Innate sex differences: science and public opinion
« previous post | next post »
Yesterday ("Sexual pseudoscience from CNN", 6/19/2008), I promised to follow up with a discussion of Jennifer Connellan et al., "Sex Differences in Human Neonatal Social Perception", Infant Behavior & Development, 23:113-18, 2000. This post fulfills that promise. But first, I want to say something about the appropriate role of such studies in influencing public opinion and forming public policy.
Scientists mostly understand the dangers of overinterpretation and the importance of replication and triangulation. The public mostly doesn't. Unfortunately, journalists and editors also mostly don't understand these issues — or at least they act as if they don't. As a result, the role of science in the marketplace of opinion is seriously degraded by popular prejudice and by lobbyists for various commercial and ideological interests. I hope that this post, aside from any intrinsic interest that the content may have, will provide some material for discussion of those points.
Yesterday's context was a story by Paula Spencer ("Is it harder to raise boys or girls?", CNN.com/health, 6/17/2008) that spreads some false or misleading claims about sex differences in hearing and vision taken from Dr. Leonard Sax's book Why Gender Matters. Spencer also follows Sax in connecting those differences in hearing and vision to sex differences in speech, language, non-verbal communication, and other things.
I linked to posts questioning Sax's claims about hearing, vision, and connections between emotions and language. And I added a discussion of a meta-analysis of "facial expression processing" (FEP) that Dr. Sax cites as showing that "Most girls and women interpret facial expressions better than most boys and men can".
That paper (Erin McClure, "A Meta-Analytic Review of Sex Differences in Facial Expression Processing and Their Development in Infants, Children, and Adolescents", Psychological Bulletin 126:424-53, 2000) combined information from dozens of studies to produce an estimated effect size of between 0.13 and 0.16 for FEP in children and adolescents, meaning that about 53 or 54 percent of girls are likely to perform above average on a given test of FEP, compared to 46 or 47 percent of boys.
I've often emphasized the importance of looking at effect size — the difference between group means expressed as a proportion of a measure of within-group variation — and its implications for statements about general properties of groups. Over and over again, we find journalists (and even some scientists) describing small effect sizes of 0.10 to 0.20 with statements like "Xs are better at Foo than Ys are", although the real prediction is only that on a test of Foo, if you pick a random X and a random Y, the X will score better than the Y.(say) 53 times out of 100, but lower than the Y 47 times out of 100.
(I imagine that journalists dislike dealing with effect sizes because the concepts don't fit our language and our natural patterns of thought very well, and perhaps also because they often spoil a catchy story line by turning black and white into shades of gray. Non-journalist partisans of simple answers — pharmaceutical peddlers, for example — often have a more directly financial interest in getting people to take the step from a small difference in group averages to a generic difference in group qualities. Promoters of ideological remedies, like Dr. Leonard Sax, may have an analogous interest in avoiding the question of effect sizes. He's a lobbyist for single-sex education, and his arguments depend on the premise that (nearly all) boys are perceptually, cognitively and emotionally different from (nearly all) girls.)
Something that I don't emphasize enough is that scientists' estimates of effect size are themselves just estimates, and tend to vary a great deal across published studies. There are many reasons for this. Sampling error is one reason, but it's probably not the most important one. Source of non-sampling error include atypical subject populations, differences in test instruments, different modes of test administration, differences in scoring, and so on.
Let's consider just two of these, starting with differences in experimenter judgment in making measurements. The raw numbers in scientific studies, even when they come from experts viewing the output of sophisticated and expensive pieces of apparatus, are sometimes a great deal more subjective than people realize.
A couple of days ago, I mentioned that a recent paper on sexual orientation and brain anatomy (Ivanka Savic and Per Lindström, "PET and MRI show differences in cerebral asymmetry and functional connectivity between homo- and heterosexual subjects", PNAS, 6/16/2008) found that "The inter-rater correlations was [sic] 0.85 … for cerebral hemispheres", meaning that when two different experimenters measured the volume of several subjects' cerebral hemispheres from the same MRI data set, the correlation between the two experimenters' numbers was r=0.85. This is really a pretty marginal level of agreement. The authors don't provide their raw numbers (as in my opinion everyone should, these days), but here's a set of 15 pairs of synthetic (random) measurements of cerebral hemisphere volumes in cc, crafted to have a range of values similar to those cited in the experiment, and an inter-rater correlation of 0.85:
| Rater 1 | 529 | 534 | 536 | 559 | 560 | 580 | 580 | 604 | 610 | 612 | 617 | 630 | 640 | 663 | 678 |
| Rater 2 | 469 | 488 | 525 | 580 | 609 | 514 | 642 | 669 | 640 | 635 | 640 | 658 | 691 | 621 | 776 |
Keep in mind that the key outcome of this study was a relative difference in cerebral hemisphere size of about 12 cc for heterosexual males and about 5 cc for homosexual women.
This level of measurement noise doesn't invalidate the study, but it does mean that different experiments with fairly small N (in this study N was 20 to 25 per group) may give a range of quite different estimates of effect size.
For an example of a small difference in experimental instructions that interacts in a big way with subgroup performance, look at the discussion of Ventry et al., "Most Comfortable Loudness for Pure Tones, Noise, and Speech", Journal of the Acoustical Society of America, 49(6B), 1971 in one of my earlier posts on sex differences in hearing. This experiment asked subjects to adjust the volume of radio broadcasts to their most comfortable listening level. The instructions were given in two versions, differing only in whether some clauses were added emphasizing the importance of understanding the broadcasts' content. Thus the instructions began like this (with or without the boldface clauses):
The purpose of the next test is to find and maintain a loudness level at which speech is most comfortable to listen to [and where you can easily understand everything that is being said]. This switch enables you to make the speech louder or softer. Using this switch, your task is to make the speech louder or softer until you reach a level which you feel is your most comfortable listening level [at which you can easily understand everything that is being said]. When you reach this level continue to make speech louder or softer, maintaining the speech at your most comfortable listening level for as long as you hear the broadcast.
This small change in instructions completely reversed the sex difference in "most comfortable loudness" (MCL). Without the instruction to pay attention, the females' MCL was 10.8 dB lower than the males' (effect size -0.81) — but with the instruction, it was 9.7 dB higher (effect size 0.85):
| WITH | WITHOUT | |
| Male | 47.9 (10.1) | 50.4 (13.1) |
| Female | 57.6 (12.5) | 41.2 (9.4) |
(There were 16 subjects in each cell; 64 subjects overall in this part of the study.)
As a result of many factors of this kind, it's normal to see not only a great deal of variation among subjects, but also a great deal of variation among studies. That's why it's valuable to do meta-analyses, like Erin McClure's meta-analysis of FEP. And here's her Figure 5, showing effect sizes across studies as a function of age:
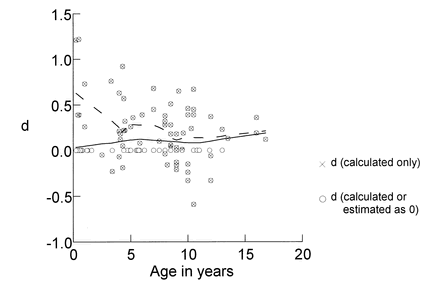
Scatterplot of unweighted effect sizes by age with LOWESS regression lines. (The dotted regression line is for calculable effect sizes only; the solid regression line is for the larger sample of calculable effect sizes and those estimated as 0.) LOWESS is a smoothing method that summarizes the middle of the distribution of y for each value of x.
I should mention, at this point, something that McClure also discusses — the bias that may be introduced by the general tendency of scientists (and journal editors) not to publish studies that show no effect, or that show an effect that "makes no sense" (which may just mean that it goes against current scientific opinion). As a result, a paper that shows a plausible but weak effect is much more likely to see the light of day than one that shows no effect, or one that shows a weak effect that seems implausible.
This was a major issue in the discussion of the Kirsch et al. meta-analysis of the effectiveness of anti-depressant drugs ("Listening to Prozac, hearing effect sizes", 3/1/2008), where the study's authors had to use a Freedom of Information Act request pry loose the results of "all clinical trials submitted to the US Food and Drug Administration (FDA) for the licensing of the four new-generation antidepressants for which full datasets were available" (fluoxetine, venlafaxine, nefazodone, and paroxetine). Significant parts of these datasets had not previously been published, apparently because they were studies that found no effect and were thus perceived as uninteresting or faulty. Because of federal regulations, the results of (some of?) these unpublished studies were nevertheless deposited with the FDA, and eventually unearthed by Kirsch. In most subfields of science, the null, negative or unexpected experiments are mostly just buried forever. (And this is arguably often the right thing to do — but it definitely introduces a bias into the literature, one that good scientists at least implicitly factor into their evaluation of the reliability of conclusions.)
OK, onward to Jennifer Connellan, Simon Baron-Cohen, Sally Wheelwright, Anna Batki, and Jag Ahluwalia, "Sex Differences in Human Neonatal Social Perception", Infant Behavior & Development, 23:113-18, 2000 (free version here).
In the 6/17/2008 CNN/health article, Paula Spencer wrote:
From birth, a girl baby tends to be more interested in looking at colors and textures, like those on the human face, while a boy baby is drawn more to movement, like a whirling mobile, says Dr. Sax.
This echoes a passage on pp. 18-19 of Leonard Sax's Why Gender Matters:
Researchers at Cambridge University wondered whether female superiority at understanding facial expressions was innate or whether it developed as a result of social factors such as parents encouraging girls to interact with other girls while the boys shoot each other with ray guns. These researchers decided to study newborn babies on the day they were born.
Their plan was to give babies a choice between looking at a simple dangling mobile or at a young woman's face […] The boy babies were much more interested in the mobile than in the young woman's face. The girl babies were more likely to look at the face. The differences were large: the boys were more than twice as likely to prefer the mobile.
Here's Table 2 from the Connellan et al. paper: "Mean percent looking times (and standard deviation) for each stimulus"
| Face | Mobile | |
| Males (n = 44) |
45.6 (23.5) | 51.9 (23.3) |
| Females (n = 58) |
49.4 (20.8) | 40.6 (25.0) |
The girls spent 3.8% more of their time looking at the faces than the boys did (an effect size of 0.17), while the boys spent 11.3% more of their time looking at the mobile than the girls did (an effect size of 0.47).
Another way to describe these results would be to say "Boys on average were slightly more interested in the mobile than in the face (51.9% of their looking time vs. 45.6% of their looking time), whereas girls on average were slightly more interested in the face than the mobile (49.4% of their looking time vs. 40.6% of their looking time). The differences in average looking time between the sexes were between 1/6 and 1/2 of the within-sex standard deviations."
The biggest (proportional) sex difference in the study, actually, was a sex difference in the drop-out rate:
102 neonates (58 female, 44 male) completed testing, drawn from a larger sample of 154 randomly selected neonates on the maternity wards at the Rosie Maternity Hospital, Cambridge. 51 additional subjects did not complete testing due to extended crying, falling asleep, or fussiness, so their data were not used. The mean age of the final sample tested was x = 36.7 hrs (sd = 26.03).
Thus 33 boys (= 77-44) vs. 19 girls (= 77-58) "did not complete testing due to extended crying, falling asleep, or fussiness. This is 74% more boys than girls (33/19 = 1.74). I believe that this pattern is typical of infant research, and it always raises the question of whether it contributes to a bias of some sort, since we don't know whether failure to complete the test is independent of the qualities being tested. One issue that occurred to me is the question of how many of the boy babies might have undergone circumcision before being tested. The rate of infant circumcision in the U.K. is generally fairly low these days, but the authors don't tell us what proportion of the male infants might have been circumcized during the period (average 37 hours) between birth and testing.
Let's note next that Spencer's contrast ("From birth, a girl baby tends to be more interested in looking at colors and textures, like those on the human face, while a boy baby is drawn more to movement, like a whirling mobile") was explicitly not explored in this study, since
The mobile was carefully matched with the face stimulus for 5 factors: (a) Color (‘skin color’). (b) Size and (c) Shape (a ball was used). (d) Contrast (using facial features pasted onto the ball in a scrambled but symmetrical arrangement, following previous studies (Johnson & Morton, 1991)). (e) Dimensionality (to control for a nose-like structure, a 3cm string was attached to the center of the ball, at the end of which was a smaller ball, also matched for ‘skin color’).
As a result, in fact, the "mobile" was pretty weird-looking (click on the image for a larger version):
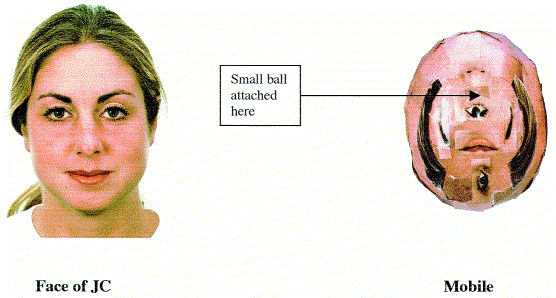
(After seeing this picture, I'm inclined, only half jokingly, to re-interpret the experiment as showing that "Boy babies are innately somewhat more interested in transdimensional monsters than girl babies are".)
And finally, let's note that
The videotapes were coded by two judges … to calculate the number of seconds the infants looked at each stimulus. A second [third? -myl] observer (independent of the first pair and also blind to the infants’ sex) was trained to use the same coding technique for 20 randomly selected infants to establish reliability. Agreement, measured as the Pearson correlation between observers’ recorded looking times for both conditions, was 0.85.
See above for what inter-rater correlation of 0.85 means…
OK, so how did Leonard Sax interpret results like these
| Face | Mobile | |
| Males (n = 44) |
45.6 (23.5) | 51.9 (23.3) |
| Females (n = 58) |
49.4 (20.8) | 40.6 (25.0) |
as justifying the statement that
The differences were large: the boys were more than twice as likely to prefer the mobile.
Well, Connellan et al. — perhaps recognizing that the data on looking times are underwhelming — found another way to present the results which emphasizes the sex difference:
For each baby, a difference score was calculated by subtracting the percent of time spent looking at the mobile from the percent of time they spent looking at the face. Each baby was classified as having a preference for (a) the face (difference score of +20 or higher), (b) the mobile (difference score of –20 or less), or (c) no preference (difference score of between –20 and +20).
| Face preference | Mobile preference | No preference | |
| Males(n=44) | 11 (25.0%) | 19 (43.2%) | 14 (31.8%) |
| Females(n = 58) | 21 (36.2%) | 10 (17.2%) | 27 (46.6%) |
This is a reasonable approach to the data, in my opinion, but it should be recognized for what it is, namely an effort to emphasize a difference that does not seem different enough in the more straightforward presentation of looking-time proportions. (And I'll again emphasize that the Right Thing to Do is to publish all the raw data — in this case, the table of face time, mobile time, and "other" time for all 102 subjects.)
Quoting the paper:
Examining the cells that contribute most to the chi-square result suggests that the significant result is due to more of the male babies, and fewer of the female babies, having a preference for the mobile than would be predicted. In other words, male babies tend to prefer the mobile, whereas female babies either have no preference or prefer the real face.
In sum, there are certainly differences in the behavior of the male and female babies in this experiment. The biggest difference was that almost twice as many boys as girls were too fussy or sleepy to be tested. The second-biggest difference was that more of the boy babies were more interested in the "mobile", a surpassingly weird object in which various facial features were pasted on a face-sized ball in a scrambled way, with a second and smaller ball attached by string in a nose-like location.
This experiment certainly seems to tell us something about sex-linked behavioral, perceptual, and (perhaps) cognitive differences in neonates. It may tell us something about sex differences in interest in faces, but maybe not — it seems to tell us more about sex differences in fussiness and sleepiness, and sex differences in interest in weirdly scrambled face-like stimuli. If you wanted to be difficult, you could argue that it really shows that the boy babies have learned more quickly what faces are supposed to look like, and are therefore more concerned to try to sort out what's going on with that strange face-like thing with an eye in its chin and its nose on a string.
Mark P said,
June 20, 2008 @ 9:18 am
I'm not sure where this experiment and its treatment fall in the argument within the sciences about how to get the public to understand science. I think it ends up being a good example of a study that could have remained sequestered in the scientific journal in which it was originally published, there to await either further explication, or perhaps to be forgotten. If the results of the public treatment of this story are that some mothers blame their children's behavior at the playground on nonexistent sex differences, I suppose there is no harm done. The real danger comes from the way scientists and general media handle stories that result in decisions about important public policy.
gyokusai said,
June 20, 2008 @ 9:30 am
Why Gender Matters seems to be about as accurate and meticulously researched as, say,
Men Are from Mars, Women Are from Venus, Why Men Don’t Listen and Women Can’t Read Maps, and similar anecdotal nonsense aiming at stimulating preconceptions in much the same way as astrology does.
At the risk of coming across as a fanboy, your article is so refreshing and refreshingly scientific.
^_^J.
Mark Liberman said,
June 20, 2008 @ 9:31 am
Mark P: I'm not sure where this experiment and its treatment fall in the argument within the sciences about how to get the public to understand science.
IMHO, it's a fine experiment, worth reading and learning from. It's problematic as a significant part of an argument that innate sex differences require single-sex education.
Perhaps I've just re-stated what you said.
Nathan said,
June 20, 2008 @ 3:24 pm
Well, I know it's only one data point, but I was always more interested in transdimensional monsters than my three sisters.
I stared at that mobile graphic for a long time!
Oh, and I'm circumcised. HTH.
Sili said,
June 20, 2008 @ 5:26 pm
Thank you for an ever clear digestion of the vapid news. I think you should be a shoo-in for the award from the RSS now that they've given Ben Goldacre one (I should look into how to make nominations …).
He too, by the way, advocates more transparency in trials with human subjects re the antidepressant study, but you prolly know that already. I can only support the recommendation of making original data more readily available. There really is no excuse in this age of unlimited storage (instead of dead trees). I made sure to add the original datasets back when I regularly submitted crystal structures to the CCDC.
And now for something completely off-topic. Phil Plait posted an aural illusion that seems to apply some of the same tricks as vetriloquists, but I'd love to see a phonological treatment. Another little crash course in how to read sonograms together with a primer on phonetics. Though I guess that's a bit much to ask.
CBK said,
June 20, 2008 @ 6:03 pm
"[T]he bias that may be introduced by the general tendency of scientists (and journal editors) not to publish studies that show no effect" is known in some circles as the "file drawer effect" or "file drawer problem." See, e.g., Caplan and Caplan's chapter "The Perseverative Search for Sex Differences in Mathematics Ability" in Gender Differences in Mathematics, Gallagher & Kaufman (Eds.), Cambridge, 2005.
The file drawer effect has received a little bit of discussion in popular media in the context of clinical trials:
Filed under F (for forgotten), USA TODAY, 5/16/01
Antidepressants: Beware the File-Drawer Effect, Newsweek blog, 1/16/08
Many unfavorable drug studies aren’t published, Reuters, 1/16/08
and in Science
The Old File-Drawer Problem, Don Kennedy, Science 23 July 2004:
Vol. 305. no. 5683, p. 451
Bob Ladd said,
June 21, 2008 @ 2:20 am
Um, if "102 neonates … completed testing, drawn from a larger sample of 154 randomly selected neonates…" and "51 additional subjects did not complete testing …", what happened to that last baby?
Mark Liberman said,
June 21, 2008 @ 6:30 am
Bob Ladd asks how to get 154 by adding 102 and 51. I wondered that myself.
I guess the last kid is still trying…
B.W. said,
June 23, 2008 @ 6:37 pm
I personally don't trust the kind of studies where the experimenter interacts directly with the baby. I don't think there are many people (maybe only trained actors) who can control their facial muscles perfectly. A small difference in the way the experimenter looks at the baby (from a distance of 20 cm!) will make a huge difference in the way the baby responds, even in neonates. And the article doesn't say that JC was unaware of the babies' sex, only that the raters (who only saw the video of babies' responses) were blind to the babies' sex. I realise that this is the standard way of doing these studies, but this is the reason why I don't believe any results coming out of this kind of research. In this particular study, they could have easily used a photograph of a face vs. a scrambled photograph, and if they absolutely wanted a round stimulus, they could have pasted the pictures on balls.
I have seen videos presented at conferences where looking-time effects from infant research were presented – it was sometimes immediately obvious that there was a slightly longer pause between the previous stimulus and the 'target' or that the experimenter tensed slightly (upper body and neck muscles) – no wonder that the infants would look longer at the next stimulus, wondering what the adult was reacting to. As long as these researchers are unable to properly control their experiments, I cannot take their results seriously, it's simply not science.
not feeling very nonymous said,
June 24, 2008 @ 7:01 am
"Boy babies are innately somewhat more interested in transdimensional monsters than girl babies are": this has a simple evolutionary explanation. All the literature agrees that transdimensional monsters are much more likely to let some females survive than males (cf. http://lolthulhu.com/2007/10/18/i-can-has-cheezkake/), so it makes sense that males are at least somewhat more primed to be on the lookout for TDMs. The theory of human biodiversity predicts that this difference should be larger in populations with a long evolutionary history near the Plateau of Leng.
Ken Brown said,
June 24, 2008 @ 12:58 pm
Girls, on the other tentacle, are evolved to be more wary of giant and/or talking apes.
Jennifer Connellan said,
March 25, 2009 @ 2:22 pm
I thoroughly enjoyed this analysis of our study, and even laughed out loud at the description of the 'transdimensional monster'. While conducting the research with the mobile, we preferred to call it the 'alien'. But transdimensional monster works just as well, if not better. Looking back, I think our greatest accomplishment was convincing 154 new parents to allow us to expose their little babies to the alien / transdimensional monster!
Gary said,
April 10, 2009 @ 2:23 am
WRT Table 1 in the Connellan et al (2001) study — babies were categorized into 3 groups based on the +/-20% criterion. This results in a significant chi-square. However, if a stricter criterion was used instead, where babies were classified as having either a face- or "monster"-preference, the data would have been non-significant. Specifically, if we assume the no-preference groups (14 boys and 27 girls) were evenly split in terms of their looking times to faces vs. monsters, then the chi-square is 3.46, nonsig with df=1.