Symbols and signals in g-dropping
« previous post | next post »
In comments on my post about Tim Pawlenty's recent Iowa performance, various people have raised the question of vowel quality ([i] vs. [ɪ]) as opposed to consonant place ([ŋ] vs. [n]) as a feature of the phenomenon commonly (though misleadingly) known as "g-dropping".
This issue, though part of the folklore of sociolinguists, has not gotten the attention that it deserves, perhaps because it doesn't fit gracefully into the traditional intuitive frameworks of the relevant fields. In particular, it involves three areas where the boundary between symbols and signals gets blurry: vowel reduction, vowel-consonant coarticulation, and consonant-consonant assimilation.
As a result, discussing the topic will take us on a trip through some odd corners of English phonetics, phonology, and sociolinguistics. So consider yourself warned.
Let's start with some background on the vowel distinction involved.
In stressed syllables, all (?) native varieties of English distinguish vowels in the FLEECE lexical set (which we'll represent symbolically as [i]) from vowels in the KIT lexical set (which we'll represent symbolically by [ɪ]). The distinction is marked by duration (e.g. [i] is longer than [ɪ], other things equal), and by vowel height and frontness (e.g. [i] is higher and fronter than [ɪ], other things equal).
We can measure duration in seconds (though there are subtle questions about where the boundaries should be). For vowel height, a useful proxy is the frequency of the first oral resonance (the "first formant", or F1), where lower F1 values correspond to higher vowels; for vowel frontness, a useful proxy is the frequency of the second oral resonance (the "second formant", or F2), where higher F2 values correspond to fronter vowels.
Thus the Merriam-Webster Online Dictionary pronunciations of mead and mid:
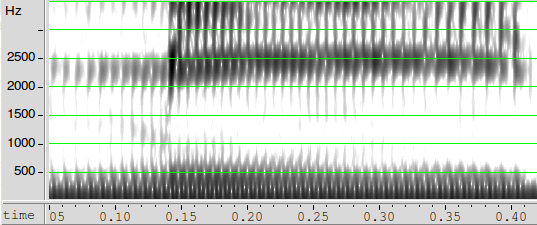
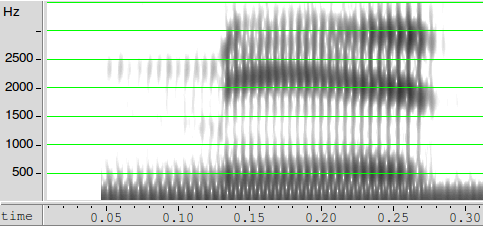
For these particular (hyperarticulated) performances, our proxy features have values something like these:
| mead | mid | |
| Duration (from m release to t closure) |
272 | 149 |
| F1 | 272 | 396 |
| F2 | 2442 | 2190 |
Of course, all of these dimensions are also affected by many other factors. Thus duration is affected by things including speech rate, phrasal position, emphasis, and syllabic context. And formant frequencies — the usual (and best) quantitative proxy for vowel quality — are affected in a major way by many things, including individual vocal tract size, articulatory effort, and local context. If your head is bigger, your vocal-tract resonances will be lower, for straightforward physical reasons. If you articulate your vowels and consonants in a weaker way, moving your jaw and tongue and lips less far away from a neutral position, the corresponding resonances will also tend to stay closer to neutral values, i.e. to be "reduced". And your jaw and tongue and lips don't move instantly from one position to another, but are required by basic considerations of anatomy, physiology, and physics to transit through all the intermediate positions, so that the corresponding sounds also show the same transitions.
All of these effects are fairly large, as we'll see, and so we either need to make comparisons that somehow hold constant everything we aren't interested in, or (more realistically) we need to model the effects and their interactions. But before we get to that, there's a crucial problem in the case of -in' vs. -ing — we're talking about unstressed syllables.
Unstressed syllables in English retain only a very limited set of phonological oppositions. In stressed syllables, there are more than a dozen alternative vowels. Depending on how many mergers your dialect has, and how you count diphthongs and combinations with /r/ and /l/ and so on, there might be twice that number — John Wells gives 24 "lexical sets" based on vowel pronunciation in stressed English syllables. But in (fully) unstressed syllables, this set of alternatives is radically reduced, Leaving out interactions with /r/ and /l/, there are at most three, as distinguished e.g. in Minna, Minnie, minnow. And in many contexts, there's only one option, at least for many speakers.
Thus some people are said to distinguish the second vowel in Alice from the second vowel in Dallas (the first being a bit higher and fronter, the second being lower and backer). I don't make this distinction, and I'm somewhat skeptical that anyone maintains it in non-hyper-articulated speech. In any case, minimal pairs involving vowels in unstressed closed syllables are somewhere between few and non-existent — and there are certainly no words in which /i/ contrasts with /ɪ/ in such a context.
So we have common, whose second vowel has a range of pronunciations that might license the use of symbols like [ə], [ɪ], [ʌ], etc., depending on the speaker, the context, and the phase of the moon. But unlike the case of e.g. pit, putt, pet, put, pat, Pete, etc., there are no other words that can be identified by making a different choice to fill in the blank in /ˈka.m_n/.
In particular, in the American dialects under discussion at least, there are no monomorphemic words that end in unstressed /in/, i.e. the vowel of the FLEECE lexical set followed by final /n/. Certainly there's no possibility of a contrast between a word like this and one where the /n/ is preceded by a vowel of the KIT lexical set. So how could it be that some people have such an opposition as alternative realizations of the gerund-participle ending -ing? Well, hang on, we need to get back to those other influences on vowel quality.
Here are audio clips and spectrograms from the Merriam-Webster online dictionary's pronunciations of bid and big:
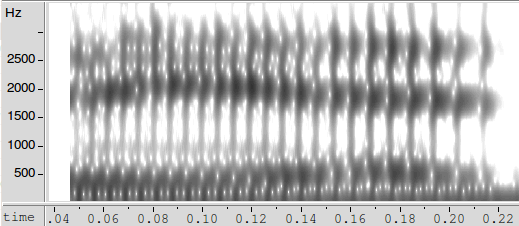
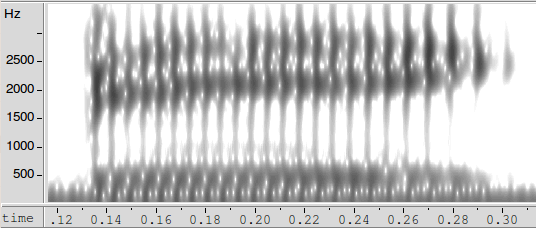
In the middle of this performance of big, the F2 is around 2080 Hz; in the middle of this performance of bid, F2 is around 2040. These are not meaningfully different from each other, and within the expected range of variation (see below) of the 2190 Hz that we observed above in the same speaker's pronunciation of mid.
But by the end of the syllable, big's F2 is at 2370 Hz while bid's F2 is at 1735 Hz, as a result of coarticulation with the final consonants [g] and [d] respectively — the tongue has to move smoothly from the position appropriate for the vowel to the position required to make the consonantal closures in the right places. The resulting difference of 635 Hz in the vocal-tract resonance near the consonant closure is more than twice as big as the difference of 252 Hz observed between the mid-vowel F2 values of mead and mid.
And the transition lasts around 60 msec. in the case of big, and nearly 100 msec in the case of bid. In ordinary speech in the middle of a sentence, the whole duration of the vowel in big or bid, from the release of the [b] to the closure of the code consonant, is likely to be in that same range.
For a more qualitative visual comparison, I've flipped the spectrogram for big horizontally, and placed it so that so that the end of bid is visually adjacent to the end of big:
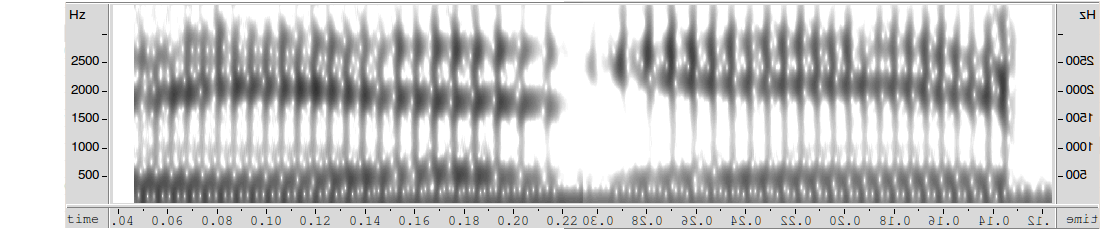
For a more systematic comparison of the scale of this effect with the scale of typical differences between [i] and [ɪ], take a look at this data from J.M. Hillenbrand et al., "Acoustic characteristics of American English vowels", Journal of the Acoustical Society of America, 97 (1995). I've plotted the distribution of F1 and F2 measurements for careful citation-form pronunciations of [i] and [ɪ] by 278 men, women, and children. Capital M, W, and C are performances of the FLEECE vowel by men, women and children respectively; lower-case m, w, and c are performance of the KIT vowel.

As you can see, a 500 or 600 Hz difference in F2 — as was caused by coarticulation with final [d] vs. [g] — is in the same range as the expected difference for male speakers' distinction between [ɪ] and [i].
So it's absolutely expected to find a large F2 difference in the coarticulated region of the vowel in a final syllable before a velar nasal as opposed to a coronal nasal, an F2 diference that's roughly as big as the difference between [i] and [ɪ] might be. Furthermore, in an unstressed -ing syllable in the middle of a sentence, the vowel is likely to be so short that the whole thing is coarticulated. Thus we expect to see a significant average difference in measured vowel quality between cases where the morpheme spelled -ing is realized with a velar nasal and cases where it's realized with a coronal nasal — just because of the expected coarticulatory effects.
And there are a couple of other relevant facts about English pronunciation in context. Final nasal consonants may assimilate in place of articulation to a following onset. Thus the /n/ of in in "in principle" is likely to become [m] in fluent speech. And syllable-final nasals may be manifested in fluent speech only as nasalization of the preceding vowel, with little or no phonetic residue of the nasal murmur that we think of as a nasal consonant.
Putting all of these things together, it seems that some speakers have re-analyzed the -ing vs. in' distinction as involving a difference in vowel quality. For some people, this may be a redundant feature that simply establishes the coarticulatory difference as a fact about lexical representations rather than a fact about phonetic performance. For others, it may have become the primary or even the only exponent of the "g-dropping" difference. And still others, it seems, may have settled on a lexical representation for -ing that combines the higher F2 of the velar-nasal version with the consonantal place of the coronal-nasal version.
I used "seems" and "may" repeatedly in the previous paragraph because (as far as I know) there are no systematic studies of this range of phenomena. As I mentioned, it's part of the folklore of sociolinguistics that the [in] pronunciation exists, and that it's (apparently) not stigmatized in the way that the [ɪn] pronunciation is, and that in fact it may be heard as [ɪŋ] or [iŋ] and even transcribed that way in some studies. But given how much attention has been (for good reasons) given to g-dropping, it's odd that this angle has been so neglected.
Eric Raimy said,
March 23, 2011 @ 11:21 am
Great post. Note that the 'mead'~'mid' table is misformatted. It appears that the formant values for 'mead' are both F1 and the formant values for 'mid' are F2. This may confuse some readers.
[(myl) Oops. Fixed now.]
John Cowan said,
March 23, 2011 @ 11:29 am
There is no doubt that there are varieties of English, including RP, in which the Weak Vowel Merger has not operated . A good test word is chicken, because the unmerged pronunciation /ˈtʃɪkɪn/ gets no support from the spelling, and we can readily check whether the two vowels have identical quality — in other people. I say "in other people" because people are often quite unreliable about whether they have the merger or not: unstressed vowels are hard to bring into psychological focus for some reason, even for people with some phonological knowledge, whereas stressed vowels are much more accessible to introspection. It took me years to definitely determine that I have the merger.
Greg Morrow said,
March 23, 2011 @ 11:30 am
If I understand properly, the F1 row in the first table is actually the F1 and F2 data for the MEAD column, and the F2 row is is the MID data.
Greg Morrow said,
March 23, 2011 @ 11:31 am
Whoops; you fixed it while I was reading.
D Sky Onosson said,
March 23, 2011 @ 11:35 am
Thank you for this post! I find it interesting that this area has been so neglected. As I mentioned in a comment on the other post on this topic, in my own dialect I "hear" a pronunciation difference involving the vowels, with both versions having a coronal nasal, with a velar possible for the FLEECE vowel but not especially common – in fact, pronouncing a word like "thinking" with a full [ŋ] sounds decidedly weird to me. The two syllables of "thinking have very distinctly different nasals at the end, but pretty much the same vowel.
I wrote an MA thesis recently which focused on vowel formants as they change throughout a vowel's duration, which is also something that hasn't gotten a lot of attention in the literature, as far as I've been able to tell. I do wonder how qualitatively similar the vowels in big, bid, bean, bin, and lobbing vs. lobbin' are. I suspect that it's really not as straightforward as [i] vs. [ɪ], and that some of the vowels will simply be somewhere in the middle – but that's just a suspicion at this point.
D Sky Onosson said,
March 23, 2011 @ 11:37 am
To be clear, for me "thinking" has a velar nasal in the first syllable, and a coronal in the second, just the opposite of what the spelling would suggest.
Got Medieval said,
March 23, 2011 @ 1:07 pm
Is there a name for the related phenomenon of -ing spacing? Like in Rebecca Black's song, Friday, where she is " 'get-en' down on Friday."
Nathan said,
March 23, 2011 @ 1:07 pm
Best. Post. Evar.
un malpaso said,
March 23, 2011 @ 1:55 pm
"Furthermore, in an unstressed -ing syllable in the middle of a sentence, the vowel is likely to be so short that the whole thing is coarticulated."
That makes sense, because on reflection, any time I "drop the g" (convert the velar into a coronal) I am also likely to be speaking much faster and in a more casual register than when I am consciously enunciating the velar nasal. This seems to be what causes the further neutralization into almost a schwa unstressed.
It's likely that other English speakers have the same general tendency… funny there hasn't been much research on it, especially with the ending's grammatical importance and diachronic history.
[(myl) Just to be clear, there's been lots of research on g-dropping — see e.g. here for description fo the results of a few classic studies. The gap is in research on the perhaps-independent vowel quality differences.]
Greg Morrow said,
March 23, 2011 @ 1:59 pm
I'm sorry, but are the F1 numbers for "mead" and "mid" still in error? "mead" is higher, so F1 should be lower (according to the text). This also corresponds to the spectrogram — mead has much more separation than mid.
[(myl) Darn. How many ways can I screw up a 2×2 table? Well, there are 24 possible assignments of values to cells, only one of which is right. So far I've been through three of them. I think it's fixed now.]
Mel Nicholson said,
March 23, 2011 @ 2:35 pm
I'm feeling retroactively jealous of the processing power implied by all the data above. In the late 80's and early 90's, the speech recognizers were based on auto-segmental variation. Looking at formant heights in vowel tails was the only indicator our processors of that era could process remotely fast enough to indicate articulatory position in a post-vocalic stop. 1700-1750 Hz was the consistent number for alveolars. Labials and velars varied a bit across dialects, but it was fairly easy to calibrate based on relative position and a few exemplars. [/nostalgia]
GeorgeW said,
March 23, 2011 @ 3:39 pm
Great post. What happened to the tense/lax distinction?
Ken Brown said,
March 23, 2011 @ 5:44 pm
How do Americans say "morphine"?
(I assume that few of them ever say "saltine")
For me that word has a final unstressed /in/
[(myl) In my speech, and also in the Merriam-Webster dictionary, saltine has final-syllable main stress. If some people pronounce it with initial main stress, and an unreduced [i] in the second syllable, then (like morphine or one of the pronunciations of saline) it would conventionally be transcribed with secondary stress on the second syllable.
Aside from circularly maintaining the proposition that there aren't unreduced vowels in unstressed closed syllables, this view does have some empirical support. For example, (most) American speakers flap and voice the 't' in words like carpeting or rickety, but don't do so in words like appetite, nicotine, etc, where the following vowel has a secondary stress. I can't offhand think of many words like saline or morphine where the intervocalic consonant (or cluster) is one where flapping/voicing would normally occur, as in city or forty. The only example that comes to mind is protein, where neither I nor M-W have flapping/voicing. Otherwise, the best I can come up with is examples like "thirteen men" or "sateen rabbit", where contextual effects (known as the "rhythm rule" or the "thirteen men rule") would shift the first word's stress onto the first syllable, but flapping/voicing still doesn't happen. (Maybe someone can think of some -ene compounds whose root ends in Vt or Vrt? The prediction would be that their t's also don't exhibit the allophone expected if the following vowel were unstressed.)]
Matt said,
March 23, 2011 @ 6:05 pm
@Ken
For me (from North Carolina) "morphine" has final unstressed /in/ and "saltine" has stress on the second syllable.
Nathan said,
March 23, 2011 @ 6:09 pm
@Ken Brown: I'm an American who has frequently said "saltine" throughout my life. It's not a foreign word or anything. But it has final stress.
The word "morphine" is more interesting. For me it's something like /ˈmorˌfiːn/, and I think it forms a minimal pair with "morphing"—the vowels seem identical.
John said,
March 23, 2011 @ 6:39 pm
@Ken Brown: 31-year-old American who grew up in California and Seattle here, and I am fairly sure (without having done a spectral analysis…) that I and my peer group would pronounce "morphine" with an unstressed final /in/ as well. I suppose there's even a minimal pair here with "morphin(g)," as in "Mighty Morphin' Power Rangers" (why do I still remember those?). Interesting.
Actually, Nabsico-brand saltine crackers are common enough stateside that I have a fairly definite idea of how to pronounce it, and to my ear it sounds like there is a final *stressed* /in/ there. (Well, I know self-reports are unreliable, and now that I think about it the difference in stress between the two syllables in sal-tine sounds slight to me.)
army1987 said,
March 23, 2011 @ 6:50 pm
and there are certainly no words in which /i/ contrasts with /ɪ/ in such a context
For people with “happy tensing” and without “roses-Rosa's merger”, studied/studded, taxis/taxes, roses/Rosie's, candid/candied…
[(myl) A good point. Let's say, at least, that such oppositions are limited to very specific morphological environments, rather than being part of the general system out of which the pronunciation of monomorphemic words is constructed. The point of this post is that a similar sort of thing is going on for those people who realize -ing as [in].]
m.m. said,
March 23, 2011 @ 6:55 pm
"Morphine" and "Saltine" rhyme for me, though it's almost always plural "saltines" in regular speech [nobody ever asks for a single saltine :P]; "morphine" would definitely be a minimal pair with "morphing", both with [i].
Funny, 'chicken' is closer to /ˈtʃeken/ for me. As for the weak vowel merger, I'm basically transitional. Some pairs are definitely not merged [rosa's-roses] but some have a great tendency to merge even in careful speech [affect-effect, incidentally leads to spell by sound problems].
It's funny that in hypo-articulated speech, I perceive the difference to be greater than in hyper-articulated speech in the pairs where I still maintain the difference, like alice-dallas.
michael farris said,
March 23, 2011 @ 7:33 pm
I'm not sure if morphine and saltine rhyme for me. Morphine has stable initial stress but after trying different versions of saltine I'm inclined to think that either syllable can take primary stress and I'm not sure which is more natural for me.
Also the final syllable of morphine has secondary stress so it's not a homophone with morphing. If we assign stress levels from 1 to 3 in descending order 1 = primary stress, 2 = secondary, 3 = unstressed) then morphing and morphine are a minimal pair for the 1-3 and 1-2 stress patterns (in my dialect).
Another example of that contrast for me would be Reagan and ray-gun.
Coby Lubliner said,
March 23, 2011 @ 10:04 pm
There are actually quite a few words like morphine, at least in some pronunciations: chlorine, protein, scalene, melamine, alexandrine…. In all these words, pronouncing dictionaries indicate a secondary stress on the last syllable, but that seems to be begging the question: it's as if, by definition, an unstressed closed syllable whose vowel is not one of the standard unstressed set ([ə], [ɪ], [ʌ]) carries secondary stress.
Neal Whitman said,
March 23, 2011 @ 10:25 pm
I blogged about pre-engma tensing here in 2008, bringing in a blog post from Eric Bakovic and some discussion on the American Dialect Society email list.
[(myl) Thanks for this. There are lots of Americans (and probably plenty of other English speakers) for whom the vowel in words like king, ring, sing is (more) like the vowels of the FLEECE set than like those of the KIT set. My wife, who grew up in Texas, is one such person. As far as I know, however, there's no variety of English that has an opposition before velar nasals that's parallel to kin vs. keen, or rip vs. reap.
Anyhow, as I noted in a comment on the Pawlenty post, it would be plausible for those people who have [i] in king to have a similar vowel in -ing (where the velar is retained). But I don't know whether this has been systematically studied.]
Xmun said,
March 24, 2011 @ 12:40 am
chlorine, protein, scalene, melamine, alexandrine
Which is the odd man out? The final vowel is [i:] in all of them except the last, where it's either [ɪ] or [ʌɪ]; that's to say, where the final syllable rhymes with either "fin" or "fine".
Thus, at any rate, the New Oxford Dictionary of English (1998).
Richard Sabey said,
March 24, 2011 @ 2:50 am
@army1987 What does happy-tensing have to do with your examples? They all end in consonant sounds. I'm a happy-tenser (I have [i] in study, Rosie etc.) but I have [ɪ] in all your 8 examples.
@Coby Lubliner I disagree that it's begging the question. The final syllables of "cosset" and "parrot" have no stress; the final syllable of "format" has secondary stress. How can this be deduced? The double t in "formatting" is obligatory.
CIngram said,
March 24, 2011 @ 2:50 am
I'm almost certain I distinguish the unstressed vowel in Alice from that in Dallas, the latter being schwa and the former /I/ (maybe less high and fronted than when stressed) even in rapid speech.
And I definitely distinguish the unstressed vowel in the plural of base from the one in the plural of basis, giving a minimal pair with unstessed /i/, /I/.
Native of South East England. University degree.
J. Goard said,
March 24, 2011 @ 4:04 am
@Neal:
The post you linked to was great! I vividly remember the prolonged mutual confusion, even bordering on a fight, with the (Peruvian) professor I was T.A.ing for, when my (Northern Californian) phonemic perception ("pre-engma tensing") first came to his awareness, and the lack of such in other American speakers first came to mine.
BTW, I also grew up using a similarly raised vowel before /g/, i.e. the vowel in both bag and beg sounded like bake. Now (probably since about high school), my bag is standard (like back) but my beg is still like bake, not Beck.
J. Goard said,
March 24, 2011 @ 4:07 am
Ah, forgot to link to this very cool paper which uses the bag/back vowel contrast to test competing hypotheses about listeners' perception of speech in a different dialect.
GeorgeW said,
March 24, 2011 @ 5:15 am
@Richard Sabey: "The final syllables of "cosset" and "parrot" have no stress."
Coby's point, I think. They are pronounced with a schwa.
Are there any stressed syllables with schwa in English? I can think of none.
Leo said,
March 24, 2011 @ 5:48 am
[NOTE: subjective self-analysis follows]
@Richard Sabey: I'm also a happy-tenser, and I contrast "taxis" and "taxes" as ˈtæksiz and ˈtæksɪz, just as army1987 suggested. For me, the unstressed i in "happy" words is not neutralised to ɪ by the addition of a final consonant, so happy-tensing is still relevant. Apparently that's not the case for you.
Admittedly I'm talking about studied (ˈstʌdid) speech here. Ask me to read them aloud, and I will distinguish "taxis" from "taxes"; but I'm prepared to believe that I might not always do so in natural speech.
(26, South East England)
GeorgeW said,
March 24, 2011 @ 6:04 am
Leo: Recognizing the limitations of self analysis, I am certain that I (Southern AmE.) distinguish 'taxis' and 'taxes' in all registers and speeds.
If I try to lax the final vowel in 'happy,' I feel like it sounds British RP.
army1987 said,
March 24, 2011 @ 6:29 am
Are there any stressed syllables with schwa in English? I can think of none.
I've heard claims that doesn't for some speakers does.
Leo said,
March 24, 2011 @ 7:02 am
@GeorgeW: indeed, a lax vowel in "happy" is (or at least was) a feature of RP, according to Trudgill.
But our question is: if (like me, you and Richard Sabey) you have a tense vowel at the end of a word ("study" = ˈstʌdi), does it stay tense when a consonant is added ("studied" = ˈstʌdid)? The answer seems to be yes for me and you, but no for Richard Sabey and surely many others.
Rodger C said,
March 24, 2011 @ 7:40 am
Wile we're on the topic, can anyone comment on my impression that many Eastern Europeans speaking English pronounce HAPPY with an almost exaggeratedly lax final vowel that would seem to have nothing to do with their native languages? Is this, as I've heard, a feature of English instruction fossilized for many years behind the Iron Curtain?
Eric S said,
March 24, 2011 @ 11:56 am
Awesome post, thanks very much!
Eric P Smith said,
March 24, 2011 @ 12:04 pm
This is fascinating.
My variety of English is Scottish Standard English. I have three very distinct vowels: [ɪ] for the KIT lexical set, [i] for the FLEECE set, and a vowel intermediate between them, very close to [e], when /ɪ/ is followed by a velar or is word-final. Thus in my speech the two vowels in the word ‘lady’ are almost identical.
As a linguistics student last year, I participated in a project on g-dropping, and I was mystified at being unable to find any reference in the literature to the vowel difference between words like ‘sin’ and ‘sing’. In my speech there is a big difference. In the speech of many other Scots there is an even bigger difference, and /sɪn/ ‘sin’ is almost [sʌn].
[(myl) Interesting. There are several similar issues (e.g. the quality of vowels before /r/ and /l/) where there's a great deal of variation that has been less well studied that it deserves to be. As you observe, the vowels in these cases (merged or otherwise) often don't really correspond well to any of the distinctive cases in other environments.]
Rob P. said,
March 24, 2011 @ 12:34 pm
The existence of a roses/Rosa's merger surprises me. I'm a native English speaker, but with some Mexican (Texican, anyway) family. I pronounce not only the vowel pair e/a differently, but the r/R and s/s pairs both also sound different.
Pflaumbaum said,
March 24, 2011 @ 12:51 pm
@ Rob P.
In what way different? Can you describe it?
I too have different reduced vowels here (RP/Estuary, so [ə] versus [ɨ]), but the other segments are identical as far as I can tell. What could be motivating the different /r/ and /z/? Are you pronouncing Rosa like a Spanish name with a proper accent?
Jerry Friedman said,
March 24, 2011 @ 3:34 pm
@GeorgeW.: A lot of linguists appear to believe that in American English, the schwa is the vowel in cut, up, summon, etc. See for instance Merriam-Webster or John Lawler's modest proposal, in which he transcribes the first vowel in jumping as a schwa (and the second as an ɪ).
I feel, subject to more than the usual caveats, that I may say un- slightly lower and farther back than an-. I can't think of any minimal pairs, but unhonored and anonymous might be close enough. Supposing for the sake of argument that someone does have a pronunciation, am I right in thinking that jump-has-a-schwa linguists would say I have a secondary accent on un-? Would there be a non-circular way to show that? (I think I might actually do that.)
@Rob P.: As an American, I'd have guessed that all Americans merge Rosa's and roses. I was well along in years before I even heard of the possibility of not doing so. I really think most Americans merge them. In my case, it may have to do with my thinking of "Rosa" as a normal English name.
Nobody has mentioned tensing, if that's the right word, in bank, hang, etc., and in strength and length. So I'll just leave it that way.
m.m. said,
March 24, 2011 @ 4:11 pm
I'd guess you're using [s] for both "Rosa's" and "roses", as "roses" is commonly [z] when I hear it. The /r/'s are generally the same. I'd hear "Rosa's" with [r] in denser spanish speaking areas though, Texas would be fitting.
Rob P. said,
March 24, 2011 @ 6:26 pm
roses – r-o-z-e-s. Rosa's – partially rolled r-o-s-a-s, almost like hr. Sorry I don't know IPA to better define what I mean. I don't completely roll initial R, but it does have a flap quality to it when I say certain Spanish-origin names that I'm used to hearing spoken by native Spanish speakers. Roberto, Rosa, Ronaldo, etc. On the s/s, one sounds like z (roses), the other s like snake.
Pflaumbaum said,
March 24, 2011 @ 7:07 pm
So the issue is that you're basically pronouncing Rosa with something of a Spanish accent.
When people talk about roses / Rosa's as a minimal pair, they mean Rosa's pronounced as an ordinary English name, as in Rosa Parks. In IPA this is /roʊzəz/ (or in my accent /rəʊzəz/), where /ə/ is the unstressed sound you hear in, say, the second vowel of necessary; whereas for roses I have /rəʊzɨz/, where /ɨ/ is the vowel you can hear in the audio clip linked below, somewhere between the /i/ of seen and the /u/ of soon, but shorter and with no lip-rounding. If you know Portuguese as well as Spanish I think you get it there, it's also very common in Romanian.
http://en.wikipedia.org/wiki/Close_central_unrounded_vowel
You could test your reduced vowels with a different pair, like rushes / Russia's – assuming you don't pronounce Russia's with a Russian accent ;)
Rodger C said,
March 24, 2011 @ 8:10 pm
@Pflaumbaum: Or assuming he isn't one of those, if any are still alive, who pronounce Russia with the vowel of rooster.
m.m. said,
March 25, 2011 @ 4:14 am
@Pflaumbaum
I was reading your reply, and I was like, what? The second vowel in "necessary" isn't a schwa, it's a schwi like [ɨ].
Ooh, I distinguish between the rushes/Russia's pair :D
Pflaumbaum said,
March 25, 2011 @ 6:19 am
Yeah sorry, that was a dumb example plucked from my own idiolect and pretty much begging the question.
Rob P. said,
March 25, 2011 @ 9:45 am
Pflaumbaum – You must be right that I'm saying Rosa's with a Spanish accent. What's odd is that I'd say that if I were actually speaking Spanish, it would sound different. I think it must be somewhere in the middle. I don't pronounce my own last name the proper Spanish way, and I usually speak English with something of a Southern accent (raised in VA, lived in SEVA for about 10 years), but I code switch for work sometimes. I definitely distinguish the e/ia pair in rushes/Russia's.
Jarek Weckwerth said,
March 25, 2011 @ 11:28 am
@ Nathan: Best. Post. Evar. I *SO* wanted to say this. Early bird etc., it seems… I've been quite late to the party.
@Roger C: impression that many Eastern Europeans […] pronounce HAPPY with an almost exaggeratedly lax final vowel that would seem to have nothing to do with their native languages? Is this, as I've heard, a feature of English instruction fossilized for many years behind the Iron Curtain?
Well, most Polish people do this. But in fact this is perfectly in line with Polish grapho-phonemics. Polish y always stands for /ɨ/, which is remarkably central. Thus /rɛdɨ/ for ready. Pretty simple. So it's absolutely not the case that it has nothing to do with their native languages, on the contrary. It's actually quite difficult to (un)teach even in quite advanced students. And while it is true that the /ɨ/ can get reinforced by teaching by people who believe it's acceptable in "standard" English (it may have been in 1950s U-RP, but of course isn't any more), I deeply doubt if this is an appreciable influence. About other "Eastern European languages", I don't know. There are quite a few different ones.
Rodger C said,
March 26, 2011 @ 11:25 am
@Jarek Weckwerth: Thanks. I last noticed it on the radio, though, from a speaker from the former Yugoslavia. If there's a similar vowel in Serbocroatian-or-whatever-it-is-now, it's not reflected in the orthography. I always seem to notice this especially with adverbial "-ly."
sandra wilde said,
March 26, 2011 @ 1:21 pm
I noticed years ago that children's invented spelling often includes forms like DECEN for drinking, which reflects, I believe, a pronunciation like drinkeen rather than drinkin,' which (the former) is a completely unstigmatized alternative to the /ng/ proununciation.
Mark Liberman said,
March 30, 2011 @ 4:24 am
In the interests of improved signal-to-noise ratio, I've removed some gnonsense from "Atmir Ilias", along with some noble but misguided attempts by others to figure it out. If you're interested, the exchanges are preserved here.
Ellen K. said,
September 28, 2011 @ 9:01 am
This is making much more sense to me now than when I first read it. And answers the questions I've had.
m.m. said,
May 19, 2012 @ 4:19 am
Like Ellen K., reading it again, I feel like a face palming is in order.
[in] exists in chicano english and has spread to non chicano speakers in california (and seemingly texas), where it is indeed more of an allophone of [ɪŋ] or [iŋ] and different to [ɪn].
they had (finally) done a piece in the LA times regarding chicano english
I only recently became concious of this, albeit low frequency, trait in my own speech (which is not chicano at all), and seemingly treat it as an allophone; I wouldnt have noticed my usage before, and i still don't notice if/when I or others use it. Compared to [ɪn] which does and has always made my ears perk up (probably more so because my main source of english while young was standard or academic speech, which we all know doesnt 'allow' "g-dropping")