The QWERTY effect
« previous post | next post »
Rebecca Rosen, "The QWERTY Effect: The Keyboards Are Changing Our Language!", The Atlantic:
It's long been thought that how a word sounds — it's very phonemes — can be related in some ways to what that word means. But language is no longer solely oral. Much of our word production happens not in our throats and mouths but on our keyboards. Could that process shape a word's meaning as well?
That's the contention of an intriguing new paper by linguists Kyle Jasmin and Daniel Casasanto. They argue that because of the QWERTY keyboard's asymmetrical shape (more letters on the left than the right), words dominated by right-side letters "acquire more positive valences" — that is to say, they become more likable. Their argument is that because its easier for your fingers to find the correct letters for typing right-side dominated words, the words subtly gain favor in your mind.
There's a lot of media uptake for this work: Rachel Zimmerman, "Typing and the meaning of words", Common Health; "QWERTY Keyboard Leads to Feelings about Words", Scientific American; Rob Waugh, "Why just typing 'LOL' makes you happy: People like words made of letters from the right-hand side of the QWERTY keyboard", Daily Mail; Alasdair Williams, "The 'QWERTY Effect' is changing what words mean to us", io9; "The right type of words", e! Science News; Dave Mosher "The QWERTY Effect: How Typing May Shape the Meaning of Words", Wired News; Rebecca Rosen "The QWERTY Effect: The Keyboards Are Changing Our Language", The Atlantic, etc.
From the paper — Kyle Jasmin and Daniel Casasanto, "The QWERTY Effect: How Typing Shapes the Meaning of Words", Psychonomics Bulletin and Review, 2012:
We analyzed valence-normed words from three corpora: the Affective Norms for English Words corpus (ANEW; Bradley & Lang, 1999), and two translation equivalents of ANEW in Spanish (SPANEW; Redondo, Fraga, Padrón, & Comesaña, 2007) and Dutch (DANEW). ANEW consists of 1,034 words. Participants used a pencil to rate valence on a 9-point scale composed of five self-assessment manikins (SAMs), which ranged from a smiling figure at the positive end of the scale to a frowning figure at the negative end. Participants were told to mark one of the manikins or a space between two adjacent manikins (see Bradley & Lang, 1999). In SPANEW, translations of the ANEW words were rated by native Spanish speakers using a similar procedure (see Redondo et al., 2007). […]
For each word in the corpus, we computed the difference of the number of left-side letters (q, w, e, r, t, a, s, d, f, g, z, x, c, y, b) and right-side letters (y, u, i, o, p, h, j, k, l, n, m), a measure we call the right-side advantage [RSA = (# right-side letters) − (# left-side letters)]. Overall, there was a significant positive relationship between RSA and valence in ANEW, SPANEW, and DANEW combined, according to a linear regression with items (ANEW words and their translation equivalents) as a repeated random factor using SPSS’s GLM function. Words with more right-side letters were rated to be more positive, on average, than words with more left-side letters. We call this relationship the QWERTY effect.
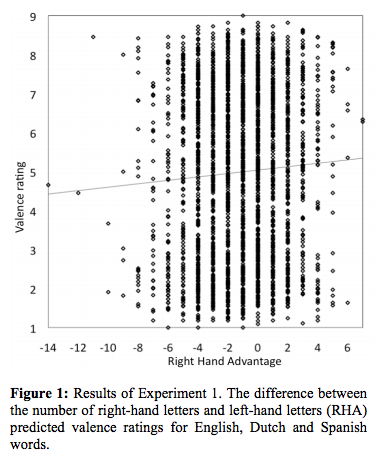
I don't have access to SPANEW or DANEW, but ANEW is given an an appendix to Bradley & Lang 1999, so I extracted the list from the .pdf and did my own linear regression for the English data alone:

This is pretty similar to the picture given in an earlier paper by the same authors, except that they show an amalgam of all three datasets ("The QWERTY Effect: How stereo-typing shapes the mental lexicon", CogSci 2011):
[And I note that there's a typo in both their CogSci 2011 paper and in the 2012 Psychonomics Bulletin and Review paper, namely that 'y' is substituted for 'v' in their list of left-hand letters, so that 'v' doesn't occur in the list for either side, while 'y' occurs on both sides. Here's a screenshot of the passage in the 2012 paper:

It's not clear whether this mistake is replicated in their code, or only in their explanation of it…]
Whether in the English data alone, or in the combined data for all languages, we can see the that effect is not a very strong one. And in my replication with the 1,034 ANEW words alone, it's not statistically significant. I'm not going to cite the (non-significant) p value, since I don't think it means much, but I'll mention that the adjusted multiple r2 (equal to the proportion of variation accounted for) is 0.0015.
As I said, I don't have access to the other two data bases, but I did manage to get another comparable body of data, for which the results were similar:

It's comforting to see apparent confirmation — at least of the direction of the effect — in an independently-collected data set, with a similar adjusted multiple r2 of 0.0013. At least, it's comforting until we recognize that the source of this data was a random number generator. I created three sets of random data by pairing the "right-side advantage" values of the ANEW words with random re-samplings (with replacement) from the set of ANEW valence estimates. Of the three, this was the one that was most similar to the pattern in the original data. Of the other two, one showed a similar effect with a negative rather than positive slope, while the other had a flat regression line. (The results were comparable when I generated the random values by drawing in a different way from a distribution with a shape similar to the overall histogram of ANEW valence estimates.)
Jasmin and Casasanto found some other confirming evidence as well, for example in valence estimates of invented pseudowords. But I wonder whether this work stands up to the tests suggested in Joseph Simmons et al., "False-Positive Psychology: Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant", Psychological Science, 2011.
In any case, I feel that the strength of the effect, if it exists, is far too small to support the interpretation presented in the popular press — with some apparent encouragement from Jasmin & Casasanto — as in the conclusion of the e! article (which I think is just the Springer press release):
Linguists have long believed that the meanings of words are independent of their forms, an idea known as the “arbitrariness of the sign.” But the QWERTY effect suggests the written forms of words can influence their meanings, challenging this traditional view.Should parents stick to the positive side of their keyboards when picking baby names – Molly instead of Sara? Jimmy instead of Fred? According to the authors, “People responsible for naming new products, brands, and companies might do well to consider the potential advantages of consulting their keyboards and choosing the 'right' name."
Update — thanks to Steve Kass, I found the DANEW list in .pdf form as an appendix to the online supplementary materials for the paper, extracted it, and plotted it:

Again, the effect is not statistically significant — and in any case is not large enough to be a concern for companies naming products or parents naming children, with 0.1% of variance in valence judgments accounted for by the "QWERTY effect".
Update #2 — more here.
Eric P Smith said,
March 8, 2012 @ 9:31 pm
Oll hihly unlikly.
John said,
March 8, 2012 @ 9:40 pm
Just another attempt to deprecate God's chosen left-handers.
Rod Johnson said,
March 8, 2012 @ 9:50 pm
How much of this effect could be accounted for by the presence of Q, W, X and Z on the left side of the keyboard. What Scrabble player hasn't groaned when those have shown up on the board? I think those letters themselves have a slight negative valence–I guess the question is, how can you distinguish the right-side effect from emotional reactions inherent to the letters themselves?
[(myl) Note that the ANEW word-valence judgments were collected in the 1990s using printed words and pencil-and-paper responses. It's really not clear that the experimental subjects had spent a lot of time typing; and certainly the experimental protocol itself in no way evoked a qwerty keyboard.]
Clare said,
March 8, 2012 @ 10:19 pm
I find it highly unlikely that (among other things) the vowels i, o, and u could be considered more positive than a and e.
Also, what about people who use alternative keyboards such as Dvorak?
Bobbie said,
March 8, 2012 @ 10:49 pm
From what I understand, the QWERTY keyboard was designed that way to **slow down a typist (who had to press down each key, with much more strength than on today's keyboards.) For that reason, the most-frequently used letters were arranged on the left side, assuming that most typists would be right-dominant. So, at what point did the preference "switch" to those letters on the right half of the keyboard? Or is it just an effect of people's preferring the letters on their dominant hand?
[(myl) The "preference", if it exists, is very weak; and may be due to a small number of local factors rather than to some global side-of-keyboard bias.]
Steve Kass said,
March 8, 2012 @ 11:04 pm
Mark: The complete DANEW wordlist with rating data is provided in the supplementary materials of the paper. (But let me know if you have better luck than I did extracting it as text. I couldn't and stopped short of resorting to OCR.)
[(myl) Thanks — Here you go. Acrobat is pretty good about turning .pdf documents into plain text. I've added an update to the paper with the scatter plot and regression line.]
There are plenty of oddities in Jasmin and Casasanto's paper. Here are a few. Maybe if I can extract more from the PDF, I'll find more:
– The authors report a stronger QWERTY effect on new (coined after the invention of QWERTY) words, and the data to support was based on AFINN. They only provide the 63 "new" words in AFINN, not the non-new ones, but those 63 don't strike me as a list from which generalizations are warranted. Eight of them (13%) contain "fuck" as a substring (Was "fucked" was truly coined after QWERTY?), and there are six different entries that are variations on "greenwash." If each word contributed equally to the regression analysis, considerable effect could be due to how "fuck" and "greenwash" were rated, not to mention "woohoo," "woo," "woow," "wowow," and "wowww."
– The pseudoword list and its construction are also puzzling. "Words" were kept or eliminated in groups of four depending on whether any of the four was an actual word or homonym of a word. Thus "skove," "skave," "skoove," and "skeeve" were kept, but "skope," "skape," "skoope," and "skeepe" were removed. It's not clear to me why homonyms or entire groups of four words should be removed, but the result is that some uncommon consonant clusters containing "w" (dw-, gw-, and thw-) are more strongly represented in the final list than many others.
The authors incidentally mention that the DANEW words were rated for several factors not addressed in the paper: arousal, concreteness, dominance, and imageability. The data is all in Appendix B (but not copy-and-pasteable as far as I can tell), and it would be interesting to see if there's a QWERTY effect for any of these factors. It's hard not to wonder if the authors looked for one. Certainly the paper doesn't conform to all of the recommendations in the Psychological Science paper you mention.
Robert Sharp said,
March 9, 2012 @ 12:59 am
That conclusion is from the e! article, not the io9. :)
[(myl) And the e! article, as far as I can tell, is just a reprint of the Springer press release. Thanks for the correction — the post is fixed now.]
glitch said,
March 9, 2012 @ 1:16 am
This probably isn't really significant, but after noticing that "skeeve" (which I would consider an actual word, as in "that totally skeeves me out") was in the pseudoword list according to Steve Kass's comment, I looked at the psuedoword list and noticed a few more words that are actually words (mostly fairly vernacular ones, but still) like "spooge", "smoosh", "zoot" and, oddly, "smooth". Interestingly, they have "n00b" in the list of words that were invented after the QWERTY keyboard, and "noob" in the pseudowords list…
Ian Tindale said,
March 9, 2012 @ 2:37 am
Yet more blatantly unacceptable ignorance of diversity from those intolerably exclusionist right-handers (who are, as usual, wrong).
Incidentally, the other day I was trying to pre-construct a phrase to deliver to an idiot colleague who complains that I leave the mouse set to left-handed on a specific computer that he clearly has no idea how to use (despite the fact that every time I come to use it, some moron has inconsiderately left it set to right-handed — not just occasionally, but every single time!). I was pondering on a wider meaning of “you homophobic Nazi”, but of course homophobic doesn’t mean “fear of the similar / same”, rather, quite the opposite — a specific variant of ”fear of the opposite (of oneself, if you’re straight)”. Weird, eh?
LDavidH said,
March 9, 2012 @ 3:43 am
It would have been interesting to see what these researchers would say about Swedish keyboards, that have three additional letters on the right (Å next to the P, Ö next to the L and Ä to the right of Ö), thus making the keyboard that much more symmetrical.
Or is this the reason why certain heavy metal groups and icecreams like to use those letters in a nonsensical way?? Finally we know! :-)
scav said,
March 9, 2012 @ 4:02 am
Anybody who subscribes to that theory obviously doesn't like SEX, or money ($ and £), and they prefer to ask questions than make exclamations. While I'm at it, I'll blame them for the insertion of unnecessary apostrophes.
Also their ability to understand logic is maybe impaired by their aversion to the | and ¬ symbols. Well, there must be *some* reason…
Thomas Thurman said,
March 9, 2012 @ 4:03 am
Is she doing this on purpose?
[(myl) Dunno — you could check her other posts at The Atlantic…]
Dean Jones said,
March 9, 2012 @ 4:16 am
Those source articles have now been rbutr'd.
CB said,
March 9, 2012 @ 6:13 am
And then, not everyone is using a QWERTY keyboard. French AZERTY keyboards have quite a lot of letters shuffled around, for example. What about those?
[(myl) You'd have to check French word-valence norms…]
RW said,
March 9, 2012 @ 6:55 am
The linear fits to the valence against RHS advantage data certainly don't look at all suggestive of a relationship. But what if you were to calculate the average and standard deviation of the valence for each value of RHS advantage, and plot that against RHS advantage? It might reveal a clearer relationship.
[(myl) Knock yourself out. (Fields are word, RSA, mean valence estimate, stdev of valence estimates.) But note that each word's valence estimate also comes with a standard deviation (because it's the mean of many subjects' judgments). And also note that this is an example of the kind of statistics-shopping that Simmons et al. worry about.]
Leonardo Boiko said,
March 9, 2012 @ 7:42 am
A friend once noticed an unexpected feature of “wget”, a Linux command to download files from URLs: It can be typed with the left hand only. This frees you to select an URL from the browser with the mouse in the right hand, then paste it in the terminal window.
At the time I compiled some short lists of left-handed English words, right-handed words, and alternated words (i.e. those which alternate one letter from each hand, which I find gives them a pleasurable typing rhythm).
Toma said,
March 9, 2012 @ 8:17 am
Then I wonder why Polk isn't a more popular US President.
[(myl) A good example of why really weak aggregate effects (here, an effect that at best is explaining about a tenth of a percent of the variance in valence judgments) shouldn't be assumed to tell us anything about individual cases.]
Pete said,
March 9, 2012 @ 8:39 am
Also, on what basis have they decided which keys are left-side and which are right-side? The old method of touch-typing presumably. But how many people actually use this method nowadays?
Other than professionally-trained secretaries and the like, most people probably use an ad-hoc two- or three-fingered typing method of their own invention, so there's no guarantee that the a left-side key for one person is left-hand for everyone.
Frank said,
March 9, 2012 @ 9:01 am
As for people who use Dvorak, can you do a study on 5 people? I don't think that's a big enough sample.
The astute observer will note what I have done there.
Zubon said,
March 9, 2012 @ 9:37 am
@Pete:
While I have not checked the current local curriculum, touch-typing was a required bit of schooling in my youth. Where do you get "most people probably use…"? I would contrarily expect most Americans under 40 to have at least some training in touch-typing. Psychological research tends to be conducted on American college students, a group highly likely to have formal typing skills.
Theo Vosse said,
March 9, 2012 @ 9:42 am
Thanks for doing this. It's just too absurd to take seriously. The sad thing is: it has been reviewed and published. Not that I mind that such a small effect gets published –that's just risk of the trade–, but I do mind that authors are allowed to publish unwarranted conclusions. Apparently, the authors do not doubt the outcome. Jasmin told Wired: "If it's easy [to type the word], it tends to lend a positive meaning. If it's harder, it can go the other way", and “Technology changes words, and by association languages. It’s an important thing to look at.”
JR said,
March 9, 2012 @ 10:03 am
Seems like any right-hand bias would be counteracted by the fact that it's far easier to orient your left hand on the keyboard: The right pinky orients itself to control keys like Enter and Delete, and abuts a bunch of keys you never want to press, like []\\, whereas the left letter keys are right next to the edge.
RW said,
March 9, 2012 @ 10:35 am
Thanks for the link to the data. I calculated the mean and standard deviation for each value of RSA, plotted that, and found that the r² value is still not very large, but much higher than that for the unaveraged data, at 0.051. Linear fitting gives a line with a gradient not statistically different from zero (0.02+-0.06).
I also calculated the average and standard deviation of the valence for all words with RSA=0. They are 5.0+-2.3 and 5.2+-2.3 respectively.
I think that averaging the data is more meaningful than analysing the raw data, but it doesn't reveal any compelling sign of the claimed relationship. A more sophisticated approach might be to identify other factors which affect the valence rating and then do multiple regression.
As an aside I was amused to see that they censor words in their Appendix D, e.g. f**kface and sh*tty. This seems very prudish and strange. Not that there is any ambiguity about what letters are missing but it still seems weird to obfuscate your data in an academic context like this.
Kyle said,
March 9, 2012 @ 10:55 am
For what it's worth, my personal experience is that p-values on correlation statistics are known to be liberal for large samples, to the point that you usually get a significant correlation and a miniscule coefficient. For this reason, I report coefficients (which would have sunk this study in review, presumably), but rarely if ever the p-values. I also would suggest that if null results aren't publishable, tiny correlations with no plausible causative story should be excluded too.
Google reveals no evidence that Casasanto and Jasmin have any training in the discipline of linguistics and they are not affiliated with any department of linguistics, suggesting they should be described as psychologists instead. Plenty of people, not just linguists, study language.
DavidO said,
March 9, 2012 @ 10:55 am
@Bobbie:
It's my understanding that QWERTY was designed to that the hands are constantly alternating, rather than have mostly letters on the one side be activated, which would tend to cause jams on the early mechanical typewriters.
It's completely moot in the electronic age, to be sure.
micah said,
March 9, 2012 @ 11:27 am
I think it's also worth noting that this:
People responsible for naming new products, brands, and companies might do well to consider the potential advantages of consulting their keyboards and choosing the 'right' name.
wouldn't really follow even if the effect were real, unless the namers themselves were immune to the effect.
Predestination for thee but not for me…
John Roth said,
March 9, 2012 @ 11:29 am
The QWERTY vs Dvorak myth seems to be one of those myths that simply perpetuates itself regardless of the number of times it's bashed over the head, somewhat similarly to the Eskimo words for snow myth. As I understand it, almost every element of the standard story is wrong. Here's one fairly thorough reference: http://reason.com/archives/1996/06/01/typing-errors . The actual typewriter analysis is in parts 2, 3 and 4; 1 and 5 are economics.
Joe1959 said,
March 9, 2012 @ 12:55 pm
@Zubon
I wonder what proportion of the world’s population, when saying "most people", are picturing "Americans under 40" ?
Michael Roberts said,
March 9, 2012 @ 1:08 pm
I see no discussion or verification at all of what seems to be the central claim of the article – that "right-handed letters are easier to find". Is that even true? Wouldn't you want to do some kind of timing experiment among proficient typists and less-proficient typists or something?
It seems like a pretty huge omission to me.
marie-lucie said,
March 9, 2012 @ 1:37 pm
The right-hand letters are easier to find for the same reason that JR mentioned above: there are fewer letters on the right-hand side, which includes all the non-letter signs. And given that those signs are less common than letters, the left hand actually has more work to do than the right hand when typing an actual text using the touch-typing method.
Zubon said,
March 9, 2012 @ 2:05 pm
@Joe1959
In most contexts, few. In the context of English-speaking persons who use QWERTY keyboards regularly? Many. In the context of English-language psychological research subjects? As I said, those are disproportionately American college students, who tend to be Americans under 40.
Svafa said,
March 9, 2012 @ 2:36 pm
I'm with others speculating what makes "right-handed letters easier to find". In my experience, left-handed letters are easier to type as my left hand is used more often when typing due to the right hand being used predominantly with the mouse. H, Y, and N have gradually become left-handed letters for me, and I typically shift letters with the left hand, even when it's something like Q or A – Z is the only one I find awkward, possibly due to the little use the letter sees in general. I tend to find left-hand dominant words easier and quicker to type than their right-handed counterparts, and always get a sense of excitement when I stumble upon one while typing.
But that's also coming from someone with a lot of experience typing and who spends in surplus of 60 hours a week in front of a keyboard. I suspect their data collection used more average typists with less experience. That they refer to "finding" the keys makes me wince on its own.
john said,
March 9, 2012 @ 2:45 pm
I'm right handed, but I use the mouse with my left hand. Sometimes, I also type entirely with my left hand if my right hand is doing something else, for example using a spoon to feed me.
LDavidH said,
March 9, 2012 @ 3:40 pm
And I type all letters with my right hand, using my left only for the SHIFT key. Idiosyncratic, indeed, but there you go.
Michael Roberts said,
March 9, 2012 @ 5:14 pm
Oh, I can also think up intuitive ways that right-hand letters could be said to be easier to find, but until somebody measures how much more easily right-hand letters are actually found, then I'm not convinced that they actually are.
a George said,
March 9, 2012 @ 5:20 pm
Even though anybody may use any keyboard in a hen-picking fashion, the only real users of the QWERTY keyboard are touch typists, just like the only real users of the legal stenography machines (e.g. Stenotype (TM)) were the legal stenographers. Now, I wonder how many touch typists regularly write words like "fuck", 'not to mention "woohoo," "woo," "woow," "wowow," and "wowww."' (to quote Steve Kass, above). Having an "old" outlook, I would expect these words to belong much more to the thumb-writing generations.
the other Mark P said,
March 9, 2012 @ 7:28 pm
That they refer to "finding" the keys makes me wince on its own.
Indeed. I touch type, which in practice means I don't consciously think of where any of the keys are. I do it all automatically.
I suspect that the best typists, like the best readers, do it more by words than by letters. (I find it very difficult to type the word "ratio" first time, because my fingers insist on typing "ration".)
When I have to hunt and peck for some reason, I find that I end up searching the keyboard like a total n00b.
RW said,
March 9, 2012 @ 8:15 pm
Just realised that my earlier comment had a < and a > that got interpreted as some kind of tag and so a chunk of comment is missing. I should have looked at the preview. Anyway, here's the correct paragraph.
I also calculated the average and standard deviation of the valence for all words with RSA<0 and RSA>=0. They are 5.0+-2.3 and 5.2+-2.3 respectively.
Steve Kass said,
March 9, 2012 @ 11:24 pm
A bit more, from the DANEW data Mark pulled out of the pdf.
The authors considered the letter B as a right-hand letter; however, it's on the left side of my split keyboard. The effect of right-side advantage on valence (from linear regression with or without adding word length as an additional ) was weaker (and failed to reach .05 significance) when B was considered to be on the left. I couldn't duplicate the authors' exact analysis, however, because they didn't analyze the three languages separately. (They claim this was "neither required nor licensed [sic]," since "there was no significant difference in the strength of the QWERTY effect across languages.")
The effect of RSA on valence (regardless of where the letter B is put) seems to be largely driven by the low valence ratings of words with RSA advantage less than -5. While one expects some restriction of range effect when omitting outliers, omitting only the most left-leaning 5% of words reduces the already-small effect (p near .05 for the model fit) to nothing (p=.399 or p=.744, depending on where B goes).
I uploaded a scatter-bubble plot of the weighted (by number of words) mean valances against right-side advantages (B to the left, I think) here.
Disclaimer: My name has a right-side advantage of -7 (regardless of where B is put), but I'm trying not to take any of this personally.
[(myl) Neat! But at least in the passage that I quoted from their paper, the authors (along with all the touch-typing manuals) treat 'b' as a left-side letter:
Where do you find that they categorized it on the right? (Note however that both in their 2011 paper and in the 2012 paper they substitute 'y' for 'v' in their left-hand list, so that 'y' occurs both on the left and on the right, while 'v' doesn't occur at all. It's not clear whether their code also makes this mistake…)
If you're still interested, personally or not, the ANEW valence data is here (pulled from the .pdf of Bradley & Lang 1999; same format of word, RSA, valence mean, valence stdev). Bradley & Lang also give the male and female data separately.]
Pharmamom said,
March 10, 2012 @ 4:17 pm
I am an adept touch typist, except for this annoying iPad virtual keyboard, and I, too, adore left-hand dominant words. Something about the arrangement of the right-hand letters is awkward. I think it is because o, p and l are typed with my least dexterous fingers, and less commonly used than a and s, so I get less practice.
And my kids are taught touch typing, or "keyboarding," monstrous neologism that THAT is, in 5th and 7th grades.
Steve Kass said,
March 10, 2012 @ 4:19 pm
Oops. You're right about B. I can only guess that I was thrown by the newline in the PDF version of the paper that occurs immediately before the last two left-side letters (which are listed incorrectly as "y,b" instead of "v,b"), so I carelessly assumed the authors put Y and B on the same side of the keyboard – that and the fact that before I purchased my first split keyboard about 15 years ago, I had always typed B with my right hand… I do seem to have gotten V in the right place, at least.
Thanks for the additional data. I'll take a look (Your Acrobat grab of DANEW contains a few ¥ characters where ï or x should appear, by the way. I only noticed that after running my tests, but there are few enough that it should make little difference.)
Steve Kass said,
March 10, 2012 @ 4:31 pm
FYI: I think V and Y are switched in your RSA calculation here…
J said,
March 10, 2012 @ 7:27 pm
I'm so glad someone wrote this up. When I heard about the "QWERTY effect" I thought it was the most ridiculous this I'd ever heard.
That's what SHE said,
March 10, 2012 @ 7:42 pm
Thanks for gathering the datasets! It's always good to go back to the original data. In that spirit, I fitted a regression model to the Dutch valence data using the raw letter frequencies as explanatory variables. In other words, the parameters of the model are the intercept plus the 25 letters in the corpus (a-z without q or x, plus e with diaeresis). In the resulting model, the only significant variables were the intercept, and the frequencies of r, j, s, and e. The adjusted R^2 is 0.025. Of course, this model has many more degrees of freedom than the simple RSA model. So I also fitted a model with one degree of freedom, using the frequency of r as the only explanatory variable. The inclusion of this variable was highly significant and the adjusted R^2 was 0.0065. Based on significance, I suppose one could argue for an "r effect", but since the effect sizes are so small, this is not worth arguing about.
Steve Kass said,
March 10, 2012 @ 9:10 pm
And more…
I'm pretty sure the ANEW data came from three sources. The justification for using them seems to be that the valence data had already been collected, not that they were a representative sample from which to make a sound inference.
You can click to view a scatterplot here (valence vs. RSA) that shows the sources in colors with separate least squares fit lines.
As I mentioned before, Jasmin and Casasanto never analyzed ANEW (or DANEW) alone; the simple regression I ran gave no statistically significant dependence of valence on RSA. (A slope of zero was well within the 95% confidence interval.)
What's still interesting, then, if there's no QWERTY effect? As it turns out, what minuscule effect there might be comes largely from an artifact: words ending in -ed. This got me to realize that whether or not a QWERTY effect showed up in the data, it would be wrong to generalize from this data about such an effect.
The circled points indicate the 53 ANEW words ending in -ed. Almost all of them are from one of the three sources (the blue dots). That source list contained only nouns and adjectives; verb forms only appear masquerading as adjectives in their past tense.
This choice, to put verb forms in the past tense, might have made perfect sense for the initial purpose of the word list. Adding -ed to a verb probably doesn't change its valence by much, yet it does decrease its right-side advantage by 2, and that biases the current study. Curiously (or perhaps not, if verbs more than nouns or adjectives elicit deep negative emotion – there must be research on this, he wondered cynically…) valences were disproportionately low for this collection of words – there were many words like anguished, burdened, displeased, distressed, and shamed, but fewer like admired and elated.
The bottom line? The word lists used by Jasmin and Casasanto, particularly the blue one, were most likely never intended to be representative of the English language. And they aren't (just like woohoo, woow, and wowww, aren't typical post-1900 English words). The words in these lists were specifically chosen to contain emotional content for studies. This is clear (for the blue list) from the scatterplot; most of the blue dots are high or low on the chart.
That's what SHE said,
March 10, 2012 @ 9:21 pm
Another simple experiment. I fitted a model for the English valence mean with two explanatory variables: the number of left-hand letters and the number of right-hand letters in each word. I did that with letters V and Y where they belong, as well as with their sides switched. In both cases, for the model valence ~ left + right, the intercept is highly significant, left is (barely) significant, and right is very far from significant. The simpler model valence ~ left accounts for more variance, the fit is significant, and the sign of the coefficient of 'left' is negative. On the other hand (heheh), the fraction of variance explained is tiny and the magnitude of the coefficient of 'left' is close to zero, so any putative "sinister left hand effect" (heh) is still tiny. In the valence norming dataset, a breakdown of raters into left-handed, right-handed, ambidextrous, amputee, hemiplegic, quadriplegic, etc. would also be helpful.
That's what SHE said,
March 10, 2012 @ 9:25 pm
@Steve Kass: Nice find regarding the -ed forms! Corroboration: When I fitted a model with 26 individual letter frequencies as explanatory variables to the English data, the frequency of 'd' was by far the most significant variable after the intercept. This didn't make any intuitive sense to me at first, but your finding explains this satisfactorily. (The other significant letters are 'r', 's', and 'w'. What's the story with 'w'?)
Steve Kass said,
March 10, 2012 @ 10:23 pm
@TWSS: I can't see any obvious explanation for the W effect. Regarding the D effect, though, it's not all about -ed. Words from ANEW that begin with d turn out to have strikingly lower valences than words beginning with any other letter – more than a full point on average, an effect much larger than the -ed effect or the contains-D effect. Do you suppose the Democratic party leadership is aware of this?
Graeme said,
March 11, 2012 @ 2:52 am
Maybe in the days of the Olivetti, when touch meant thump…
Pre-schoolers do seem to gravitate to simpler versions of their names; whether it's because of ease of spelling or because relatives use the diminutive is another matter.
Pepijn van Erp said,
March 12, 2012 @ 3:33 am
It's interesting to see that the effect is significant if you look at the three lists (ANEW, DANEW & SPANEW) together but not in ANEW and DANEW alone. The question rises if the lists can be seen as indepent. Many words don't change that much in translation and therefore not so much in RSA as well (eg. "aggressive – agressief – agresivo").
The researchers seem to have let go of this link between the lists in their analysis. If the hypothesis would be true, you would also expect to see a relation between a change in RSA due to translation and a change in valence between the original word and its translation.
It would be easy to do the calculation if the lists were available with the translation links intact, but the list I found were alphabetized ;-(
Bestaat er echt een QWERTY-effect? said,
March 13, 2012 @ 3:43 am
[…] woorden in ANEW kunnen liggen (het gaat om 1043 woorden). Mark Liberman onderzocht het ook in een blog op language log. Hij deed de analyse zelf voor de ANEW en DANEW lijsten apart en dat leverde vergelijkbare […]
The Bad Science Reporting Effect - Lingua Franca - The Chronicle of Higher Education said,
March 14, 2012 @ 11:02 pm
[…] late on March 8, Mark Liberman at Language Log had re-examined the relevant statistics, noting that the effect is extremely weak. It could explain […]
Typen heeft invloed op betekenis woorden - Scientias.nl said,
March 15, 2012 @ 4:33 am
[…] niet zulke overtuigende resultaten als de onderzoekers in hun paper opwerpen. Liberman schrijft in een blog over zijn werk: "Ik heb het idee dat de kracht van het effect – als het bestaat – […]
De l’effet QWERTY… | En Tous Cas… said,
March 15, 2012 @ 8:38 am
[…] d'autres linguistes avaient eu la même réaction que moi.Mark Liberman a d'ailleurs testé la méthodologie utilisée dans cette recherche et est arrivé à la même conclusion… avec des […]
Bad Statistics, Worse Science Writing « Factpinions עוּבְדֵעוֹת said,
March 15, 2012 @ 9:28 am
[…] keyboard tend to have a more positive mental association with them than left-hand words – was demolished within days of its […]
Daniel Casasanto said,
March 16, 2012 @ 5:42 pm
The Robustness of the QWERTY Effect
It seems our study has caused quite an uproar on the Language Log (and the blogs that feed off of it).
We’re not concerned with Liberman’s subjective evaluation of the QWERTY effect’s size or of our study’s importance. We are concerned with his misrepresentation of the reliability of our findings.
Here’s the short version of our reply: The QWERTY effect is reliable. Replication is the best prevention against false positives. In this paper, we demonstrated the QWERTY effect *six times*: in 5 corpora (one of which we divided into 2 parts, a priori), in 3 languages, and in a large corpus of nonce words. We’ve replicated the effect again subsequently, showing it a seventh time, in a fourth language (see our full reply, URL below). In fact, we even find the effect replicated again (showing it for an eighth time) in the corpus by Dodds and al., when the analysis is appropriately controlled.
The analyses that Liberman presents on his blog post were performed, reported, and interpreted incorrectly. One of them is tantamount to flipping a coin 3 times and trying to make scientific inferences based on the results.
There’s a reason why scientific results go through peer review, and why analyses are not simply self-published on blogs. If there were a review process for blog posts, or if Liberman had gone through legitimate scientific channels (e.g., contacting the authors for clarification, submitting a critique to the journal), we might have avoided this misleading attack on this paper and its authors; instead we might have had a fruitful scientific discussion.
For a more detailed reply, see:
http://www.casasanto.com/Site/QWERTY.html
Daniel Casasanto and Kyle Jasmin
Does QWERTY Affect Happiness? | onehappybird said,
March 19, 2012 @ 7:22 pm
[…] has taken place between Mark Liberman of the Language Log blog and the authors of the study. See post1, post2, the response from J&C, and the response back. After being informed by (our) Peter […]
[links] Link salad does the walk of life | jlake.com said,
June 14, 2012 @ 2:00 pm
[…] The QWERTY effect — Language Log on the supposed positive valence of rightside letters. […]
Keyboard layout’s effect on lexicon? | Amplab said,
November 22, 2012 @ 5:53 am
[…] requiring easier/fewer finger movements (in the same way as we tend toward economy in speech). This linguist summarizes and refutes the theory, arguing that the influence of keyboard arrangement on word […]
Study: Keyboards Are Influencing What You Name Your Baby | HELIK.ES said,
May 10, 2014 @ 11:47 am
[…] psychology professor from the University of Chicago is doubling down on research that caused a great kerfuffle among linguists in 2012. In Daniel Casasanto's previous paper, he presented the QWERTY […]