American Passivity
« previous post | next post »
This is an illustrative Breakfast Experiment™ for my course at the LSA Institute (on "Corpus-Based Linguistic Research"). It starts from an earlier LL post, "When men were men, and verbs were passive", 8/4/2006, where I observed that Winston Churchill, often cited as a model of forceful eloquence, used the passive voice for 30-50% of his verbs in various passages from his 1899 memoir The River War — several times the rate noted in statistical usage studies from the 1960s and later.
So I thought I'd do a quick historical survey of passive-voice rates, as a example of what can be done with Mark Davies' COHA corpus.
The texts in COHA have been automatically tagged with the CLAWS tagset, and the COHA search interface lets us use the locution [vb*] to refer to all the forms of the verb be (included contractions and so on), so we should be able to search for a pattern meaning "form-of-be past-participle":
[vb*] [vvn]
This won't find cases where an adverb or other adjunct intervenes between the be-form and the past participle (e.g. "… was previously noted by …"); and of course it relies on the CLAWS tagger being mostly right.
However, it doesn't work anyhow, because Mark Davies is (reasonably) worried about doing big joins, and so the search interface informs us that
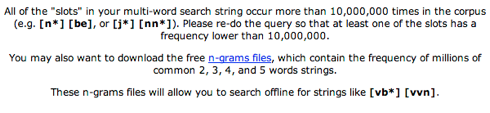
Well, there are just 8 possible be-forms in the CLAWS tagset, so we maybe can search separately for
were: [vbdr] [vvn]
was: [vbdz] [vvn]
being: [vbg] [vvn]
be: [vbi] [vvn]
am: [vbm] [vvn]
been: [vbn] [vvn]
are: [vbr] [vvn]
is: [vbz] [vvn]
And indeed these searches work.
But there's still a hurdle to overcome. The COHA interface presents its results to us in the form of an HTML table (and furthermore, one that's embedded in an HTML frameset). Here's the start of such a table as displayed in a web browser:

And here's just a little bit of what the underlying HTML (for the relevant frame) looks like:

We could save the HTML as a local file, and write a program to pull out the numbers from the table. (It would be MUCH easier if Mark Davies would add a button to pop up a plain-text table, suitable for reading into R, as below…). [Update — As Neal Goldfarb points out in the comments, MS Excel and perhaps other spreadsheet programs will accept cut-and-paste of html tables into the rows and columns of a spreadsheet, which may be how some people want to do subsequent analysis anyhow. And for those who prefer data analysis in R, it's possible to write out the spreadsheet as a .csv file, which R can then read via read.csv(). But in my experience, that's at least as much trouble as hacking a plain text file for read.table(). Also, in this case I just want to add up the TOTAL line from each of the 8 returned tables anyhow.]
But in this case, all that we care about is the bottom line — the total across all instantiations of the pattern:

So we can snarf the TOTAL row with the mouse or trackpad, and paste the numbers into a plain text file, with an initial value to remind us of what the numbers are. After a bit of fussing with tabs and spaces and so on, we'll have a file like this one, with 8 rows and 21 columns. (I used emacs to map all tab/space sequences to single spaces — but in fact, R's function read.table() is rather generous about treating all tab/space combinations as single field separators…)
Now all we need is a little bit of R scripting, like this, and we can plot the trend:

So we see that Americans' (textual) passivity has been declining steadily for 200 years, and even more steeply since WWII.
The effect is not a small one — the estimated rate has fallen from 4,369 per million in the 1820s, to 1,951 per million in the 2000s.
There are a few controls we should run to be sure that the effect is a real one, and that we're describing it correctly:
- Maybe the mix of sources in COHA has been changing, in ways that contribute to the effect or even explain it? (I don't think so.)
- Maybe the UCREL CLAWS tagger mis-classifies past participles at a high rate in a time-varying way? (I don't think so.)
- Maybe passive verbs are being used at the same relative rate as ever, but verbs as a class have gotten less frequent (relative to other classes of words) by a factor of two — e.g. American English is getting nounier. (I don't think so.)
And there are plenty of other patterns to look at:
- Has there also been a historical change in the relative proportions of different forms of be in passives?
- What about the distribution of lexical verbs in passives?
- Are there historical changes in the (absolute or relative) frequency of other aspect/tense/mood/voice combinations?
And then there are various possible explanations for the effect, some of which can be explored empirically:
- Vernacularization: Maybe American English prose has been getting closer to the norms of the spoken language, with increased use of get-passives, and decreased use of passives overall.
- Maybe American writers are increasingly likely to put adverbs between be-forms and past participles in passive-voice constructions.
- Maybe the "Avoid Passive" usage advice is taking its toll.
The vernacularization hypothesis makes some sense, but it doesn't seem adequate to me — I suspect that we can see a similar trend in the spoken language. And none of the rest of the obvious explanations seem likely to stand up to testing. For example, the anti-passive animus among usage mavens seems to have originated in the first couple of decades of the 20th century, at a time when the decline in passive usage had apparently been underway for at least a hundred years.
No doubt readers will be able to think of other explanations. But I wonder whether maybe the passive is just going the way of the passival.
Neal Goldfarb said,
July 15, 2013 @ 9:04 am
The tables in COHA (and the other BYU corpora) can be copied and pasted into a spreadsheet. Wouldn't that be easier than pasting the data into a plain text file?
[(myl) For spreadsheet jockeys, that's great. But in order to use R, you have to write the result out as a csv file, and then (depending on the context) maybe fix that file to deal with CR/LF issues, funny non-printing characters (what are all those octal 0312's for?), etc. So I find that cut-and-paste directly into a plain text file is easier and safer; but YMMV.]
Maryellen MacDonald said,
July 15, 2013 @ 10:22 am
These declining rates are interesting to me because in relative clauses, passives are still going strong. In our production studies, English speakers use passives about 98% of the time when talking/writing about animate entities and about half of the time when the relative clause modifies an inanimate (The boy/toy that was splashed…). Across the 6 languages we've studied (English, Spanish, Serbian, Japanese, Korean, Mandarin), only Mandarin has higher passive rates than English. (Data are in Fig 1 here http://www.frontiersin.org/Language_Sciences/10.3389/fpsyg.2013.00226/full. This figure plots the rate of the non-passive form–the object or center-embedded relative clause like "The boy/toy that the girl splashed…" So short bars in the figure reflect situations with lots of passive use). I realize relative clauses are only a fraction of all uses, but still, passives seem to be firmly entrenched there.
Also, Mark, what about get-passives, as in "The boy {who} got splashed"? These are fairly rare in text, but some of what were be-passives in previous eras might be moving to get-passives?
Dominik Lukes (@techczech) said,
July 15, 2013 @ 11:27 am
I wonder why you don't find the impact of the no passive rule and informalization of writing so implausible. The points mitigating against the former are the inability of speakers to identify passives reliably and relative stability of usage in the face of prescription but I wonder if in more recent times, the injunctions may have become so ubiquitous and enforced in such a variety of contexts as to actually register an impact.
I could also see the impact of de-formalization in a lessened need to mimic formal styles of writing of which passives seem to be one feature salient to lay writers.
Of course, neither of these would justify the the gradual progression and the scale of the impact but they could certainly form a part of a feedback loop.
Beth said,
July 15, 2013 @ 12:21 pm
I'm wondering if the "avoid passive" advice isn't somehow inspired by the declining popularity of the passive.
Orin Hargraves said,
July 15, 2013 @ 1:16 pm
It is striking that the beginning of the precipitous decline is more or less coincident with the first publication of Strunk's Elements of Style (1918), which you mentioned in your original post.
[(myl) Not really: in tabular form, the relevant section of the data looks like this:
1890-1900 4121
1900-1910 4014
1910-1920 3790
1920-1930 3838
1930-1940 3786
So it would be more accurate to say that the publication of Strunk's little book coincided with a 30-year-long period of relative statis in passivity.]
blahedo said,
July 15, 2013 @ 3:34 pm
@Maryellen MacDonald: He did mention get-passives as a possible explanation for the decline (under "vernacularization").
I'm a little curious about other passive forms, too, like the ones that function as reduced relative clauses ("the boy [that was] splashed by the mud was unhappy") and other contexts where the passive is not only not _immediately_ preceded by its be-form, but not preceded by one at all. Such usages aren't the most common, of course, but they seem to make up a nontrivial percentage of passive forms.
But that's just idle curiosity, rather than an objection to the larger point: for any of these explanations (get-passives, intruding adverbs, various other passive forms) to explain the decline seen in the graph above, we would have to be seeing the non-[vb*][vvn] passive forms as more _half_ of all passives, and that seems to clearly _not_ be the case.
mollymooly said,
July 15, 2013 @ 4:13 pm
Modifying Orin Hargraves's theory: Wikipedia suggests that Strunk's book was not widely read until White wrote about it in 1957 and revised it in 1959. [insert myl comment here] Yeah, that theory doesn't really work either.
Was the mid-19th century a high-water-mark for passives? It was the time when the progressive passive took off.
Jonathon Owen said,
July 15, 2013 @ 8:04 pm
Something I casually noticed (but didn't explore in depth) while researching my thesis is that the usage advice seems to get stronger and more categorical as the proscribed usage declines. Not only that, but many people seem to see the proscribed forms as on the rise even when they can be shown to be declining.
For example, I've seen people talk about the that/which distinction as one that is being blurred because nobody cares about it anymore, even when there's evidence to the contrary. Obviously it's tied to the recency and frequency illusions. As the rule is promulgated, more people notice the proscribed constructions and thus think they're on the rise, even as they're being driven out of use.
Maryellen MacDonald said,
July 15, 2013 @ 8:35 pm
@blahedo: I was corrected by blahedo on the prior mention of get-passives, and he got thanked!
Bill said,
July 15, 2013 @ 8:57 pm
Is it possible that usage guides were just "riding the wave" so to speak? (it was already on the way to becoming stigmatized, so editors jumped on the bandwagon?)
Rob said,
July 18, 2013 @ 4:41 pm
My guess is that the informalisation of language and greater literacy might be the cause. The passive is more likely to be used by academic and experienced writers, while those who do little writing are more likely to use the active voice. Of course, the key words here are “my guess”, but I’d be interested if there was anyway the data could be used to help confirm this.