Polysyllabic characters in Chinese writing
« previous post | next post »
There is a widespread misconception that Chinese languages are monosyllabic. That is purely an artifact of the writing system, since most Chinese words average out at about two syllables in length. Typical examples: zhuōzi 桌子 ("table"), fēijī 飛機 ("airplane"), péngyǒu 朋友 ("friend"), qìchē ("car"), huǒchē 火車 ("train"), fángzi 房子 ("house"), and so on. Even in Classical Chinese (or Literary Sinitic), there were many words that were greater than one syllable in length, e.g., húdié 蝴蝶 ("butterfly"), fènghuáng 鳳凰 ("phoenix"), shānhú 珊瑚 ("coral"), wēiyí 委蛇 / 逶迤 ("sinuous; winding; meandering"), jūnzǐ 君子 ("gentleman; superior man; person of noble character; sovereign; ruler; lord; m'lord"), and so on.
It will probably come as a shock to most readers of Language Log that not even all Chinese characters are monosyllabic.
When I first went to Beijing in 1981 to read Dunhuang manuscripts in the National Library, I saw the following words engraved on a horizontal wooden plaque hanging over the entrance to the rare book room where I sat every day to read scrolls and booklets:
Běijīng túshūguǎn shànběn shūshì
北京圕善本書室
"Rare Book Room of the Beijing [National] Library".
I'm not absolutely certain of the last two characters, and the first two characters may have been preceded by something like guólì 國立 or guójiā 國家 (both would mean "national" in this context). But I remember very clearly these characters: Běijīng ?? = 北京圕.
Even though I had never seen the third character, 圕, I knew from the context that it must be equal to túshūguǎn 圖書館 ("library"). When I asked the librarians on duty how to pronounce the mystery character, they said matter-of-factly, "túshūguǎn".
Thus was the myth of innate monosyllabism of Chinese language, and even of Chinese writing, a myth with which students are indoctrinated worldwide, forever happily shattered for me.
The Unihan data page for this trisyllabic character is here, and 圕 has also made it into Wiktionary.
圕 comes up in pinyin input if you type "tuan", at least on my computer. That reading seems to be some sort of abbreviation (beginning and ending) of "tushuguan".
圕 was a real character widely used among the Communists at Yan'an during the 30s and 40s, and also after the founding of the People's Republic of China in the 50s. It obviously continued into use even up to the 80s when I saw it in Beijing. This character is said to have been invented by a library sciences expert named Du Dingyou (杜定友) in 1914.
Once exposed to túshūguǎn 圕 ("library"), I kept my eyes open for other polysyllabic characters. They weren't hard to find. In fact, there were hundreds of such polysyllabic characters, and they still pop up from time to time simply because they are easier and faster to write than the groups of characters that they are intended to supplant. The authorities, however, in their ongoing quest to "standardize" Chinese language and writing, have attempted to outlaw such polysyllabic characters (with a few exceptions, one of which I shall mention below).
Whereas 圕 is trisyllabic, one character that was very popular among Communist writers is quadrisyllabic, namely the graph that stands for
shèhuì zhǔyì
社會主義 (simplified form: 社会主义)
"socialism"

As I noted above, although the government tries to stamp out such handy polysyllabic characters in the name of standardization, several of them continue in use, even by state corporations, and may be found in official dictionaries. One example of such a character that is still in wide circulation is the bisyllabic graph 瓩 (U+74e9) . It is pronounced qiānwǎ and is equivalent to 千瓦 ("kilowatt")
Polysyllabic characters are by no means a phenomenon of the 20th century. Indeed, I found a number of them in Dunhuang manuscripts dating back well over a thousand years, including this one:
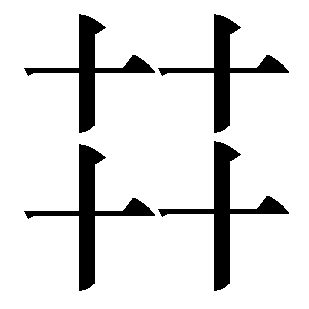
In Modern Standard Mandarin, this graph is pronounced púsà and is the equivalent of the two characters 菩薩 (simplified form: 菩萨) (an abbreviated transcription of the Sanskrit word "bodhisattva" or Pali "bodhisatta" — "enlightened being").
In fact, we can trace the existence of polysyllabic graphs back to the earliest stage of the Chinese script, namely, that of Shang oracle bone inscriptions (OBI) about 1,200 BC.
Polysyllabic characters are very common in OBI, but they mostly occur in certain limited situations. Two-syllable names of ancestors are perhaps most often written with single (or combined) graphs, though they are also commonly written with 2 separate graphs. These include names like Shàng Jiǎ 上甲, Shì Guǐ 示癸, Mǔ Yǐ 母乙, etc. Trisyllabic names like Kāng Zǔ Dīng 康且(祖)丁 can also be written in the space of a single graph. Similarly, certain sacrificial terms, like xiǎo láo 小牢 ("lesser lao sacrifice [consisting of an ovicaprid and a pig]"), can be written with combined characters. Set phrases are also not infrequently written with polysyllabic characters, like shàngxià 上下 ("above and below"), xiàshàng 下上 ("below and above"), dàjí 大吉 ("greatly auspicious"), shòu yòu 受又(祐) ("receive blessings"), etc. The last of these (at least) pretty clearly isn't a single word, but it can still be written with a combined graph.
Numbers are also very commonly written in combined forms, whether just multisyllabic numerals written together, like liù bǎi 六百 ("six hundred") or shísān 十三 ("thirteen"), or numbers written together with the objects they quantify, like qīshí rén 七十人 ("seventy people").
In modern varieties of Chinese, there is considerable phonological as well as distributional and semantic evidence for polysyllabic words and fixed phrases. Judging from the above evidence, it would seem that the concept of polysyllabic words and phrases is also firmly embedded in the history of Sinitic writing systems, almost as deeply as the partly-contrary notion that morpheme = syllable = character.
[Thanks are due to Maddie Wilcox for asking me about the phenomenon of polysyllabic graphs and to Matt Anderson for the Shang data; Tom Bishop created the special characters with the Wenlin CDL system and Richard Cook checked Unicode numbers for obscure characters.]
Rémi Camus said,
August 2, 2011 @ 6:25 am
Thank you very much, it's the first time I hear about these characters. But your conclusion seems either too far-reaching or inadequate :
++it would seem that the concept of polysyllabic words and phrases is also firmly embedded in the history of Sinitic writing systems, almost as deeply as the partly-contrary notion that morpheme = syllable = character.++
Every single detail here confirms what you first write : these characters are but abbreviations. Cf. Engl. "etc." or "IMHO" ("vs" for "versus" would be something else, some kind of a simplified form…)
These abbreviations are still awaiting a typology:
1) TUAN (圕 – tone?) works on phonetics ;
2) 瓩 [qiānwǎ in case if the character is lost in the commentaries area] is a combined graph ;
BTW, I'm not sure I got you right. You write : "shòu yòu 受又(祐) ("receive blessings") […] isn't a single word, but it can still be written with a combined graph." Does it mean you can have ONE character combining SHOU and YOU? (and you don't show it, because the font doesn't exist?)
3) … Do you know about any Chineese ἰχθύς (not the transliterated "Ichthys" which doesn't mean "fish" for English readers) ?
4) other cases ?
Anyway, yes, for the non-specialist, it's awesome :)
Outis said,
August 2, 2011 @ 7:02 am
An interesting topic. Still, I think it may be going too far to say that there are actual polysyllabic characters in modern Chinese. The fact is that all these "polysyllabic" characters are contractions of multiple monosyllabic characters. They _always_ have multi-character equivalents, and are probably better understood as typographical ligatures rather than unique characters.
The only exception you've shown is the 十十十十 (=菩薩?), which is arguably a religious symbol more than a character, and possibly intentionally esoteric.
Yu Li 虞莉 said,
August 2, 2011 @ 7:49 am
A very interesting piece! From my own experience, some college students in the 1990s, when taking lecture notes, tended to write the word "wenti" (question, problem) with a single graph that is made of the radical "men" with a letter "T" inside it. I do not know how common or how widely spread this practice was. But it seems to be formed with the same principle as described above.
Dan Lufkin said,
August 2, 2011 @ 8:04 am
Does there exist a Chinese shorthand like Gregg or Pittman?
Randy said,
August 2, 2011 @ 9:40 am
The tradition, of course, continues with new offerings, such as the one on the left side of this page:
http://chinadigitaltimes.net/
Frances Fu said,
August 2, 2011 @ 11:36 am
Very interesting topic, I remembered when I was in college (Taiwan), professor do teach us about certain specific characters like 圕, 說那是一種省略而且方便的用法。Thanks for sharing!
Victor Mair said,
August 2, 2011 @ 12:50 pm
@outis
"The only exception you've shown is the 十十十十 (=菩薩?), which is arguably a religious symbol more than a character, and possibly intentionally esoteric."
It is actually based on the grass radicals at the top of each of the two characters.
One of the most popular of these polysyllabic characters, one which I still often see in people's handwriting and one which I myself frequently use, is that mentioned by Yu Li below, namely, wèntí 门 with a "T" written inside it. This means the same as wèntí 问题 ("question; problem"), but cannot possibly be considered as a "ligature" (your word) of 问题, since the "T" part is not a part of the second character of 问题, i.e., 题. Rather it is the English letter "T", which makes this wèntí [ 门 with a "T" inside] particularly interesting and revealing. It shows yet once again that the sounds of Sinitic languages are more important / fundamental / basic than Chinese characters and that the Chinese people do possess a notion of word apart from the characters.
@Randy
You bet!! That is a great example. It is pronounced cǎo ní mǎ 草泥马 ("grass mud horse") and stands for cāo nǐ mā 操你妈 ("fuck your mother") — to escape the internet censors. http://languagelog.ldc.upenn.edu/nll/?p=1225
Joseph said,
August 2, 2011 @ 3:41 pm
@D Lufkin
Apparently, yes! And directly inspired by Gregg shorthand:
http://www2.chinadaily.com.cn/china/2010-11/11/content_11531303.htm
@Dr Mair
In a slightly related topic, I've also seen a similar non-standard "abbreviation" effort in Japanese, whereby the character 魔 becomes 广 with a マ inside.
Neil Kubler said,
August 2, 2011 @ 4:19 pm
Yes, interesting stuff! The 問 with the English "T" in it in place of 口, for 問題, was also in use by university students in Taiwan when I was a student there in the 1970s. To add to the collection, I offer these three, all with the option of one or two characters (if one character, it's pronounced as if it were the two characters):
糎=米厘 "millimeter"
哩=英里="mile"
浬=海里"nautical mile"
siweiluozi said,
August 2, 2011 @ 4:57 pm
@Yu Li:
I frequently saw the contraction you describe for wenti in archival sources in Shanghai from the 1940s and early 1950s, so that form goes back at least to that time.
tiffert said,
August 2, 2011 @ 5:15 pm
In 1921, the 司法讲习所, which was the central school for judicial training in the early Beiyang period, planned to introduce a training course for judicial stenographers, but the school was abruptly closed before the course started. I have no idea what form of stenography they intended to use, but presumably something pre-dated Tang Yawei's efforts.
Manlajo Abra said,
August 2, 2011 @ 7:50 pm
Two more examples:
兛 = 千克 = 'kilogram'
瓩 = 千瓦 = 'kilowatt'
Matt said,
August 2, 2011 @ 9:28 pm
That's fantastic. I'm never writing 図書館 again.
Are there any examples of the opposite phenomenon, where a word or phrase that is X characters long is pronounced with fewer than X syllables?
tiffert said,
August 2, 2011 @ 9:32 pm
@Matt
Yeah, just about anything in 北京话. ;-)
Petrus said,
August 2, 2011 @ 10:58 pm
@Matt: In Japanese too. There are some place names in Okinawa that have so-called silent characters. 金武 being pronounced 'kin' is one that comes to mind.
Multisyllabic Hanzi? | Sinosplice said,
August 3, 2011 @ 12:07 am
[…] Update: The venerable scholar Victor Mair writes about this subject on Language Log: Polysyllabic characters in Chinese writing. Posted at 11:19am. Posted in language Tags: Chinese characters, Chinese study, Japanese, […]
Matt said,
August 3, 2011 @ 12:13 am
Yes, excellent point — there are all kinds of examples like this in Japanese, arising through various processes. That's what made me wonder if there's anything similar in Chinese… I mean, I thought there was more of a 1:1 correspondence there, but Victor has already shown that at least one side of that ratio can be stretched.
(Off-topic: I wonder if the /n/ at the end of 金武 /kin/ was originally the /mu/ of 武, like 喜屋武 /kyan/, etc.)
joe said,
August 3, 2011 @ 12:56 am
a very interesting piece. the observation that "That is purely an artifact of the writing system, since most Chinese words average out at about two syllables in length." is a little bit confusing if not misleading. with a few exception, most chinese characters are monosyllables. thought 飞机 (plane) means what one single word means in english, they are two characters. 飞 itself is a character. it can easily combine with other characters to form a two-character or even three-character words (can they be called phrasal words or combination words?) such as 飞人,飞翔,飞车,飞车党. these characters act as single characters when they are not paired with other single characters. for example, 飞,人,翔, 车,党. they are single characters and they are monosyllables. when they are paired with other single characters, each single character loses independence somewhat yet contributes its original meaning to the combined meaning of the result words. nowadays, unexpected and seemingly impossible combinations of such single characters mushroom at an amazingly fast rate on internet. 范跑跑,楼脆脆, 打酱油,你懂的,倒地死, 福二代 are just a few examples (i can be wrong and these may not be good examples). they are like new words that appear in english.
Outis said,
August 3, 2011 @ 2:17 am
Chinese people certainly possess a notion of word apart from the characters. So much so that I don't see why this point needs to be made at all. On the other hand, there's no point in comparing the importance of sound vs. writing in Chinese, clearly they are both very important.
Still, 火星文 is full of multisyllabic contractions, or multi-character monosyllabic words, or characters written with non-standard graphemes. Sure, it can be done, and it is being done, but does that mean we should reconsider the nature of Chinese characters? I'm still not convinced that these "multisyllabic characters" should be considered the same creature as standard monosyllabic characters.
JQ said,
August 3, 2011 @ 3:11 am
I agree with the previous two comments. I am sure Victor knows the difference between 字 and 詞, and that these don't have a direct equivalent in English.
Things like 蝴蝶 could certainly be considered polysyllabic words, even though the characters on their own also have the same meaning. Things like 桌子 are different, where 桌 is the actual word and 子 just is some sort of nuanced suffix. On the other hand, 飛機 clearly can be divided into two components, like Flugzeug in German, though not like aeroplane where the essence of the word is captured by "plane". Then of course you have everyone's favourite word, 危機, which to me is a bit like "butterfly". It can be divided into two as well, and certainly flies but has nothing to do with butter, and no English speaker would think too much about it.
Anything in Chinese can be written in a block shape, for example name seals, the business / new year greeting 招财进宝 (not the best example), and seeing as that image came from a Korean site, Hangul itself.
In response to Matt, you have to remember that the Japanese just borrowed Chinese characters (not necessarily words) to fit their existing language, of course with some of the Chinese language being transferred as well. There are words where each of the characters clearly combine to make the word's meaning, but the pronunciation cannot be assigned to any character in particular. Victor has given a good example above with the numbers. 二人 (futari) would rarely be said ninin. General Yamamoto's given name, Isoroku, means 56, where "iso" represents 五十 but "i" does not represent 五. Also, you have 大人 which can be pronounced in 4 different ways, according to Wiktionary, where some can be broken into individual character sounds and some can't! And Japanese place names are just odd and make no sense at all to a non-native Japanese, especially in Okinawa, which practically has its own language.
Josh said,
August 3, 2011 @ 4:09 am
I'm not quite convinced that the 'invention' of new characters to represent a modern word means that characters inherently or Chinese in general can be considered as being 'polysyllabic'.
The fact is that, with a few exceptions, which are the result of the passage of time and the loss of meaning of one or both of the characters (as in 蝴蝶), words like 火車 and 飛機 can still be broken down into their composite parts, each of which have a distinctive and recognized meaning.
As for characters like 圕…this is somebody just having a bit of fun….from the Wiktionary article, it seems that Mr. Du was just a little on the lazy side and thought it would be nice to not have to write three characters. That said, he was clever to create a place 口 where books 書 could be put.
The argument is old, but I'm still not convinced that the basic unit of Chinese is the 詞 and not the 字. The fact that it is the latter, as the basis for modern Chinese, make the language essentially monosyllabic with the ability to create character compounds 字組 that form words like 國家 or 經濟 or 圖書 that add more detail to or clarify the meaning. This is similar to 'comic book' or 'alan wrench' – 圕 would be like writing 'comicbookcollector' as a single word, which may work in German (not sure what it would be), but not English or Chinese.
Victor Mair said,
August 3, 2011 @ 5:12 am
@outis: "I'm still not convinced that these "multisyllabic characters" should be considered the same creature as standard monosyllabic characters."
Of course, they're NOT. That's the whole point.
Victor Mair said,
August 3, 2011 @ 5:19 am
@joe
"the observation that "That is purely an artifact of the writing system, since most Chinese words average out at about two syllables in length." is a little bit confusing if not misleading. with a few exception, most chinese characters are monosyllables."
If you will reread what you just wrote, including your quotation of what I wrote, you will see that I was talking about WORDS and you are talking about CHARACTERS.
BTW, the trisyllabic expressions you cite near the end of your comment are phrases, not words.
W.Su said,
August 3, 2011 @ 6:50 am
There are more frequently used characters of this type: 囍,xi3, double joy, normally read as 双喜shuang1xi3, 廿,nian4, twenty, normally ready as 二十er4shi2, 卅,sa4, 三十 thirty, normally read as san1shi2. You may argue that the dictionary pronunciation is not polysyllabic, but what's the difference if people normally read these characters as polysyllabic?
Outis said,
August 3, 2011 @ 8:50 am
@VM:
Well then, I might have misunderstood your position. I thought you were suggesting that the common understanding of Chinese characters as monosyllabic graphs should be revised, because of the existence of these "multisyllabic characters". Was this not the point that you were making?
And to clarify, I don't think the "multisyllabic characters" should be considered "characters" in the same sense. All of the multisyllabic characters are simply graphical alternatives to multi-character words. And except for the most modern examples (圕, 礻义, 门T), these characters also have monosyllabic readings.
As for 门T: many students in France write the -ion ending as -°. But no one would consider "constitut°" as a distinct word from "constitution". I'm sure everyone who writes 门T is also well-aware that this is not a "real character". You may argue that they were just indoctrinated by prescriptivist thinking to realize that 门T is indeed a real character. But if so, you'll have to consider all of the 火星文 in the same light.
Katherine said,
August 3, 2011 @ 10:01 am
I agree with Outis in that at least some of the polysyllabic characters are shorthand–almost like the texting/IM language used today (WenT especially)–and that very few are considered as truly 'official' and part of the language (you probably wouldn't find it in a book). But this is very interesting though!
Victor Mair said,
August 3, 2011 @ 11:08 am
@Outis
"I'm sure everyone who writes 门T is also well-aware that this is not a "real character". You may argue that they were just indoctrinated by prescriptivist thinking to realize that 门T is indeed a real character."
In your second sentence, did you mean to say "not to realize"?
Bob Violence said,
August 3, 2011 @ 11:25 am
I believe 圕 appeared in an early Xinhua dictionary, where the "official" pronunciation was given as tuān — combining the initial from 圖, the final from 館, and the tone from 書. It was removed in later editions.
Expanding on the section about oracle bone characters, there's a hypothesis that Old Chinese affixes often resulted in a single character getting a di- (perhaps even tri-)syllabic pronunciation, and that this was sometimes indicated by adding an extra stroke to the character as a kind of diacritic.
Outis said,
August 3, 2011 @ 1:50 pm
@VM:
Oops. I meant to say: "they were just *too* indoctrinated by prescriptivist thinking to realize that 门T is indeed a real character."
@Katherine:
Yes, IM/SMS shorthands like the "Martian language". Of course they aren't always actually shorter than what they're meant to replace. But I'm not suggesting that anyone should have the authority to determine whether something is an "official" character. I just think that the intention of the writer should be taken into account. If I write something that looks like a character and works like a character, yet I do not consider it a character when I write it, then maybe it really isn't a character. If anything, I would tend to think that the Martian writers would be more invested in their inventions than students who write 门T.
@Bob Violence, re: "tuan" pronounciation:
It was already mentioned, but somehow I didn't quite realize its implication. Clearly somebody must have thought that for 圕 to be a proper character, it must have a monosyllabic pronounciation. I wonder if it was someone at Xinhua or Du Dingyou himself.
Matt said,
August 3, 2011 @ 3:45 pm
JQ, with all due respect, I know why Japanese is the way it is. I'm tryin' to learn about Chinese here. (For example, I even know that the /i/ in /iso/ *does* mean 5. It's the same /i/ as in modern /itstsu/, "5". /so/ means "10" but only appears combined with other words as a multiplier, e.g. /misoji/ = 三十日, "3-×10-day, 30th day"… thus /isoroku/ = "5-×10-6, 56".)
As I said, I had assumed that Chinese was different because their language had a different relationship to Chinese characters — but here I am discovering for the first time that sometimes new characters have created with multiple syllables (although I tend to agree with Remi and Outis that all of these examples are clearly consciously-created abbreviations, most not in regular use, and not really a good counterexample to the "one character, one syllable" rule). So now I'm wondering if by a similar process people have created words that are 4 characters long but only the 1st and 3rd are actually pronounced, or words where there is one character in the middle which is not pronounced at all, or anything like that. (But since Victor isn't replying, I begin to suspect that there are none, alas.)
Matt said,
August 3, 2011 @ 3:47 pm
(Er, for /misoji/ 三十路 read /misoka/ 三十日. I changed my example because I didn't want to get bogged down in an explanation of what a 路 was in that context.)
Victor Mair said,
August 3, 2011 @ 4:52 pm
@Matt:
"…So now I'm wondering if by a similar process people have created words that are 4 characters long but only the 1st and 3rd are actually pronounced."
If I understand you correctly, sure, there are countless such abbreviations, e.g., Běidà 北大 for Běijīng dàxué 北京大學 ("Peking University").
Matt said,
August 3, 2011 @ 6:57 pm
Hmm, well, if "běidà" is considered an acceptable pronunciation for the full four characters 北京大學, that's what I'm talking about. But if it's considered the pronunciation of the two-character 北大, which is itself an abbreviation for 北京大學, that's not what I'm talking about.
(Like "NY" vs "New York": we don't consider "En Why" an acceptable pronunciation the written string "New York". I assume that the analogy holds for 北大 and 北京大學, but am I wrong? Is the analogy a bad one for some reason?)
I realize that what I'm asking may sound ridiculous to a scholar of Chinese — of course words with "silent characters" don't exist! how on earth could they? etc. — but I had never heard of polysyllabic characters in Chinese, either, until I read this post…
(Also, I'd like to apologize to JQ; "with all due respect" should really have been "with all due respect and with gratitude for taking the time to address my point". I feel bad about being curt in my response; I should probably have been more clear about setting aside Japanese usage [where literally anything goes] in my original question.)
Outis said,
August 3, 2011 @ 8:11 pm
@Matt:
This is going way OT but I just want to add that, even though kanji pronounciation can sometime seem arbitrary, there's almost always some kind of logic to it, however twisted it may be. One of my favourite examples is the family name 小鳥遊, which reads Takanashi. It's a brilliant way to subvert an ill-fitting writing system.
Outis said,
August 3, 2011 @ 8:54 pm
@Matt:
Forgot to say: in some areas, the 2nd character in 为什么 (wèishénme, "why") can be skipped. But people only talk like that when they're being deliberately lazy for whatever reason, and only in very informal context. Of course, it can then be written as 为么, in which case there'd be no silent character.
Anyway this is the closest thing to what you're looking for that I can think of. Perhaps there are better examples in non-mandarin dialects.
A. said,
August 4, 2011 @ 10:44 am
How do you count words in languages whose orthography doesn't use spaces, anyway? Saying that seagull is one word and sea urchin is two doesn't tell much about spoken English AFAICT, only about its spelling. So, how do you tell whether a two-syllable, two-character lexical item in Chinese is one word or two?
Frances Fu said,
August 4, 2011 @ 4:37 pm
I found the Chinese character for Biang Biang Noodle http://en.wikipedia.org/wiki/Biang_biang_noodles is another interesting case; "Made up of 57 strokes, the Chinese character for "biáng" is one of the most complex Chinese characters in contemporary usage…" quoted by wikipedia; No matter how complex it is, I still feel glad to introduce it to students since the character itself demonstrate plentiful meanings but in an unique way.
joe said,
August 5, 2011 @ 4:14 am
two-character or three-character words in chinese are just like two-word or three-word english words such as computer experts, discount rate, group life policy, foreign policy, economic crisis, debt ceiling.
in china, at least in the part where i live, we have a phrase 白字先生. the phrase describes a person who tends to write a lot of wrong characters (misspelled or other same-sound words in place of right ones) though he uses right phrases or compound words in meaning. we also say 用词不当. this phrase generally refers to inaccurate or inappropriate phrases though each character in a phrase can be written correctly. the idea here is single characters are still the basic building blocks of chinese language.
in most english text books we use in china, each text is often followed by a list of new words. that list is often called in chinese 生字表. a word is one single english word. if there are a few words together, we call the unit 词组. we in china usually understand the word word that way. that is why i find the observation a little bit confusing if not misleading.
anon. said,
August 18, 2011 @ 10:27 pm
@ Matt:
Yes, 花儿 huār.
The suffocated said,
February 6, 2012 @ 12:23 pm
Well … both 鳳 and 凰 are birds in Chinese legend, but 鳳 is male and 凰 is female. So, 鳳凰 definitely comprises two words but not one, unless you want to assign a new meaning to the phrase — such as an intersex bird ;-D
Whether 朋友 shall be called a word is also questionable, since both 朋 and 友 can be used alone to mean "company" or "friend(s)", as in 有朋自遠方來 (due to Confucius) or 歲寒三友. I would say it is a pair of words with very similar meanings rather than a single word.
Victor Mair said,
August 19, 2013 @ 12:15 pm
From Nils von Barth:
To give a Japanese perspective: such multi-character abbreviations are extremely rare to non-existent in Japanese (AFAIK), and characters like 瓩 are of Japanese coinage (Meiji era), used to represent (multi-syllable) foreign borrowings.
This last is interesting but requires a bit of background (for those unfamiliar with Japanese); details follow.
I have never seen a Japanese character that is an abbreviation for multiple characters, and pronounced with multiple Sino-Japanese readings (on'yomi). (Well, prior to 圕.) Others may exist, but I would imagine they are extremely rare in Japanese, as I’ve seen many rare characters, but never anything like this.
Instead, in Japanese one has the following phenomena:
Ryakuji 略字 “abbreviated characters”
There are various abbreviations of a single character, like 第 → 㐧 or 点 → 奌. These are not extremely common, but do show up on signs.
Contraction: omitting characters (and the sound)
This is pervasive in Japanese (as it seems in Chinese). For example, 国際連合 kokusai rengō “United Nations” → 国連 kokuren “U.N.”. Note that the sound is also dropped – it’s a linguistic phenomenon, not an artifact of writing. This isn’t limited to kanji vocabulary – it’s also used in katakana words for other borrowings スマートフォン sumāto fon → スマフォ、スマホ sumafo/sumaho.
Japanese readings
Multisyllable native Japanese readings kun'yomi (not borrowed Chinese readings, on'yomi) of kanji are basic in Japanese writing, with some quite long ones, like 承る uketamawa-ru or 志 kokorozashi. This is because many Japanese words and morphemes are polysyllabic, so when represented by a single Chinese character, you get a polysyllabic reading. However, borrowed Chinese readings are always a single syllable (AFAIK).
There are cases where a single native word is represented by multiple Chinese characters, like 可愛い for kawai-i “cute”, but this is the exception, and the characters don’t correspond to sounds (it’s just using the Chinese word 可愛 to write the native word かわいい).
Foreign reading + Japanese-coined characters
In addition to native words (often polysyllabic) being represented by a single kanji, there are rare cases when a foreign borrowing is represented by a single kanji. The only everyday examples are 頁 pēji, “page”, 零 zero “zero”, and 打 dāsu “dozen”. Surprisingly, these are classed as kun'yomi, just like native Japanese readings. That is because these readings correspond to the meaning of the character, not the borrowed Chinese sound. You can read more about these at single-character loan words and get a full list at Appendix:Single character gairaigo.
This brings us to the punchline: 瓩 is a Meiji-era Japanese-coined character (国字 kokuji), from 千瓦, but in Japanese is read kiroguramu and the compound 千瓦 does not exist in Japanese (AFAIK). In modern Japanese one instead writes “kg” or in katakana as キログラム and 瓩 is unrecognizable except to specialists. However, it looks like it was borrowed into Chinese, but without the pronunciation, with “kilogram” instead being calqued as qiānwǎ (…and also, or instead, getting the meaning “kilowatt”; the meaning doesn’t change in other characters, such as 粁 for “kilometer”).
Thanks again for the fascinating post, and hope this adds something of interest!
Victor Mair said,
August 20, 2013 @ 12:45 pm
From Matt Anderson:
Nils von Barth’s examples are very interesting, but, coming from the perspective of Chinese, I find it bizarre that 瓩 writes kilogram, not kilowatt, in Japanese. Reading this comment, I assumed that 瓩 was just a typo, and that the graph either should have had the reading キロワット kirowatto or that the character in question should have been 兛, since that graph can write the Mandarin word qiānkè ‘kilogram’.
But no, it turns out that the Japanese kanji for gram is 瓦 (グラム guramu), which is read かわら kawara when it has the meaning ‘roof tile’, but, in Mandarin, wǎ 瓦 means watt, not gram, in addition to roof tile. So, 千瓦/瓩 writes kilowatt in Chinese but kilogram in Japanese. How could this have come about? Could this (currently) seldom-used character have been created independently in Japan & China, or was there a misunderstanding along the way?
Googling “瓩” mostly just brings up pages about the character, not real uses of it, but the graph does seem to have some currency in Taiwan in its ‘kilowatt’ sense (there is, for example, an article titled “今年太陽光電競標容量目標9萬瓩達成” on the website http://www.beyondtech.com.tw, and other websites have some Taiwan-centric headlines like “兩核電廠停機 北台灣缺電百萬瓩". I’m not sure what this apparent connection with Taiwan means, but it seems perhaps significant.
Victor Mair said,
August 21, 2013 @ 7:20 am
From Nathan Hopson:
I've been unable to comment, so here's my two cents:
—–
Western measurement units seem to have inspired particular 国字 creativity:
British/US system
呎 フィート
噸 トン
grams
瓧 デカグラム
瓩 キログラム
瓲 トン
瓰 デシグラム
瓱 ミリグラム
瓸 ヘクトグラム
甅 センチグラム
Liters
竍 デカリットル
竏 キロリットル
竕 デシリットル
竓 ミリリットル
竡 ヘクトリットル
竰 センチリットル
Meters
籵 デカメートル
粁 キロメートル
粍 ミリメートル
粨 ヘクトメートル
糎 センチメートル
BTW, Sasahara Yukihiro (笹原宏之) of Waseda U has a book on "dialect kanji" (方言漢字). An article he wrote on Sanseido Word-Wise Web introduces a few gems.
轌(sori), a combination of 車 and 雪, b/c a "sled" is a "snow vehicle"
But this one apparently has enough traction to be included in the Unicode set, i.e. one can type (or cut and paste) it. More interesting are some kanji found in local diaries, like:
and
both of which mean "blizzard" and are found in handwritten diaries from the "snow country."
Sasahara's article is here: http://is.gd/UzliSi
Victor Mair said,
August 27, 2013 @ 8:02 pm
From Jim Breen @ Nathan Hopson:
The inclusion of 轌 in Unicode is nothing to do with any "traction"
of that particular kokuji. 轌 has been in the main JIS kanji standard
since its inception in the early 70s, and all the kanji in the JIS
standards were/are automatically included in Unicode. All the established
kokuji went into Unicode for the same reason.
Chris Hansen said,
March 17, 2014 @ 2:21 pm
@ Matt
When I was teaching in Xi'an, my students who spoke Shaanxi Mandarin (关中话) pronounced 什么 as shá.
Travis said,
August 25, 2014 @ 12:04 pm
@Matt –
I don't really know anything about the linguistics/etymology of things like Kin 金武 and Kyan 喜屋武, but I've always suspected the same as you – that the 'n' (ん) derives from the 'mu' (む) sound of 武.
One of my favorite examples, along the lines of Kyan, of words or placenames that use more characters than syllables (or morae) in their pronunciation is the village of Bin – 保栄茂村 – also in Okinawa. I wonder if, similar to your idea of the evolution of mu into n, there was some gradual shift to the pronunciation Bin, from an earlier/original pronunciation closer to Ho-e-mo (or, since it's Okinawa, hu-i-mu or the like).