.g., completed action, change of state — I think that in the expression léidǎole 雷倒了 it indicates change of state, though I fully expect to be challenged on this point]). Thus bìng 靐 is like léi 雷 to the third power: super thunderstruck / awestruck / astonished.
Given its current vogue, people need to know how to enter 靐 into their communication devices. Naturally, the simplest way is to call it up by the pronunciation written in pinyin, viz., bìng. However, if you don't happen to know the pronunciation of the graph, then you have to enter the character through its shape. Before explaining how that is done, I should observe that entering a character into an electronic communication or processing device is the reverse of looking it up in a dictionary; there is an inverse correlation between lookup and inputting.
For the last 1,900 or so years, the traditional way to classify characters has been by semantic keys, customarily called "radicals." From 1716 until the founding of the People's Republic of China, the standard number of radicals was 214, and every Sinologist worth his or her salt memorized them cold. (Much earlier, when there were far fewer characters, the number of radicals was ironically more than twice as great.) Since the simplification of characters under the PRC, there is no longer a standard set of radicals, and it seems that everybody and his brother comes up with a different set when they produce a new dictionary: 181, 186, 252, and so on and so forth.
Thus the system of radicals has descended into chaos, and this has led to an explosion of non-radical systems for looking up and entering characters. (The quest for a magic, easy way to classify characters had actually been going on long before the the founding of the PRC, but the demise of the standard set of 214 radicals during the last half-century has resulted in a wild profusion of frantic attempts to come up with something to replace the radicals.) Trying to find a user-friendly shape-based character lookup / entry system is like trying to invent a perpetual motion machine: it's a chimera that can lead the seeker down the path of mental illness. Perpetual motion machines do not exist because they would violate the first or second law of thermodynamics, or both. Easy shape-based Chinese dictionary lookup / entry systems do not exist because there are too many (potentially an infinite number, since the system is open-ended) characters composed of a severely restricted inventory of basic strokes (somewhere between 6 and 8, but usually no more than 10 — it all depends on how you count them — some people even claim that there are as many as 30 different strokes, but most of those beyond 10 are merely variants of the main few types); people argue endlessly over this aspect of the Chinese writing system too. The character yǒng 永 ("forever; everlasting; eternal; always; perpetual [!]) is supposed to embody all eight different types of strokes. How that is possible when 永 has only 5 strokes is a mystery of mysteries!
Moreover, determining which part of the character is the radical is often maddeningly ambiguous and devilishly difficult. One is reminded of the crie de coeur in David Moser's celebrated essay, "Why Chinese Is So Damn Hard," now available in a Chinese translation.
So there are countless ways to look up Chinese characters in dictionaries and to enter them in electronic communication devices, with new methods being invented all the time. The one we are concentrating on in this post is called the stroke order serial code / number method. The serial code for 靐 is 145244442512114524444251211452444425121, where the 1, 4, 5, and 2 respectively refer to the following types of strokes: héng 横 ("horizontal"), nà 捺 ("downward to the right"), zhé 折 ("turning"), and shù 竖 ("vertical"). These four types of strokes comprise all but one of the system, the fifth — number 3 — being piě 撇 ("downward to the left").
Right away we know that, although it superficially may seem simple (hey, guys, only five different types of strokes to worry about), this is going to be a troublesome system to learn. How do we know this? For one thing, since there are only five strokes in the system, these are not the normal repertoire of strokes one masters when learning the characters, which are usually around ten in number. This leads to some strange aspects of the system, such as that the second stroke of 靐 (the vertical stroke on the left side near the top) is classified as nà 捺 ("downward to the right"), the same as the four small strokes within the enclosure. This means that — in order to become proficient in this system — one is going to have to learn all sorts of special rules and exceptions; this is a failing of all shape-based entry / lookup systems for Chinese characters.
Finally, in order to use this particular stroke order serial code / number method (there obviously could be many other stroke order serial code / number methods, depending upon how many strokes one admitted into one's system and how one defined each of the strokes), one must scrupulously follow the exact stroke order or sequence specified by the system. If you do not, you simply will fail to find the character you are seeking. Yet, just as different Chinese people hold chopsticks in various idiosyncratic ways, so too do different Chinese people sequence the strokes of characters in various idiosyncratic ways, even though both for chopsticks and for stroke order, there is a supposedly correct way that everybody ought to follow, yet it is honored more in the breach than the observance.
Given the arbitrary nature of shape-based lookup / entry methods and the heavy demands they place upon memorization, it is no wonder that the vast majority of individuals prefer phonetic lookup / entry methods.
Arjun said,
October 30, 2011 @ 6:28 pm
If there are 10 strokes in the standard taxonomy, why does the system restrict itself to only 5? There are also 10 buttons on the standard phone keyboard, it seems awfully strange to waste that serendipity.
Chinese Inputter said,
October 30, 2011 @ 7:37 pm
There is a not-particularly-well documented aspect of character entry on OS X called 拆白 (ChaiBai), which is well-suited to this type of composed character. Here is an overview: http://jimsheng.hubpages.com/hub/Chaibai-Chinese-input-method-editors .
To reproduce 靐, once can type "lei lei lei", with either simplified or traditional chinese pinyin input enabled, and then press shift+space in order to compose the character. This is a sort of middle ground between phonetic and stroke-based entry methods, and the one that actually seems to make the most sense here. Typing only "bing", on a mac at least, would require the user to scroll down to the 8th line of potential candidate completions.
Adrian Morgan said,
October 30, 2011 @ 8:16 pm
Regarding the input of Chinese characters on electronic devices, I dimly remember watching a television report, back in the late eighties probably (early nineties possibly), to the effect that such a system had recently been invented. That is, a system where you select characters via a sort of multilevel menu system organised by the strokes that the characters contain.
Given that the earliest such methods were invented prior to the relevant timeframe, it's not plausible that I saw the the ancestor of all shape-based electronic input methods. But it was presented as some kind of revolutionary innovation, otherwise it wouldn't have been on television. Any thoughts on what I probably did see?
Chinese Inputter said,
October 30, 2011 @ 8:38 pm
As indicated here: http://www.yellowbridge.com/chinese/charsearch.php?searchChinese=1&zi=靐 , you can type the character with MWMWW for Cangjie input, or even better FLFL in WuBiZiXing. Wubi is designed to keep the number of keystrokes fewer than four, in fact, and therefore you only type the first three required for a character followed by the final stroke. I am unaware of any system which requires you to input all of the strokes of a character. Sure, they can occasionally require idiosyncratic rules, but at least for Wubi here this is straightforward: 雨 + 田 + 雨 + 田 .
mondain said,
October 31, 2011 @ 2:34 am
The stroke order system is defined by the GB standard (GF3003-1999 GB13000.1), which lists the stroke order for 20902 characters. 靐 is the last but one on the list (No. 20901, on p. 725).
Leonardo Boiko said,
October 31, 2011 @ 5:05 am
The reason that yǒng has only 5 strokes but exemplify 8 strokes is that the word “stroke” here means different things (as I think Victor’s text imply). In the five-count a “stroke” means a mark you make without lifting the writing implement; this is the definition that matters for stroke count (useful for dictionaries) and stroke order (useful to learn cursive).
The 8-count refers to a smaller subdivision of “strokes”: each individual gesture one needs to make with a brush to create the standard geometric shape in regular kǎishū 楷書 style. 乙 has only one stroke on the former sense, but 4 in the latter. …Well, or not. The thing is, basically each treatise or theory of calligraphy counts these strokes differently. Do folds (turns of line) count as strokes or not? What about curved distinctions, like the short and long ticks (wān/piě, duǎn piě) in 永? Some would count 乙 as a single “hook” after all, or as an horizontal line and a hook, or horizontal, hook, and jump. In any case, even if you take the 永 scheme seriously, it’s very clear that its 8 calligraphy-strokes don’t cover them all (what about e.g. the diagonal line 式 or the fold in 口)? The reason 永 is (was) popular is that it’s a great first exercise in calligraphy, to get one’s hand used to the gestures.
Besides all the traditional calligraphy stuff, Unicode also has its own set of CJK strokes . The holy grail of CJK text processing would be being able to compose and decompose arbitrary Chinese characters at will; there’s been some interesting attempts, but so far nothing stuck.
Bob Violence said,
October 31, 2011 @ 5:56 am
@Arjun: If there are 10 strokes in the standard taxonomy, why does the system restrict itself to only 5? There are also 10 buttons on the standard phone keyboard, it seems awfully strange to waste that serendipity.
The Q9 method uses nine keys, but it's patented. The five-stroke system might just be a way of avoiding possible infringement, since Qcode can't lay any claim to it.
@Adrian Morgan: Any thoughts on what I probably did see?
Maybe something like the pop-up menus of modern Chinese input systems, which provide a list of possible characters as the user inputs strokes (or phonetic symbols, in the case of pinyin- and zhuyin-based systems). I don't know when this idea was first implemented, although shape-based systems generally date back to at least the 1970s.
Bob Violence said,
October 31, 2011 @ 6:04 am
I should add that, in the case of phonetic methods and simpler shape-based methods, a disambiguation menu of the sort I mentioned before is essential, since there is no one-to-one mapping between (most) Mandarin syllables and a single character, or between a single character and a specific stroke/shape sequence. (Cangjie does have a one-to-one correspondence, although it "cheats" somewhat by including a key specifically for disambiguation.) So the development of such tools was necessary for the now-dominant phonetic input methods.
Keith said,
October 31, 2011 @ 12:52 pm
Fascinating. I've long been interested in Chinese characters and input methods, though never enough to set aside enough time to learn more about them.
Since "one of the most fashionable of all internet locutions", is 被雷倒了 (bèi léi dǎole), I wonder if this is the Chinese equivalent of ROFL?
If so, would that then make 被靐倒了 (bèi bìng dǎole) the equivalent of ROFLMAO?
K.
Victor Mair said,
October 31, 2011 @ 1:17 pm
@Bob Violence "…a disambiguation menu of the sort I mentioned before is essential, since there is no one-to-one mapping between (most) Mandarin syllables and a single character…."
Most pinyin inputting is now done by word, not syllable (i.e., single character), so disambiguation is usually not necessary.
Bob Violence said,
November 1, 2011 @ 4:41 am
But without having any personal experience with them, I would imagine that whatever phonetic input methods available at the time Adrian Morgan refers to were rather less adept at predictive/contextual input. The Microsoft IME included with my copy of Windows XP requires enough babysitting as it is, and that's only about ten years old. In any case manual disambiguation is still a requirement for things like proper names of "non-notable" people and places (and even for some that are).