Jill Abramson's voice
« previous post | next post »
Ken Auletta, "Changing Times: Jill Abramson takes charge of the Gray Lady", The New Yorker 10/24/2011:
The first thing that people usually notice about Jill Abramson is her voice. The equivalent of a nasal car honk, it’s an odd combination of upper- and working-class. Inside the newsroom, her schoolteacherlike way of elongating words and drawing out the last word of each sentence is a subject of endless conversation and expert mimicry. When she appeared on television after her appointment as executive editor, the blogger Ben Trawick-Smith wrote, “Speech pathologists and phoneticians, knock yourself out: what’s going on with Abramson’s speech?” He was deluged with responses. One speculated that, like a politician, she had trained herself to limit the space between sentences so that it would be hard to interrupt her; another said she had probably acquired the accent in an attempt to not sound too New York while she was an undergraduate at Harvard. The writer Amy Wilentz, a college roommate of Abramson’s, has said that the accent probably has something to do with trying to sound a bit like Bob Dylan.
The cited blog post is "Jill Abramson’s Accent", The dialect blog 7/28/2011. LLOG readers were apparently all playing beach volleyball that week, and so no one drew my attention to Ben Trawick-Smith's plea for assistance.
Auletta and Trawick-Smith are talking about Ms. Abramson's performance in a PBS NewsHour interview, "New York Times Names First Woman to Executive Editor Job", 6/2/2011:
The features that caught their attention are (I think) on display in Ms. Abramson's response to Jim Lehrer's first question, "what does it mean to you to become the executive editor of The New York Times?":
It means the world to me uh I grew up
uh here in Manhattan. And uh
The New York Times was worshipped in my family. And what
The Times said was true was the truth. And so,
uh I became an avid reader of the paper as a young schoolkid. And
it seems scarcely believable to me that I will
hold the top uh ed- editorial position in the newsroom.
In fact, two of the unusual features of her vocal style are on display in her first six words, "It means the world to me uh":
![]()
The first feature is the long, low, loud, level tail of the phrase — 1.048 seconds of essentially level pitch at the bottom of her pitch range, which is about 141 Hz, and at an average sound level only about 2 dB below the average level of "world", the most prominent syllable in the phrase.
The second, even more unusual feature, is the low frequency (about 23-24 Hz) amplitude modulation of this stretch of speech. You can see it in the wide-band spectrogram as a pattern of waxing and waning intensity at a rate corresponding to about 1/6 of her fundamental frequency, so that the fine vertical lines representing her pitch pulses get darker and lighter in groups of six or so. I've adjusted the dynamic range of the plot to make this feature saliently visible:
![]()
In the frequency domain, 141/6 = 23.5 Hz; in the time domain, 6*.0071 = .043 seconds.
The human ear can't resolve repeated things happening faster than about 15-16 times a second (corresponding to a period of about 0.06 seconds) as sequences of events in time, but rather hears them as low frequency pitches. If you create a sequence of clicks happening every 0.050 seconds (= 20 Hz) and listen to the result, you'll hear a sustained low-frequency buzz rather than a sequence of individual sounds.
So Ms. Abramson's 20-25 Hz phrase-final amplitude modulation of her 140-145 Hz fundamental frequency is heard as a sort of superimposed infrasound. (Technically "infrasound" should be below 20 Hz, but this is close.) 140 Hz is not unusually low for the bottom of an adult woman's pitch range — but 20-25 Hz is low for humans of any kind.
It's quite common to see phrase-final low-pitched stretches in which alternate pitch periods start to vary systematically in amplitude. This can result in an abrupt apparent doubling in period (and a corresponding halving in fundamental frequency). A clinical variant of this is called "diplophonia", but most people do it sometimes — it's a natural consequence of oscillation in non-linear physical systems, and is a specific instance of the phenomenon of "period doubling" much loved by complexity buffs. I've sometimes seen period-tripling. But this is first time that I've ever seen such a large-factor amplitude modulation so stably superimposed on a speaker's sequence of pitch pulses.
These two features — long, low, loud phrasal tails with near-infrasonic amplitude modulation — are seen again and again in Ms. Abramson's side of this interview. Here's a spectrogram of the last two syllables ("and uh") of the next phrase from her interview:
I grew up here in Manhattan and uh
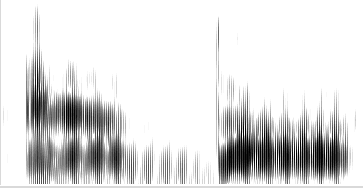
The ratio between the fundamental and the infrasonic modulation is variable — it seems to be more like 8-to-1 towards the end of this sample — but the general pattern remains the same. Her long/low/loud phrase endings also often shift into "vocal fry", which is a kind of chaotic oscillation; thus the pronunciation of the second syllable of "schoolkid" in the passage quoted above:

Listening to a sample suggests that the same features will be found in other available records of her speech (e.g. the Book Review podcast for 10/142011, "Jill Abramson’s ‘Puppy Diaries’" (link to mp3) and many YouTube videos).
There are some other interesting features as well, but these two are what struck me most forcefully in a quick peek.
Jerry Friedman said,
October 18, 2011 @ 1:50 pm
LLOG readers wish.
What could cause something like that infrasonic modulation? A muscle spasm somewhere along the line?
A quick look found Ladefoged and Maddieson saying the typical frequency of "apical trills" (please don't think I know what I'm talking about) is around 25 Hz, and quoting an example at 20 Hz. Could some sort of trill-like phenomenon be going on?
Or is there a reason you didn't speculate on the mechanism?
[(myl) I didn't speculate about the mechanism because I don't have anything very concrete to say about it. One thing that it can't be: oscillatory muscle action, since human muscles can't cycle much faster than 13 Hz or so. What it almost certainly is, pretty much by definition: some kind of limit cycle in a dynamical system. The question is, what are the components of that system, and how do they interact? And why don't they interact that way in (most) other people's voices?
Almost certainly, the core of the system is the complex 3D oscillation of the vocal cords, determined by tissue elasticity, tissue mass, and aerodynamic forcing. We know that this system undergoes period doubling on the way to (non-periodic) chaos (called "vocal fry" in this case). But the lungs, bronchial tubes, etc. might be involved; so might complex airflow in the supralaryngeal space, where interesting vortex patterns have sometimes been observed. But at this point we're way beyond what I know or understand, in general as well as with respect to this particular case.
Trills are generally also well modeled as myoelastic/aerodynamic interactions, but I would be shocked if any non-laryngeal structures were moving in sync with the modulation in this case.]
Jerry Friedman said,
October 18, 2011 @ 1:57 pm
Oh, okay, "apical" means "tip of the tongue". Should have been obvious.
GeorgeW said,
October 18, 2011 @ 1:59 pm
I haven't spent much time in NYC or among New Yorkers, but what caught my attention was the nasal quality. It seems she steps this up a notch, or maybe doesn't turn it down in public speaking.
[(myl) In my experience, "nasal quality" almost always means "low-frequency sound qualities that I don't expect, from people that I don't sympathize with".]
GeorgeW said,
October 18, 2011 @ 2:24 pm
myl: Hmm. I really don't think that "I don't sympathize with her." Are you saying that her speech has no more actual nasality than, say a Chicagoan?'
[(myl) "Nasal" is usually a negatively-evaluated term, so people tend not to use it for speech that sounds "good" to them. But the acoustic effects of nasal-track coupling are extremely variable, so there's no way to measure it in the general case from acoustic data alone. I'd be willing to wager, though, that if we could fit Ms. Abramson and some control Chicagoan up to a device measuring nasal airflow, or velum position, or both, we would not find that the regions that sound "nasal" to you actually involve more coupling of the nasal cavities into the vocal tract.]
James said,
October 18, 2011 @ 2:28 pm
I don't hear the low sound at all. Is it hard to hear, or am I not listening in the right place?
[(myl) I'm not sure what you should expect to hear. My experience was that I heard her phrase-final pitches as very low — but when I looked at the pitch tracks, they were only about 140 Hz, which is pretty much what we expect for an adult woman. So I asked myself, why does it sound low to me? And what I came up with was the low-frequency (~25 Hz) modulation.
I guess it's possible instead that her phrase-final pitches sounded low to me because they're flat, extended, and fairly loud. And maybe I'm not hearing the low-frequency modulation at all; but (without much evidence) I don't think so.]
McLemore said,
October 18, 2011 @ 6:05 pm
The only time I've heard anything like that long low creaky voice was when four men, all Harvard undergrads with linguistic PhDs from MIT, were talking in a social / professional context, giving opinions about some linguistic phenomenon under discussion, and kept lowering their chins ever lower by turn. I mean, OK the lengthening wasn't as long, but hey — 2 out of 3. (Liberman, you were one of those guys! Other LLoggers were present; you know who you are.) So I'm tempted to speculate that Abramson, as a Harvard student, co-opted a masculine status symbol that operates under the radar of consciousness — except that she said her mother talked the same way…
Harold said,
October 18, 2011 @ 6:42 pm
Correct me if I am wrong, but I thought a nasal sound resulted from vocal constriction, due to tension.
[(myl) No, a nasal sound results from a lowering of the velum (mainly due to relaxation of the levator veli palatini muscle), so that the nasal passages, sinus cavities etc. are coupled into the vocal tract resonance system through the velo-pharyngeal port, an opening at the top of the pharynx. When the levator veli palatini and tensor veli palatini are contracted, the velum is pulled up so as to seal off the velo-pharyngeal port and eliminate direct resonant coupling of the nasal cavities. This picture will give you a general orientation; for details, see e.g. Antoine Serrurier and Pierre Badin, "A three-dimensional articulatory model of the velum and nasopharyngeal wall based on MRI and CT data", JASA 123(4) 2008.]
jf said,
October 18, 2011 @ 7:20 pm
In an interview on CBS Sunday Morning from Sunday, she claims that she recognizes her speech patterns are unusual, but that she sounds exactly like her older sister.
http://www.cbsnews.com/stories/2011/10/16/sunday/main20121082.shtml?tag=cbsnewsTwoColUpperPromoArea
"I have an older sister who sounds, unfortunately, exactly like me, and we sound like our mother did. So all I can say is, it's in our genes."
GeorgeW said,
October 18, 2011 @ 8:20 pm
@Harold: Catford ("A Practical Introduction to Phonetics") says, "In nasalized sounds, the nasal port is open (exactly as for nasals), but at the same time the passageway though the mouth is also open, so that the air flows out though both mouth and nose."
John said,
October 18, 2011 @ 8:43 pm
A native Brooklynite, I noticed her pronunciation of "Manhattan" which has a clear enunciation (apologies for the lack of technical terminology) of the -a- in the first syllable, which I expect to be more of a schwa. So much so, that I often use this as a way of tagging non-natives. I suspect she was hyper-correcting for the national audience.
But maybe that's my "outer-boroughness" coming through.
John said,
October 18, 2011 @ 8:50 pm
@jf: "I have an older sister who sounds, unfortunately, exactly like me, and we sound like our mother did. So all I can say is, it's in our genes."
Um, what? Am I misinterpreting her logic, or is the editor of this newspaper-of-record seriously suggesting that she believes that linguistic behavior patterns are 100% hereditable, with no possibility that growing up together in the same environment might have some influence on how one speaks…?
J. Goard said,
October 18, 2011 @ 9:29 pm
The sociology involved in referring to someone's speech as "nasal" sure is fascinating. To those here who are having difficulty envisioning (metaphor intended) what actual excess nasalization sounds like, just picture (there I go again!) a Deaf person who's learned to produce an auditory language by moving the tongue and lips, but has that constant musical buzz. That's nasalization (leaving the velum open) — obviously different from the kinds of accent to which the term is popularly applied.
Ø said,
October 18, 2011 @ 9:43 pm
John,
"Manhattan" for "M'nhattan" did not strike me, a non-native, as odd, but "worshupped" for "worshipped" did.
Guy said,
October 18, 2011 @ 10:05 pm
@James: I don't hear the low sound either but I can hear a series of very rapid clicks. The last second or so in the second of the three audio clips was the easiest place for me to pick it out.
I think I hear it as clicks rather than a tone because it's something my voice does sometimes, particularly the morning after a night out. I'm guessing that having experienced producing the sound as clicks when I hear someone else doing it it gets modelled as clicks in my head even though they're coming fast enough that they would otherwise be perceived as a constant tone. I'm no neurolinguist though.
l find that with a bit of mucking around I can slow it down until I can make the individual clicks come separately or speed it up until it becomes a tone with a definite sense of pitch.
Rod Johnson said,
October 18, 2011 @ 10:11 pm
@John: "Um, what? Am I misinterpreting her logic, or is the editor of this newspaper-of-record seriously suggesting that she believes that linguistic behavior patterns are 100% hereditable, with no possibility that growing up together in the same environment might have some influence on how one speaks…?"
No, she's not seriously suggesting that, she's using "genes" in a loose way to talk about her family, just like millions of other people do every day when they say things like "she gets it from her father." We're not talking about peer-reviewed research here.
jk said,
October 18, 2011 @ 10:20 pm
When I think of a "nasal" voice, I think of Arnold Horshack on "Welcome Back, Kotter." More of bugle than a buzz. Is that right?
I would describe Abramson's voice as buzzing, on top of a drone. Not the kind of dry, clicky notes of a Henry Kissinger. More like a William F. Buckley, although my memory is that his buzzes were less integrated into his sentences and more frequent in between them.
Not to throw stones because I'm no turtledove myself, but her voice sounds like a bagpipe's low notes.
And, John, I would imagine that "it's in our genes" was just a casual way of saying that it runs in the family, as when my wife said tonight that she "got the travel gene." Even the editor of the Times is allowed to speak metaphorically.
Jerry Friedman said,
October 18, 2011 @ 10:57 pm
@MYL: Thanks for the comments. It was interesting that you could rule out or almost rule out my speculations. And I've been learning about creaky voice and vocal fry.
Adam said,
October 19, 2011 @ 3:24 am
We play beach volleyball? Did I miss a memo?
GeorgeW said,
October 19, 2011 @ 5:30 am
@J. Goard: "The sociology involved in referring to someone's speech as "nasal" sure is fascinating."
This is the first time I have heard that nasalization is "usually negatively evaluated." Maybe, it is a natural aversion to keep us away from those with colds (or the French :-)
[(myl) A bit of evidence from the Google Books ngram dataset (American English): "sweet low voice" has 561 hits, while "sweet nasal voice" has 0. Rich, strong, lovely, pleasant yield 88, 61, 51, and 46 respectively in the context __ low voice, but all of those have 0 hits in the context __ nasal voice.
In contrast, thin, shrill, flat, harsh, and rasping have 82, 81, 69, 44, and 43 hits respectively in the context __ nasal voice, but 0 in the context __ low voice.]
Mr Punch said,
October 19, 2011 @ 8:55 am
"Worshup" is what Iowans do after changing the oil.
tlcsfv said,
October 19, 2011 @ 11:53 am
I have two words to describe her dialect: "Grey Gardens".
Jon Lennox said,
October 19, 2011 @ 2:15 pm
Abramson's voice also sounds to me like she's extending her terminal Rs longer than I would consider normal (listen to "an avid reader of the paper"). Could she be hyper-correcting a non-rhotic New York accent, or have learned from someone who was?
Dw said,
October 19, 2011 @ 2:47 pm
@Mr Punch:
Interesting: this tells me that Iowans have the NORTH vowel in "worship", rather than the NURSE vowel I would expect. Do you know how common that is in the USA?
Rod Johnson said,
October 19, 2011 @ 6:18 pm
Dw, I think Mr. Punch is alluding to the fact that some midwestern US speakers pronounce "wash" as "worsh." But I have heard people say "worship" with the [o] vowel. There are all kind of weird, idiosyncratic pronunciations going around–my father-in-law pronounces "sugar" to rhyme with "chigger."
Harold said,
October 19, 2011 @ 10:03 pm
I don't think she is making too many nasalized sounds (as in Portuguese). What I hear is a slow monotonous slow, singsong with growling rasp (buzz) on some of the vowels especially when it's the last word — as though the vocal chords had nodules or something. This kind of Louis Armstrong rasp is used in some cultures to indicate masculinity — as in Japan — or possession by a spirit. I think it is likely that in this case it is a familial trait and doesn't indicate anything cultural, particularly. I am not a speech pathologist, but it is not very pleasant to listen to. When she begins to answer a question her voice is more pleasing and natural, also higher pitched.
Jonathan Badger said,
October 20, 2011 @ 12:43 am
@Rod Johnson
Yes, my grandmother, born before the First World War in Kentucky and living most of her life in Illinois, always pronounced "Washington" more or less like "Worshington".
John Kingston said,
October 20, 2011 @ 5:29 pm
I wonder if the modulation is a rather extreme form of tremolo, which is a regular variation in level. Now, giving it a name doesn't explain how she does it, but in two-reed instruments it's a product of tuning them slightly differently, and as a result producing beats. The question then becomes how this could be produced with vocal fold vibration, in particular, how the vocal folds could be caused to vibrate at two frequencies at once about 25 Hz apart. I haven't got a clue, but suspect that it is related to the low F0 she produces at the same time.
Dakota said,
October 21, 2011 @ 6:27 am
I wonder if this is at all similar to the Asian dual-tone chanting.
Dakota said,
October 21, 2011 @ 6:56 am
@Rod Johnson & Jonathan Badger
In some areas of the Dakotas, the wash/Washington words are sometimes also pronounced warsh, to rhyme with harsh. Hence the (non-funny and probably offensive) joke: (looking at the ground) "Bug?" "No. Squashit."
Rod Johnson said,
October 23, 2011 @ 1:40 pm
It's a North Midland thing, roughly. Here in Michigan (which for the most part firmly Northern) it's rare, but south into Ohio and Indiana, I hear it often. I would hypothesize that those areas of the Dakotas you mention are mostly toward the south?
Audrey W. said,
September 21, 2012 @ 11:55 am
I hear the vocal 'fry,' the elongated vowels, and all the 'uhs,' but otherwise I don't hear her voice as especially unusual. I have no idea why it's less unusual for me than for the other posters; I'm not from NYC, and neither is anyone in my family.
Tanya said,
January 22, 2013 @ 9:17 pm
I noticed the features others have mentioned. Almost sounds to me as if she has been through an intensive fluency (stuttering) program. One in which they require one to speak in monotone, keeping the vocal folds on in order to avoid blocks, repetitions and prolongations.
She also appears to have limited upper and to a lesser extent lower, lip range of movement.
I have had patients with odd vocal patterns who have sought out services for therapy. Not common, but I have seen them.
Tanya said,
January 22, 2013 @ 9:22 pm
Ahhh . She was in a car accident in 2007. It did almost have a neurogenic quality to it.
Daisy said,
May 20, 2014 @ 11:41 am
I'm kind of surprised that no one here has wondered about the autistic quality of not only her voice, but her flattened aspect in general. My guess is that she's somewhere on the autism spectrum. Certainly very bright, but not high functioning socially. My guess would be Asperger's Syndrome.
Liz Evans said,
July 16, 2014 @ 6:43 pm
Jill Abramson's voice is rather monotone. As a former violinist (in the Harvard orchestra and in Switzerland), I have a keen ear for musical tones.
It seems that most of her vocal tones are around the low "G" of a violin, with only a few variations.
Perhaps she had measles or some other illness when she was younger, that left her partially deaf?
Kate said,
July 17, 2014 @ 1:25 am
She's another alien. Like Rahm, James Carville and that creepy San Diego mayor.