
Corpus-based Linguistic Research: From Phonetics to Pragmatics
7. Programs and programming:
Practical methods for searching, classifying, counting, and measuring
We'll divide this lecture into three sections: No Tech, Low Tech, and High Tech.
We're really talking about the users' degree of technological sophistication, not the amount and kind of technology embodied in the tools they use. As time goes on, technological improvement shifts this spectrum, so that what used to require bleeding-edge sophistication becomes accessible to any high-school student with a laptop. And one person's crude low tech solution may be another person's opportunity to spend a few weeks learning a new programming language or a new set of mathematical concepts.
But I want to underline the idea that corpus-based linguistic research is not necessarily high-tech research. Or at least, people doing corpus-based research don't necessarily need to fully master the underlying technologies, any more than someone using a book needs to understand the complex underlying technology of paper-making and ink chemistry and modern typesetting and printing techniques.
It's certainly true that recent technological innovations are bringing qualitative changes to corpus-based linguistic research. Inexpensive mass storage and ubiquitous digital communications means that larger and larger samples of linguistic behavior are available for research, as a by-product of normal cultural, social and commercial activities. The increasing ease of sharing datasets also means that scientific researchers are increasingly likely to open up their materials to others. And the development of increasingly capable methods of automatic or semi-automatic analysis, running on increasingly cheap and fast computers, means that we can often do, in a few hours, things that would have been a life's work a few decades ago.
And at every stage of this process, your life will be a lot easier if you learn to write or adapt simple computer programs as well as to use them.
But it also remains true that the goal of corpus-based linguistic research is to bring empirical evidence to bear on questions of scientific, cultural, or social interest. Often, we can do this in very simple ways -- and other things equal, simpler methods are better, if your focus is not on the methods but on the results.
In the discussion below, I'll focus on text analysis -- an analogous set of remarks could be made about speech-based research, and a few examples of corpus-based speech research will be cited.
"No Tech" Methods
Sometimes the most appropriate methods use no technology at all -- or at least no technology beyond paper, and pencils or pens. Well, printing also usually comes into it, and maybe a xerox machine or a laser printer or an ink-jet printer.
I used a method like this back in August of 2006, when I decided to do a little empirical investigation of the widespread idea that the passive voice is a Bad Thing, because it's, well, "passive" -- weak, evasive, indirect, ... In short, not vigorous and manly enough. My idea was to look at the frequency of different choices in the works of some notoriously vigorous and manly men, and I decided to start with Winston Churchill, and in particular with his 1899 memoir The River War: An Account of the Reconquest of the Sudan.
I wrote up my findings in a weblog post "When men were men, and verbs were passive", 8/4/2006. In that post, you'll see a reflection of the technique that I actually used, which was to print out the text and to mark up all the tensed verbs with three different colored highlighter pens: red for passive, blue for active, and green for copulas and similar things. I also used colored tick marks in the margins, to make it easier to count things up.
The result looked something like this, applied to the first paragraph of the 1902 edition of Churchill's memoir.

An even lower-tech method would involvedividing a piece of scrap paper into regions, and tallying events of different sorts (in a text or in a recording or broadcast or real-life event) by making tick marks in the various areas. This doesn't require colored pens or even a copier or printer.
I could also have replaced the colored pens with font color switches in a word-processing program like Microsoft Word:

(And in the blog post, I used analogous HTML font-color tags for the example paragraphs.)
But the paper-and-highlighter method is faster, frankly. In a case of this kind, it might take you something like 5 seconds on average to process a sentence -- that's 12 sentences per minute, or 720 sentences per hour. At an average of about 20 words per sentence, that's something like 14,400 words an hour. And if the phenomenon of interest to you occurs at least once in every sentence that you process, as choice of verbal voice does, you can easily get 1,000 observations in an hour or two.
And if you're willing and able to spend weeks or months on the process, methods of this general kind can produce enormous amounts of data.
So unless a ready-made high tech method is available or obviously easy for you to create, you should always start by considering paper-and-pencil methods. You should do something more complicated only if it will really save time, or will really make it possible for you to do something that is essentially impossible to do by hand. There's no point in spending days (or weeks or months) in writing and testing a program to save yourself a few hours of work.
If you're studying a rarer phenomenon, you may want to find a way to zero in on the cases of interest to you before doing your diagnosis and deploying your highlighter or your pencil-and-tally-sheet. In the next sections, we'll discuss some (low- and high-tech) ways of doing this.
"Low Tech" Methods
Human Annotation
Instead of using colored markers or other low-tech forms of "tagging" and counting, we could use a program like Anafora, Knowtator, or BRAT, which allow us to assign tags to regions of text, define relations among tagged regions, and so on. It's not entirely trivial to learn to set one of these systems up for a new task; and when you've done it, the actual annotation process is likely to be somewhat slower than the colored-pens method.
Someday, someone will create an annotation system of this kind whose out-of-the-box experience is easy -- comparable, say, to Praat for speech analysis. Meanwhile, unless you're in an environment where someone has already installed a system of this kind, a method with lower start-up costs would be to tag regions with colors or other attributes in a document editor, e.g. in a Google Drive document. If you then save such a document as HTML, the relevant regions of the document will be marked with something like
<span class="c1">marked region</span>
<span>The north-eastern quarter of the continent of Africa </span><span class="c1">is drained and watered</span><span> by the Nile. Among and about the headstreams and tributaries of this mighty river </span><span class="c0">lie</span><span> the wide and fertile provinces of the Egyptian Soudan. Situated in the very centre of the land, these remote regions </span><span class="c1">are on every side divided </span><span>from the seas by five hundred miles of mountain, swamp, or desert. The great river </span><span class="c5">is</span><span> their only means of growth, their only channel of progress. It </span><span class="c5">is</span><span> by the Nile alone that their commerce </span><span class="c0">can reach</span><span> the outer markets, or European civilisation </span><span class="c0">can penetrate</span><span> the inner darkness. The Soudan </span><span class="c1">is joined</span><span> to Egypt by the Nile, as a diver </span><span class="c1">is connected</span><span> with the surface by his air-pipe. Without it there </span><span class="c5">is</span><span> only suffocation. </span>
This is quite analogous to the way that more specialized annotation systems represent such annotations in their output files.
Alternatively -- and even more simply -- you could insert bits of annotation-text into the document yourself. Thus in the example we've been considering, we could stick in tags like /P ("passive"), /AI ("active intransitive"), /AT ("active transitive"), /C ("copula"), etc. And while we're at it, we could put every sentence on a separate line:
The north-eastern quarter of the continent of Africa is/P drained and watered by the Nile.
Among and about the headstreams and tributaries of this mighty river lie/AI the wide and fertile provinces of the Egyptian Soudan.
Situated in the very centre of the land, these remote regions are/P on every side divided from the seas by five hundred miles of mountain, swamp, or desert.
The great river is/C their only means of growth, their only channel of progress.
It is by the Nile alone that their commerce can reach/AT the outer markets, or European civilisation can penetrate/AT the inner darkness.
The Soudan is/P joined to Egypt by the Nile, as a diver is/P connected with the surface by his air-pipe.
Without it there is/E only suffocation.
Aut Nilus, aut nihil!
You're still going to need a bit of simple programming to count the various annotation types, characterize their environments, or whatever -- but this really will be a simple sort of program.
An approach of this kind has a few advantages:
(1) You can set up to correct or extend the output of an automatic analyzer, which in some cases may speed the process up quite a bit.
(2) Because these systems leave you with "machine readable" annotations, you can count and re-count things in flexible ways (if you can write simple programs to parse the output format).
(3) If you're interested in applying "machine learning" to build or improve automatic analysis, the output is fairly easy to adapt for use as training data.
(4) Such systems may make it easier to recruit others to help you.
Automatic Annotation
In my little investigation of Winston Churchill's passivity, I might have used an existing automatic part-of-speech tagger, like the one in NLTK, as a way to classify active and passive verbs, relying on the assignment of the tags VBN (past participle), VBD ("past tense" or preterite form), VBZ (third-person singular present form), VBP (non-third-singular present form). (These are tags from the Penn (English) Treebank; another widely-used set of P.O.S. tags for English is the CLAWS tagset.)
Thus the first sentence of The River War is:
>>> import nltk
>>> sentence = """The north-eastern quarter of the continent of Africa is drained and watered by the Nile. """
>>> tagged = nltk.pos_tag(tokens)
>>> tagged
[('The', 'DT'), ('north-eastern', 'JJ'), ('quarter', 'NN'), ('of', 'IN'), ('the', 'DT'), ('continent', 'NN'), ('of', 'IN'), ('Africa', 'NNP'), ('is', 'VBZ'), ('drained', 'VBN'), ('and', 'CC'), ('watered', 'VBN'), ('by', 'IN'), ('the', 'DT'), ('Nile', 'NNP'), ('.', '.')]
So far, so good: the fact that "is drained and watered" is tagged as "VBZ VBN CC VBN" would allow us to recognize a passive verb phrase (because VBN is the tag for a past participle, and VBN following a form of be is the basic signal of a passive verb. But things don't go as well in the second sentence:
>>> sentence2 = """Among and about the headstreams and tributaries of this mighty river lie the wide and fertile provinces of the Egyptian Soudan."""
>>> tokens2 = nltk.word_tokenize(sentence2)
>>> tagged2 = nltk.pos_tag(tokens2)
>>> tagged2
[('Among', 'IN'), ('and', 'CC'), ('about', 'IN'), ('the', 'DT'), ('headstreams', 'NNS'), ('and', 'CC'), ('tributaries', 'NNS'), ('of', 'IN'), ('this', 'DT'), ('mighty', 'NN'), ('river', 'NN'), ('lie', 'NN'), ('the', 'DT'), ('wide', 'JJ'), ('and', 'CC'), ('fertile', 'JJ'), ('provinces', 'NNS'), ('of', 'IN'), ('the', 'DT'), ('Egyptian', 'JJ'), ('Soudan', 'NNP'), ('.', '.')]
Here, alas, the main verb "lie" is tagged as "NN", i.e. a common noun, meaning that we will not be able to count it as the third-person plural active (intransitive) verb it actually is (or indeed as any kind of verb).
And the third sentence is no better, for our purposes:
>>> sentence3 = """Situated in the very centre of the land, these remote regions are on every side divided from the seas by five hundred miles of mountain, swamp, or desert. """
>>> tokens3 = nltk.word_tokenize(sentence3)
>>> tagged3 = nltk.pos_tag(tokens3)
>>> tagged3
[('Situated', 'NNP'), ('in', 'IN'), ('the', 'DT'), ('very', 'JJ'), ('centre', 'NN'), ('of', 'IN'), ('the', 'DT'), ('land', 'NN'), (',', ','), ('these', 'DT'), ('remote', 'NN'), ('regions', 'NNS'), ('are', 'VBP'), ('on', 'IN'), ('every', 'DT'), ('side', 'NN'), ('divided', 'VBD'), ('from', 'IN'), ('the', 'DT'), ('seas', 'NNS'), ('by', 'IN'), ('five', 'CD'), ('hundred', 'CD'), ('miles', 'NNS'), ('of', 'IN'), ('mountain', 'NN'), (',', ','), ('swamp', 'NN'), (',', ','), ('or', 'CC'), ('desert', 'VB'), ('.', '.')]
Here the past participle divided is tagged as VBD, which is the tag for an active-voice preterite verb -- so this case would be counted in the wrong category.
In this case, the UCREL CLAWS tagger does a better job:
The_AT north-eastern_JJ quarter_NN1 of_IO the_AT continent_NN1 of_IO Africa_NP1 is_VBZ drained_VVN and_CC watered_VVN by_II the_AT Nile_NP1 ._. Among_II and_CC about_II the_AT headstreams_NN2 and_CC tributaries_NN2 of_IO this_DD1 mighty_JJ river_NN1 lie_VV0 the_AT wide_JJ and_CC fertile_JJ provinces_NN2 of_IO the_AT Egyptian_JJ Soudan_NN1 ._. Situated_VVN in_II the_AT very_JJ centre_NN1 of_IO the_AT land_NN1 ,_, these_DD2 remote_JJ regions_NN2 are_VBR on_II every_AT1 side_NN1 divided_VVN from_II the_AT seas_NN2 by_II five_MC hundred_NNO miles_NNU2 of_IO mountain_NN1 ,_, swamp_VV0 ,_, or_CC desert_NN1 ._.
And the Berkeley Parser does the right thing with all three of these sentences, both in terms of P.O.S. tags and also in terms of parse trees (more or less):
((S (NP (NP (DT The)
(JJ north-eastern)
(NN quarter))
(PP (IN of)
(NP (NP (DT the)
(NN continent))
(PP (IN of)
(NP (NNP Africa))))))
(VP (VBZ is)
(VP (VP (VBN drained))
(CC and)
(VP (VBD watered)
(PP (IN by)
(NP (DT the)
(NNP Nile))))))
(. .)) )((SINV (PP (IN Among)
(CC and)
(IN about)
(NP (NP (DT the)
(NNS headstreams)
(CC and)
(NNS tributaries))
(PP (IN of)
(NP (DT this)
(JJ mighty)
(NN river)))))
(VBP lie)
(NP (NP (DT the)
(ADJP (JJ wide)
(CC and)
(JJ fertile))
(NNS provinces))
(PP (IN of)
(NP (DT the)
(JJ Egyptian)
(NNP Soudan))))
(. .)) )((S (PP (VBN Situated)
(PP (IN in)
(NP (NP (DT the)
(JJ very)
(NN centre))
(PP (IN of)
(NP (DT the)
(NN land))))))
(, ,)
(NP (DT these)
(JJ remote)
(NNS regions))
(VP (VBP are)
(PP (IN on)
(NP (DT every)
(NN side)))
(VP (VBN divided)
(PP (IN from)
(NP (DT the)
(NNS seas)))
(PP (IN by)
(NP (NP (CD five)
(CD hundred)
(NNS miles))
(PP (IN of)
(NP (NN mountain)
(, ,)
(NN swamp)
(, ,)
(CC or)
(. .)) )
But still, we are going to have to check a large sample of outputs to be sure that they're accurate enough for our purposes -- and for the same amount of work, we could have annotated the forms by hand in the first place.
So for a modest number of analyzed examples, doing the analysis by hand may still be the easiest way. But an automated approach would be very attractive if we wanted to study historical change (see below), or British vs. American norms, or male vs. female authors, or anything else involving annotation on a large scale.
If the automated analysis is right much more often than it's wrong, we might decide that we can live with its error rate. Or we may be able to check and correct its output faster than we can create a full annotation from scratch by hand -- that's certainly true if we need a complete set of P.O.S. tags or complete parse trees for all the text in our dataset.
Low-Tech Search, Analysis and Display
There are an increasing number of useful web-browser interfaces to interesting text collections -- as time goes on, you can expect to see more of these, and also to see a proliferation of similar interfaces to speech datasets.
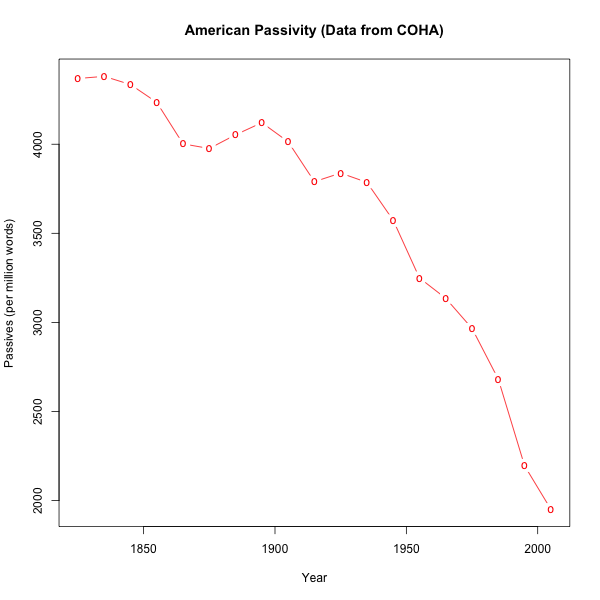
As a result of these developments, some kinds of corpus searching, counting, and analyzing have become accessible to relatively simple low-tech methods. For today's lecture, I've done a small Breakfast Experiment™ on the history of passive-voice constructions in American English, and published a fairly detailed account of what I did, in the form of a weblog post "American Passivity", 7/15/2013.
The experiment took me about a half an hour to do, and the write-up another half hour or so. It was easy because the datasets had already been collected and indexed and made available for browser-based search, and I was able to find a way to pose (a proxy for) the question of interest via the COHA web interface. So I didn't have to do any serious data-gathering, nor any complex programming. I just needed to run eight searches; transfer the results into a text file; and then write a few lines of vanilla R scripting to add up the columns of numbers that COHA's restrictions forced me to collect separately, to turn the summed counts into rates, and to plot the resulting rates as a function of time:
"High Tech" Methods
Often the datasets you want are not already collected and indexed. So you're faced with questions about sampling and balancing your materials; with OCR and/or speech transcription issues; with choosing formats and modes of organization for the dataset; with questions of indexing and searching and counting.
In many cases, a suitable dataset is available, but it comes without any tools for indexing and searching and counting. It may also lack some of the kinds of annotation that you need.
All of this can be true even if what you want to do has become routine and easy in some other context. For example, if you wanted to compare the historical frequency of passive constructions in British English, much less in German or Italian or Russian, you'd be looking at a very big job.
And finally, you may want to some completely new kind of modeling, perhaps even on some new kinds of data, for which there are not really any precedents.
In cases like these, you're going to have to fall back on some combination of general-purpose programming tools, and more specialized programs or packages that someone has put together for somewhat similar purposes. This is a complicated landscape, with many paths and lots of problems, choices and issues on every one of them.
What follows is a personal perspective on how to approach all of this, in the form of some general advice.
1. Learn simple Unix shell scripting, and a few text-oriented programs such as grep, sed, tr, awk, perl,... You're likely to find this helpful in all kinds of circumstances. On Macs, since the underlying system is a form of Unix, you can get at this environment in a terminal window if you've installed XCode from the App Store (it's free). There are various options for running a Unix-like environment within Windows (Cygwin, MinGW and MSYS, GnuWin, etc.), but you also might want to consider setting up a "dual boot" system in which you can either boot Windows or Linux. Or finally, if you have an older laptop or desktop machine lying around, or can afford to buy an extra new one, you might consider setting up a pure Linux box, running e.g. Ubuntu.
2. Learn Python, in the context of NLTK. This is at least an excellent way to learn about NLP algorithms, and in fact you can use Python for nearly all your programming needs -- there are now Python modues to do nearly anything that computers can do.
3. Learn R.
4. If you're working on speech, learn to use Praat, including its rather unfortunately-designed scripting language. Also consider learning Matlab/Octave, partly because it's a good way to learn linear algebra, and partly because there are many good packages for various kinds of audio signal processing.
4. Consider learning some other programming languages, such as java or C/C++, as need arises within projects you're working on.
Whatever path you take, let me repeat some advice from an earlier lecture:
* Learn by doing -- learn enough of topic or system X to apply it to some aspect of a problem you're working on. It helps if you can find a collaborator who already knows X.
* Take it one step at a time: Try to find problems whose solution is just a bit beyond what you already know.
* The best way to understand something -- and to test your understanding -- is to play with a simple implementation of a simple problem.
* Learn a little more than you need to solve your current problem, aiming at some broader competences.