Biblical scholarship at the ACL
« previous post | next post »
The 49th Annual Meeting of the Association for Computational Linguistics took place last week in Portland OR, and one of the papers presented there has gotten some (well deserved) press coverage: Moshe Koppel, Navot Akiva, Idan Dershowitz and Nachum Dershowitz, "Unsupervised Decomposition of a Document into Authorial Components", ACL2011.
Well, at least the AP covered it: Matti Friedman, "An Israeli algorithm sheds light on the Bible", AP 6/29/2011 (as usual published under different headlines in various publications, e.g. "Algorithm developed by Israeli scholars sheds light on the Bible’s authorship" (WaPo), "Software deciphers authorship of the Bible" (CathNews), etc.).
Unfortunately, the AP story focuses on an aspect of the work that the authors mention only briefly in one paragraph of the "Conclusions and Future Work" section of their 9-page paper. Here's how the AP describes it:
For millions of Jews and Christians, it's a tenet of their faith that God is the author of the core text of the Hebrew Bible—the Torah, also known as the Pentateuch or the Five Books of Moses. But since the advent of modern biblical scholarship, academic researchers have believed the text was written by a number of different authors whose work could be identified by seemingly different ideological agendas and linguistic styles and the different names they used for God.
Today, scholars generally split the text into two main strands. One is believed to have been written by a figure or group known as the "priestly" author, because of apparent connections to the temple priests in Jerusalem. The rest is "non-priestly." Scholars have meticulously gone over the text to ascertain which parts belong to which strand.
When the new software was run on the Pentateuch, it found the same division, separating the "priestly" and "non-priestly." It matched up with the traditional academic division at a rate of 90 percent—effectively recreating years of work by multiple scholars in minutes, said Moshe Koppel of Bar Ilan University near Tel Aviv, the computer science professor who headed the research team.
"We have thus been able to largely recapitulate several centuries of painstaking manual labor with our automated method," the Israeli team announced in a paper presented last week in Portland, Oregon, at the annual conference of the Association for Computational Linguistics.
Here's how Koppel et al. put it in their "Future Work" section:
Our success on munged biblical books suggests that our method can be fruitfully applied to the Pentateuch, since the broad consensus in the field is that the Pentateuch can be divided into two main threads, known as Priestly (P) and non-Priestly (Driver 1909). (Both categories are often divided further, but these subdivisions are more controversial.) We find that our split corresponds to the expert consensus regarding P and non-P for over 90% of the verses in the Pentateuch for which such consensus exists. We have thus been able to largely recapitulate several centuries of painstaking manual labor with our automated method. We offer those instances in which we disagree with the consensus for the consideration of scholars in the field.
What are those "munged biblical books" that they succeeded on? Well, what the paper in fact documented was a (convincing and appropriate) methodological experiment. First the authors created an artificial problem by randomly mixing fragments of Jeremiah with fragments of Ezekiel (the "munged biblical books"), and then they found a way to successfully de-munge the mixture.
Thus the AP story is accurate, but it leaves out essentially all of the work that Koppel et al. actually reported on at the ACL meeting. Since I think that work was interesting and worthy of note, I'll summarize and explain it here on Language Log. But consider yourself warned: you're going to see why Matti Friedman focused the AP story on that stuff mentioned, in passing, in the next-to-last paragraph of the paper. The body of the work would be a good deal harder to sell to newspaper readers: "Computer program can tell the difference between Ezekiel and Jeremiah"?
And my explanation will be a little longer and more technical than most of our posts. In fact, I'm going to break it up into two or three parts, for my own sake as well as yours; but if your eyes are already glazing over you might want to move along.
Let's start with the standard current approach to statistical authorship analysis, which is basically the same as the standard statistical approach to everything. If we're trying to decide whether document D was written by author X or author Y, we need to start by finding a set of document "features" to use. These should be things which we can measure in an objective or at least reproducible way, and which we think are likely to help us distinguish one author's style from another's. Then we replace the set of documents with a matrix of numbers, where the rows are the documents and the columns are the features, and the number in row i and column j is the value of the jth feature for the ith document.
One easy and obvious feature is plain old word frequency — how often a given word is used in a given document. However, most words are not very good features for authorship classification, for exactly the same reasons that they ARE good features for document retrieval. A random word (like owl or pensions or levitate) doesn't occur in most documents, and whether it occurs or not tells us at least as much about the topic as about the author.
But function words (like to or must or into) are mostly common and mostly not very topic-specific. And such words, though not helpful for finding relevant documents, do sometimes turn out to to be useful features for authorship attribution. Frederick Mosteller and David Wallace were the first to show this, in their seminal 1964 work Inference and Disputed Authorship: The Federalist. (See also Frederick Mosteller and David Wallace, "Inference in an Authorship Problem", Journal of the American Statistical Association 1963.)
The Federalist, as the Wikipedia article explains, is
… a series of 85 articles or essays promoting the ratification of the United States Constitution. Seventy-seven of the essays were published serially in The Independent Journal and The New York Packet between October 1787 and August 1788. A compilation of these and eight others, called The Federalist; or, The New Constitution, was published in two volumes in 1788 by J. and A. McLean.
The scholarly consensus has been that Hamilton wrote 51 of these 85 essays, that Madison wrote 14, that Hamilton and Madison wrote 3 of them together, and that John Jay wrote 5 of them. This leaves 12 essays that are commonly known as the "disputed papers". In order to given themselves a better foundation for inference, Mosteller and Wallace added 36 documents confidently attributed to Madison and 5 known to have been written by Hamilton. This redefined the problem as using 51+5=56 papers by Hamilton and 14+36=50 papers by Madison to decide which of these men wrote the 12 "disputed papers".
As features, Mosteller and Wallace decided to use the frequencies of 70 function words. Here's the table from their 1963 paper:
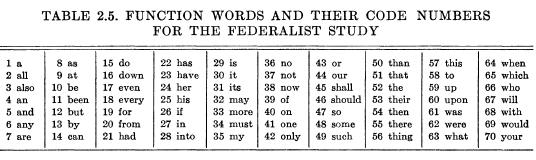
Mosteller and Wallace (and the many researchers who have followed in their footsteps) consider a variety of clever statistical modeling strategies, full of phrases like "a measure of the non-Poissonness of a negative binomial" and "approximate confidence limits for the likelihood ratio". But the reasons that their approach is a sensible one can be seen by plotting the Madisonian, Hamiltonian, and disputed-paper frequencies of a few of their words.
Here are the frequencies per 1,000 words of to, upon, would in the 106 documents whose authorship is undisputed. We can see that Hamilton is much more likely to use upon, and slightly more likely to use would and to:

If we add the twelve disputed points, we see that they seem to fall more in Madison's part of this space than in Hamilton's:

And in fact, if we rotate the coordinates a bit, we could see that there's a plane in this three-dimensional space such all of Hamilton's points fall on one side of it, while all of Madison's points and all of the disputed points fall on the other side of it. Here's a plot of that plane —
to be precise, the plane -0.5368to – 24.6634upon – 2.9532would = -66.6159
— from Glenn Fung, "The Disputed Federalist Papers: SVM Feature Selection via Concave Minimization", Proc. 2003 Conf. on Diversity in Computing:
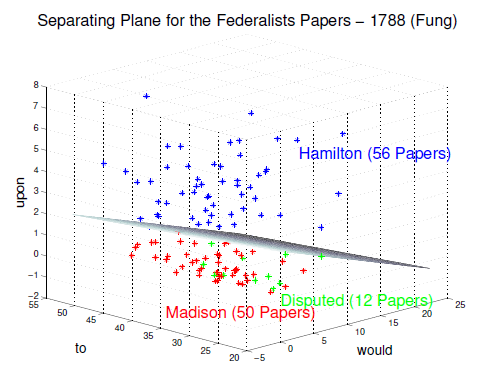
But in fact, nearly all of the work here is being done by Hamilton's inordinate fondness for upon. The function-word-frequency approach doesn't work for every authorship problem — and Koppel et al. found that it didn't work very well for distinguishing among authors in the Hebrew bible.
For the details of how the function-word method failed, and how the King James Version, WordNet and Strong's Numbers succeeded, you're going to have to wait for the next installment. Or you could read their paper.
KeithB said,
July 1, 2011 @ 9:14 am
Wouldn't using the King James Version tell you as much about different *translators" as authors? (Or am I getting ahead?)
[(myl) You're getting ahead. But here's a sneak peak at the connection, from the Koppel et al. paper:
Hope that helps.]
Thor Lawrence said,
July 1, 2011 @ 9:26 am
What does "munge" mean? My dictionary does not list it.
[(myl) From the Jargon File's entry for munge: sense 1: "To imperfectly transform information"; or maybe sense 3: "To modify data in some way the speaker doesn't need to go into right now or cannot describe succinctly".
In this case, I think that the Jargon File's entry is incomplete or perhaps out of date — in context, the use in this paper means roughly "randomly merge". The relevant sense seems to derive from a variant of munch.]
Svafa said,
July 1, 2011 @ 9:35 am
I think that's where Strong's is being brought into the issue. But yeah, I thought the same thing when I saw it. I figure I should wait until the next section or reading their paper before jumping ahead. >.<
Greg Morrow said,
July 1, 2011 @ 9:37 am
Munge means, approximately, "merge in a smooshy rather than systematic fashion'.
KeithB said,
July 1, 2011 @ 9:45 am
In other words, it works because the KJV was a "Search and Replace" type translation. In "Things a Computer Scientist Rarely Talks about", Knuth wonders how Strong did his concordance, it must have been an amazing undertaking without computers.
Svafa said,
July 1, 2011 @ 9:48 am
I was under the impression it was "mung", meaning to "mash until no good". In this case it would mean to mix the two together until they were impossible to separate, and has something of a connotation of mangling.
Jerry Friedman said,
July 1, 2011 @ 9:49 am
@Thor Lawrence: Try this dictionary.
John Cowan said,
July 1, 2011 @ 9:54 am
There is a mixture here of munge, which means to transform in a complex way, and mung, which means to change in a way which is destructive and ultimately irrecoverable. The two terms are somewhat overlapping in any case.
Although mung is one of the standard examples of a recursive acronym, standing for 'Mung Until No Good', this is in fact a backronym, or back-formed acronym. Munge is the older term: it is a dialectal variant of the imitative word munch, probably crossed with dialectal maunge 'eat, devour, munch' < Anglo-Norman maunger 'eat' (cf. Fr. manger) < Latin MANDUCARE.
Eli Morris-Heft said,
July 1, 2011 @ 10:02 am
"Munge" for me means "modified in an unspecified way for use as input into some sort of function". It generally indicates that the outcome of the munging isn't nice but is necessary. The Jargon File seems slightly out of date on this (as it is on many other things).
myl, this was a clear and fascinating explanation. I can't wait for the next part.
mkehrt said,
July 1, 2011 @ 10:27 am
Two commenters have mentioned that the meaning of "munge" specifically involves merging. Is this a usage common to a specific discipline? I (a computer scientist turned software engineer) would definitely use the Jargon File definition over one specifically related to merging.
[(myl) There's certain a "merge"- or "mix"-like usage out there. Some web examples: "We don't just munge together daily update files with the previous flat-file release"; "#drupal menu_local_tasks() is an unusable munge-together of menu data model and theming"; "Munge together the cold mashed potato and the chilli pickle"; "Feed can take multiple rss or atom feeds and munge them up together"; "alternatively you could munge them into a single stream, but this isn't always convenient"; etc.]
John Lawler said,
July 1, 2011 @ 11:32 am
My problem with the words in this instance is that both mung and munge, being regular, spell their past participle forms the same: munged. However, they're pronounced differently: /məŋd/ and /mənʒd/ respectively.
The quotation from the paper uses munged, a word that caught my attention, as was no doubt intended; and in the next para, where Mark explains what mungedmeans in this context, there are three more uses of munged, before a final use of de-munge, which brought me up short because I'd been hearing /məŋd/ all along and now had to retrofit a fricative.
Score one more for regular English spelling, if that phrase isn't too oxymoronic.
J. W. Brewer said,
July 1, 2011 @ 11:32 am
The paper itself is better than the journalistic synopsis in that it correctly notes the traditional ascription of the authorship of the Pentateuch to "Moses" where the AP instead goes straight to "God." Even those believers with a very traditional or "high" understanding of the divine inspiration of Scripture will not have their faith shaken by the software's ability to distinguish Jeremiah from Ezekiel on stylistic grounds. However divine inspiration might be thought to have worked through human authors, no one has ever claimed it resulted in linguistic/stylistic uniformity. There is in principle no reason to think that that divine inspiration could not have been manifested via editors/redactors who assembled pieces of pre-existing texts into a (not entirely seamless upon careful inspection?) whole (and, indeed, the Pentateuch does not assert on its face that it is the work of a single hand, much less that that hand belonged to Moses), although how much tension such a model might create with traditional sorts of faith (and how it would interact with disputes about the historicity/reliability of the "final" version of the text) would depend on various details of the model(s).
Earlier versions of the secular/liberal/academic alternative to the traditional account of the unified authorship of the Pentateuch tended to confidently assert that at least four different authorial hands could be discerned. If the theory of non-unified authorship is now down to P and not-P, the Herr Doktor Professors in the field must have been overtaken by more modesty than was exhibited in earlier decades.
Brett said,
July 1, 2011 @ 1:43 pm
@J. W. Brewer: I was surprised that they only broke the data down into P versus not-P. This may just be a matter of the program not being sufficiently developed to distinguish between multiple options. In this case, P versus not-P would probably be the natural choice, since the Priestly Source is usually considered to be the most different from the other authors.
I don't think there's any doubt that there were a profusion of earlier written sources combined to make the Torah. The existence of so many parallel law codes is the strongest piece of evidence, but there are plenty of other places in the not-P text where two separate narratives certainly seem to have been grafted together. Whether the breakdown into J, E, D, and P (plus a little bit of other stuff) is really accurate is another question.
Jerry Friedman said,
July 1, 2011 @ 1:49 pm
@J. W. Brewer: This article from Chabad.org says
J. W. Brewer said,
July 1, 2011 @ 2:38 pm
Jerry F.: Perhaps I should qualify my earlier statement somewhat to account for that sort of claim, which I understand to be not-uncommon (although I don't know how universal) among certain subsets of present-day Jews. It is, I believe, quite uncommon (I won't say completely unattested) among Christians, so I doubt the current number of believers in it is very far into the "millions." Does Chabad think any of the other parts of the Tanakh existed before creation?
In any event, Koppel et al. say Moses when describing the traditional understanding, and I suppose that leaves plenty of room for differing views as to the nature of "authorship" or the transparency of the channel. One can coherently, for example, believe that God directly controlled each incremental word choice in the prophetic utterances of Ezekiel and Jeremiah while still (for reasons of his mysterious providence) allowing each prophet to utter in a characteristic personal style. One helpful (IMHO) feature of the New Testament is that (pace a few marginal dissenters) we strongly suspect that most of the stuff Jesus said was not actually said in Greek, but we do not have access to an "original" text behind the Greek text. Even on a very strong view of the reliability of the Gospels, this quirk (um, at least when thoughtfully considered, which cannot be presumed) may tend to discourage certain sorts of Kabbalistic-style speculation.
Rubrick said,
July 1, 2011 @ 9:47 pm
I like that on Language Log a discussion about the authorship of the Bible devolves into a discussion of the word "munge" rather than the other way around.
Ken Brown said,
July 2, 2011 @ 2:16 pm
Great paper. I'm looking forward to someone trying similar methods to propose reconstructed sources for Samuel/Kings and also on Luke/Acts in the New Testament – books that no-one disputes were compiled from previous sources (Luke claims to have used written documents)
One potential difficulty is that books like that were not "munged" together more or less randomly, they were redacted by editors who had a purpose in mind. That might tend to obscure the signal from separate sources.
Possibly more than once – it is at least plausible that Samuel/Kings as we have it is a quite late redaction of a book that had been compiled from previous sources in the early post-exilic period – a chronicle of the Kings of Israel, bits of Jeremiah, some stories about Elijah and Elisha, an account of the kivs of Samuel and David & so on – and that some or all of *those* sources had themselves been compiled from other written sources before the exile – so some passages may have been through a redaction process two or three or possibly even more times.
And of course its well-known that manuscript copyists have a tendency to make the language of a less-well-known text conform to that of a better-known one – its widely thought that the language of Mark's Gospel has drifted towards that of Matthew (and maybe Luke) in places. Although Mark is usually considered to be the original version, and much of Matthew and Luke are likely derived from it, Matthew was in more widespread liturgical use in the early church, and Luke is written in better Greek and they both include material "missing" from Mark, so early copyists, maybe quite unconsciously, seem to have "corrected" Mark in the direction of Matthew.
All that will blur the signal. Which is one reason this topic is so fascinating.
FWIW to me to "munge" text is to deliberately reorder it in some consistent and perhaps automated way. The canonical usage seems to me to be email address and header munging. Once upon a time, back before the complete triumph of SMTP there were different email formats used in different applications and people like me had to write code to translate one to another.
My first introduction to the word was almost certainly RFC 886 "Proposed standard for message header munging", written in 1983, though I probably didn't come across it till 86 or 87 when I was administering a Profs email system that had to be connected to someone else's. It starts "This memo describes the rules that are to be used when mail is transformed from one standard format to another. " We used to have to know that stuff. Things are much simpler now.
Monado said,
July 3, 2011 @ 3:16 am
Munge implies to mix roughly, physically or by computer. I think "mashup" is doing some of the same work now.
Hermann Burchard said,
July 3, 2011 @ 8:00 pm
@J. W. Brewer: . . no reason to think that that divine inspiration could not have been manifested via editors . .
In support, a quote from Hilaire Belloc (translated from his French Wikipedia page):
When a work is successful, the fact is that this is not simply a man who is the author, but a man inspired.
Ken Bloom said,
July 4, 2011 @ 1:07 pm
One possible problem with applying the function word technique to Hebrew is the fact that many important function words in Hebrew aren't words, but affixes. (This is true in Modern Hebrew, but even more true in Biblical Hebrew). Without some kind of accurate morphological analyzer to split the affixes, identifying common words probably isn't enough to create a feature set of actual function words.
Harry Erwin said,
August 6, 2011 @ 12:47 pm
Michael Oakes and I have been working with the Johannine corpus in the New Testament, making use of the Nestle-Aland version of the Greek New Testament. Separating the roles of genre and authorship turns out to be difficult, especially as Christian discourse or dialog sources in Greek from the first and second century are uncommon, being limited to Q, a few sayings from the Gospel of Thomas, and fragments of the Gospel of Mary, and documents from different genres with a common known author are rare.