Authors vs. Speakers: A Tale of Two Subfields
« previous post | next post »
The best part of Monday's post on the Facebook authorship-authentication controversy ("High-stakes forensic linguistics", 7/25/2011) was the contribution in the comments by Ron Butters, Larry Solan, and Carole Chaski. It's interesting to compare the situation they describe — and the frustration that they express about it — with the history of technologies for answering questions about the source of bits of speech rather than bits of text.
The U.S. National Institute of Standards and Technologies (NIST) has been running a formal "Speaker Recognition Evaluation" (SRE) series since the mid-1990s. There were older planned evaluations of a similar sort going back a decade before that — the 1987 King Speaker Verification corpus was used in such evaluations starting in the last half of the 1980s, and the 1991 Switchboard corpus, though it has been used for many things, was originally collected and used as for speaker identification research and evaluation.
So we've had about 25 years of systematic development and open competitive evaluation of methods for determining or validating speaker identity.
Now, if you know the history of forensic speaker identification, you'll object that allegedly scientific methods in that area go back much further. You might cite, for example, Lawrence G. Kersta, "Voiceprint-Identification Infallibility", J. Acoust. Soc. Am. 34(12) 1962:
Previously reported work demonstrated that a high degree of speaker‐identification accuracy could be achieved by visually matching the Voiceprint (spectrogram) of an unknown speaker's utterance with a similar Voiceprint in a group of reference prints. Both reference and unknown utterances consisted of single cue words excerpted from contextual material. An extension of the experimental showed identification success in excess of 99% when the reference and unknown patterns were enlarged to 5‐ and 10‐word groups. Other experiments showed that professional ventriloquists and mimics cannot create voices or imitate others without revealing their own identities. Attempts to disguise the voice by use of various mechanical manipulations and devices were also unsuccessful. Experiments with a population expanded over the original 25 speakers showed that identification success does not decrease substantially with larger groups.
Kersta published a similar paper in the august journal Nature ("Voiceprint Identification", Nature 12/29/1962). But you might also recall the controversy that Kersta's claims caused. Thus Ralph Vanderslice and Peter Ladefoged, "The 'Voiceprint' Mystique", J. Acoust. Soc. Am. 42(5) 1967:
Proponents of the use of so‐called “voiceprints” for identifying criminals have succeeded in hoodwinking the press, the public, and the law with claims of infallibility that have never been supported by valid scientific tests. The reported experiments comprised matching from sample—subjects compared test “voiceprints” (segments from wideband spectrograms) with examples known to include the same speaker—whereas law enforcement cases entail absolute judgment of whether a known and unknown voice are the same or different. There is no evidence that anyone can do this. Our experiments, with only three subjects, show that: (1) the same speaker, saying the same words on different occasions without any attempt to disguise his voice, may produce spectrograms which differ greatly; (2) different speakers, whose voices do not even sound alike, may produce substantially identical spectrograms. As with phrenology a century earlier, “voiceprint” proponents dismiss all counter evidence as irrelevant because the experiments have not been done by initiates. But our data show that the use of “voiceprints” for criminal identification may lead to serious miscarriages of justice.
This 1960s-era controversy is described from a legal perspective in Rick Barnett, "Voiceprints: The End of the Yellow Brick Road", 8 U.S.F. L. Rev. 702 (1973-74), who concludes that
The weight which a jury might choose to attribute to voiceprint identifications may be the determining factor in a decision as to guilt or innocence. Although the courts have tended to treat general acceptance and reliability as one rather than two issues, the latter has provided a much stronger ground for denial of admissibility. Yet, adverse judicial rulings will not end the controversy as to the reliability of the voiceprint technique of speaker identification. Only further research will accomplish that end.
If you look over the documentation of the NIST Speaker and Language Recognition evaluations, you'll see a very different sort of field from the one that is evoked by the exchange between Kersta and Vanderslice — or by the comments from Butters, Solan, and Chaski. Thus NIST's "1997 Speaker Recognition Evaluation Plan", published well in advance of the 1997 evaluation, describes at length what background ("training") data is to used in preparation for the test, how the tests will be scored (using withheld "test" data), in what format results should be submitted to NIST, and so on.
This is an instance of the "common task method" developed by Charles Wayne and others at DARPA in the late 1980s, and used up to the present day to make progress in areas from speech recognition and machine translation to text understanding and summarization. For people in the speech and language technology field, it's now become second nature to expect this kind of research environment. Younger researchers, who may not recognize that things were not always this way, would do well to read John Pierce, "Whither Speech Recognition?", J. Acoust. Soc. Am. 46(4B) 1969:
We all believe that a science of speech is possible, despite the scarcity in the field of people who behave like scientists and of results that look like science.
Most recognizers behave, not like scientists, but like mad inventors or untrustworthy engineers. The typical recognizer gets it into his head that he can solve "the problem." The basis for this is either individual inspiration (the "mad inventor" source of knowledge) or acceptance of untested rules, schemes, or information (the untrstworthy engineer approach). […]
The typical recognizer […] builds or programs an elaborate system that either does very little or flops in an obscure way. A lot of money and time are spent. No simple, clear, sure knowledge is gained. The work has been an experience, not an experiment.
In this context, it may be helpful to take a look at the summary of three years of progress in speaker recognition research described by Mark Przybocki, Alvin Martin, and Audrey Le, "NIST Speaker Recognition Evaluations Utilizing the Mixer Corpora: 2004, 2005, 2006", IEEE Trans. on Audio, Speech & Language Processing, 2007:
The Speech Group at the National Institute of Standards and Technology (NIST) has been coordinating yearly evaluations of text-independent speaker recognition technology since 1996. During the eleven years of NIST Speaker Recognition evaluations, the basic task of speaker detection, determining whether or not a specified target speaker is speaking in a given test speech segment, has been the primary evaluation focus. This task has been posed primarily utilizing various telephone speech corpora as the source of evaluation data.
By providing explicit evaluation plans, common test sets, standard measurements of error, and a forum for participants to openly discuss algorithm successes and failures, the NIST series of Speaker Recognition Evaluations (SREs) has provided a means for chronicling progress in text-independent speaker recognition technologies.
[…] Here, we concentrate on the evaluations of the past three years (2004–2006). These recent evaluations have been distinguished notably by the use of the Mixer Corpora of conversational telephone speech as the primary data source, and by offering a wide range of […] test conditions for the durations of the training and test data used for each trial. One test condition in the past two years has involved the use of the Mixer data simultaneously recorded over several microphone channels and a telephone line. In addition, the corpus and the recent evaluations have included some conversations involving bilingual speakers speaking a language other than English.
A summary of the 2006 state-of-the-art can be seen in their Fig 1, which present "Decision Error Trade-off" (DET) curves for the primary systems of the 36 organizations who entered the 2006 evaluation's "core" test. Thus the best-scoring system achieved about a 2% false-alarm probability at a 5% miss rate on this test:
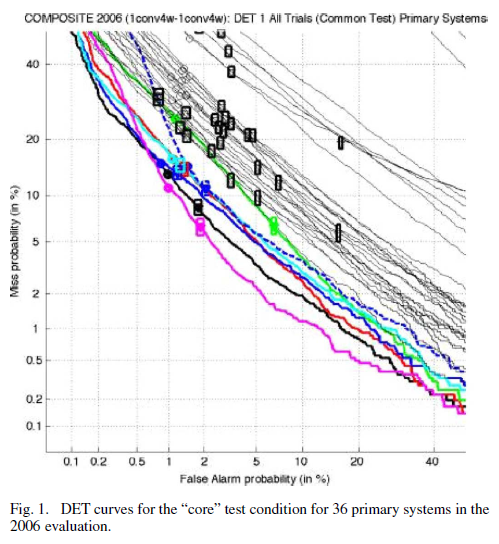
That's not to say that this level of performance would be expected under all test conditions. In fact, the 2005-2006 SRE evaluations began the testing of "cross-channel" conditions, in which a variety of different microphones and recording conditions were compared; and as Figure 12 from the same paper shows, performance in cross-channel conditions was much worse:
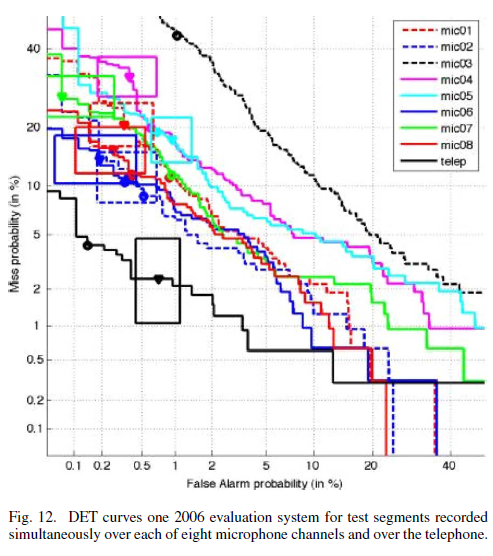
The relatively unsmooth curves and large confidence boxes of the figure reflect the relatively small numbers of trials in the 2006 evaluation for the cross-channel condition. The key point to note is the far better performance of the telephone test segment data (solid black) than that of all the cross-channel (all training was over the telephone) microphone curves. (The microphone used in the broken black curve was apparently defective.)
Although the word "science" doesn't occur in Przybocki et al. 2007 — and indeed the perspective is very much that of an engineer rather than a scientist — I think that John Pierce would be satisfied that Przybocki et al. are reporting "experiments" rather than mere "experiences".
Is there anything comparable in the field of (text-based) authorship identification? Alas, no.
Things started out well with Frederick Mosteller and David Wallace, "Inference in an Authorship Problem", Journal of the American Statistical Association 1963 (discussed in my post "Biblical Scholarship at the ACL", 7/1/2011). Mosteller and Wallace used a generally-available source of texts — the Federalist papers — and documented their methods well enough that what they did can now be assigned as a problem set in an introductory course (and sometimes is). And there have been many research publications since then.
But what is so far still lacking, IMHO, is a systematic application of the "common task method". As far as I know, none of the aspects of "authorship attribution" have ever been addressed by any of the on-going or ad-hoc organizations that have sprung up to mediate the application of this method to text-analysis problems — not TREC, nor TAC, nor CoNLL, nor anybody else. As a result, the work is more scattered and diffuse than it should be, and harder to evaluate in reference to real-world questions. There is less research than there would be, if published training and testing collections lowered the barriers to entry, and if published results on well-defined benchmark tests gave researchers a "record" to try to beat. There is less of a research community than there should be, in the absence of the forum for exchanging ideas that a shared task creates. And authorship evaluation lacks the clear community standards — for technology and for performance evaluation — that emerge from the sort of scientific "civil society" represented by the NIST SRE evaluation series.
As far as I know the International Association of Forensic Linguists (IAFL) has never tried to fill this gap, although its home page observes that its "further aims" include "collecting a computer corpus of statements, confessions, suicide notes, police language, etc., which could be used in comparative analysis of disputed texts".
I'd love to learn that I'm wrong, and that I've managed to fail to notice a history of common-task evaluation in authorship attribution. Or, more probably, that there's a plan for future evaluations in this area that I don't know about. But if this field is as empty as it seems to me, isn't it time for someone to step forward to fill it? A tenth of a percent of the sums at stake in the Facebook case would cover the costs nicely.
Shlomo Argamon said,
July 27, 2011 @ 10:15 am
The lack of common-task evaluations in authorship attribution is indeed a severe problem in the field, especially as it is a highly multi-disciplinary one, with forensic linguists, literary scholars, statisticians, computer scientists, etc. involved. A first step towards this is the evaluation that Patrick Juola and I ran this year as part of the PAN workshop at CLEF (http://pan.webis.de/), using documents from the Enron email corpus. This was a first go at this sort of thing, and we hope to get useful feedback at the workshop that will help in design of future common-task evaluations in the field. Of course, any and all helpful comments will be more than welcome!
[(myl) Thanks! I look forward to seeing the workshop proceedings.
For those interested in the details, insofar as they're available before the 9/11/2011 workshop, I've downloaded and unpacked the materials and placed the README file here. The tests most relevant to the Facebook case are the Verify1, Verify2, and Verify3 test, where multiple documents (42, 55, and 57 emails) from a single author are to be compared to each of a series of documents that may or may not be by the same author. The precision and recall results, available in this spreadsheet from the pan11 website, are encouraging as a representation of the present state of the art, in the sense that they indicate a great deal of room for improvement :-).
As Simon Spero points out in a comment below, the fact that there isn't any withheld data to use for testing, in the case of the ENRON corpus, means that it's hard to get an absolutely clean evaluation. The competing researchers may be entirely honest in not formally involving the test documents in their training process — this is almost certainly true since the scores were so low — but some of them have probably been playing around with the ENRON corpus for years, since it's one of the very few such collections available. So some choices about preprocessing, feature extraction, etc. may very well have been influenced by the test documents.
As far as I can tell, Carole Chaski's ALIAS software did not enter the pan11 evaluation, which strikes me as a shame since ALIAS seems to be the most serious and professional effort in this space.]
Simon Spero said,
July 27, 2011 @ 10:49 am
One starting point might be the Enron email corpus headers and signatures stripped. It's the right genre, it's already labelled, and the usual approaches to evaluating classifiers can be bolted on.
It's game-able (since the whole corpus is known), but it might work for friendly competition, if everyone agreed that a certain subset of messages were out of bounds until the bake-off.
An interesting wrinkle would be to have teams submit attempted false positives (which is a co-problem, but ought to be a key feature of a realistic TREC track, since the task is in part adversarial ).
Simon Spero said,
July 27, 2011 @ 10:55 am
@Shlomo wins :)
Shlomo Argamon said,
July 27, 2011 @ 2:10 pm
Mark, thanks for providing easier access to the PAN workshop materials.
There is no question that the Enron corpus is not ideal for this purpose, for the reasons Mark mentions; we did do a fair bit of anonymization and such to make the task a little more realistic, but there are limits, of course.
One important issue will be the regular need to construct new evaluation corpora, so that research doesn't "learn for the test" – this has certainly been an issue for TREC. This will be particularly tricky for texts in a forensic context, as real (or even realistic) texts are hard to come by, so building large enough corpora for research will be difficult and expensive.
Simon, I like your idea of adversarial submission of false test cases – perhaps next year!
Larry Solan said,
July 28, 2011 @ 9:12 am
Mark's narrative contains some very important lessons. Most significantly, it was the community of phoneticians, mostly university professors, who concerned themselves with overstatements about the prowess of "voice prints" as a reliable forensic tool. As members of a field that exists and holds itself to scientific standards independent of legal applications, the phoneticians protected the integrity of the discipline. Now, three generations later, as Mark points out, enormous progress in speaker identification is taking place. Recently, phoneticians who do not rely on computer algorithms have also been participating in evaluations, putting their ability on the line.
In the field of authorship attribution, the sociology is a bit different now. As forensic linguistics has developed into a field of its own, there is more of a stake from within the community to defend – or at least to accept – current practices rather than to challenge them. This has led to a kind of division between computational linguists on the one hand, and forensic linguists on the other, with a few notable exceptions, including Carole Chaski. By "division" I do not mean personal animus. I simply mean that they seem to be living in different worlds.
My own perspective on this is that universities, perhaps with the help of grant funding, must take the lead, through relevant departments, in improving the integrity of the forensic identification sciences generally, and in forensic linguistics in particular. Research is best conducted by those with a personal stake in being good, but no personal stake in any particular result.
Mark Liberman said,
July 28, 2011 @ 9:26 am
@Larry Solan: "Recently, phoneticians who do not rely on computer algorithms have also been participating in evaluations, putting their ability on the line."
I think that Larry is referring here to the "Human Assisted Speaker Recognition" (HASR) evaluation that formed part of SRE 2010. A summary and discussions of the results is available here. One-sentence version: "Performance of HASR systems did not compare favorably with that of automatic systems on HASR trials".
As for Larry's conclusion:
I agree completely, although I would point out that there are other parties (notably government agencies including NIST) who also have "a … stake in being good, but no … stake in any particular result".
Ray Dillinger said,
July 28, 2011 @ 2:32 pm
This is well outside my field; I deal with extracting meaning from text rather than identifying speakers from audio.
However, from an acoustic standpoint, isn't it possible to make conclusions about the size and shape of an instrument by analyzing the waveforms it produces?
While the application that people obviously want, and the goal of the research, is absolute speaker identification, wouldn't that imply the ability to detect specific physical things about the vocal mechanism of the speaker? Even short of giving absolute identity, knowledge of such specific physical traits would enable narrowing the field of potential speakers in useful ways.
I think a reasonable approach would be to start by setting sights on subproblems like trying to derive specific physical measurements like larynx dimensions from recorded speech. Also, specific physical conditions that have effects on the voice are probably acoustically detectable — scar tissue on the vocal cords, presence or absence of tonsils, and so on.
Is there any phonologist whose work would be useful in identifying, say, speakers suffering from throat nodules? That's fairly audible and should show in a distinctive way on a spectrograph. Even if the evidence does not yet support identification of individual people at large, being able to say, with reasonable scientific certainty, that a recorded voice is or is not that of such a person could be enough to set innocent people free in court.
And more to the point, such information could turn out to be very useful in the diagnosis of medical problems related to the mouth, nose and throat.
Carole Chaski said,
July 29, 2011 @ 4:50 pm
Dear Mark,
Thank you for your post comparing speaker id and author id. Yes, I have been supportive of Shlomo and Patrick's work (including writing a letter of support for their grant as well as mention in publications). Mea culpa — I was not aware of the PAN trials (and, yes, I review for the conference), but I will start running the tests with several ALIAS methods in September 2011, as I too would like to see how this pans out ;))
Meanwhile, I have made my dataset available to researchers for many years (since 1997). The ALIAS dataset (originally described in publications as the Chaski Writing Sample Database) includes ten writing tasks which cover different registers and emotive states. In most actual cases, the register of the questioned document is NOT the same as the register of known comparison documents; e.g. a suicide note is the questioned document, and known comparison documents include love letters, school essays, business letters, e-mails, etc. Thus, when I designed the dataset, I knew I wanted to test authorship id methods on realistic data and cross-register. So far, the ALIAS dataset has been shared with researchers in the United States, France, Switzerland and Canada, and currently is in negotiations with a research collaboration in Israel. Typically, an ILE researcher and I work with each collaborative group to get from the ALIAS dataset the kind of data that fits the collaborator's method and goals, so it takes time and energy to create the data files.
No one identified with forensic stylistics (also called at times, by different practitioners, sociolinguistics (a real misnomer!), text analysis, and behavioral analysis) has ever taken me up on my offer of the data, even data that was published in a 2001 article. One brave soul did tell me that his forensic stylistics analysis of the 2001 article's data was so wrong that he would not publish it. Forensic stylistics practitioners have steadfastly continued to use a method for which they themselves provide no empirical evidence of its reliability and have steadfastly ignored or decried efforts to test the method's reliability. Some quantitative research has been done by people associated with forensic stylistics, but their actual casework relies totally on forensic stylistics, not any quantitative method. So, as you can see, there are very odd disconnects between research and practice in the forensic stylistics community. A Language Log post by Roger Shuy several years ago also discusses research and practice in light of the Daubert criterion of an empirically tested error rate, and highlights what I am talking about.
In the past year I have also been discussing a possible NIST-sponsored test of authorship id methods with some agencies; I can only do what one person can do and appreciate very much the support your post provides.
Best regards,
Carole