How you speak and how you think you speak: Part 1
« previous post | next post »
Among the comments on yesterday's pin-pen post, Eric (one of several) asked:
Hey academic linguists, I have a nerdy question. I assume that in phonetics "field research" or whatever, lots of scenarios have several investigators listen to a speaker, make independent IPA transcriptions, and then check their transcriptions against each other. And then when the various transcriptions show some level of convergence, that's taken to be the correct phonetic description of the speech. But are there ever scenarios where the results of the investigator's transcription is checked, not against the transcriptions of other listeners/investigators, but against the speaker's own belief about her pronunciation? As someone who merges like 90% of the pairs mentioned in this thread, I'm interested in pushing a radically skeptical line: that speakers are often subjectively convinced they make a phonetic distinction (like Mary v. marry) which objective investigation would dis-confirm…
Actually, Eric, your skepticism about the relation between how people speak and how they think they speak is not nearly radical enough. And there are actually three things to consider: not only how people speak and how they think they speak — which may be bizarrely different — but also how they hear.
However, I'm not going to discuss all three of these topics. A nerdy question deserves a nerdy answer, and so I need to start by pointing out that your picture of phonetic investigation is incomplete. And it's going to take me long enough to sketch an answer to the first question — how to characterize how someone speaks — that I'll leave the other two parts for later posts.
It's not enough to "listen to a speaker", because the way you talk depends on the role you're playing, your audience, and your psycho-physiological state. Are you giving a speech? Reading out loud to a child? Reading a list of words in an acoustically-isolated laboratory chamber? Telling a joke to a friend? Arguing with a family member? Giving directions to a foreigner? Are you happy and exuberant, tired and depressed, or somewhere in between?
Linguists use various techniques to get recordings of different sorts of speech — and it's common to compare speech from the same speaker in different settings. Here's a graph (from Labov, The study of nonstandard speech, 1969) showing the percentage of "g-dropping" in three speech styles from members of four socio-economic classes in New York City:
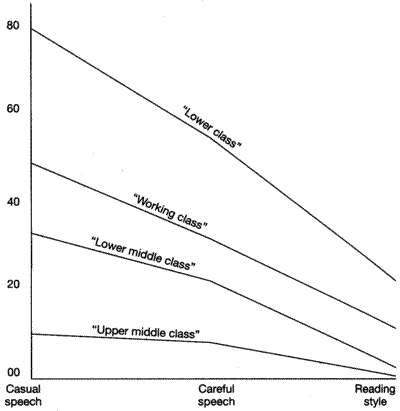
(For more discussion, see here.)
"G-dropping" is a categorical choice — whether to use a coronal nasal [n] or a velar nasal [ŋ] in the gerund-participle ending -ing. As common sense tells you, and as the plot above suggests, speakers are variable. They don't always use [n] or always use [ŋ]. Instead, they mix them up in proportions that depend on lots of things, including degree of formality.
This variability takes on a new aspect when we look at a gradient linguistic choice, such as where to place a particular vowel, on a particular occasion, in a continuous articulatory and acoustic space.
For the study of phonetic variation in vowel pronunciation, IPA transcription is not very helpful, partly because it's a subjective description with imperfect inter-transcriber agreement, but mostly because it forces us to assign tokens to one of a small number of distinct categories. Instead, the standard approach is to measure the "formants", or resonance frequencies of the vocal tract, which are a useful quantitative proxy for vowel quality. (Sociolinguists generally characterize an individual vowel in terms of a F1 and F2 at a single point deemed characteristic of its quality. This abstracts away from the vowel's duration and time-varying properties, and from F3 and other spectral characteristics, in a way that is sometimes problematic — but introducing these additional complexities wouldn't change the discussion below in significant ways.)
For an excellent example of such an analysis, see chapter 6 (pp. 132-194) in Keelan Evanini, "The permeability of dialect boundaries: a case study of the region surrounding Erie, Pennsylvania", Publicly accessible Penn Dissertations, Paper 86 (2009). This chapter is all about the merger of the vowel categories in cot and caught. Here's Keelan's explanation of the background:
The short-o vowel is represented here by the symbol /o/, following the notation in the ANAE, and it corresponds to the LOT vowel class in Wells (1982). It is descended primarily from short o in Middle English, and occurs in nearly all segmental environments. Some examples of words with /o/ include lock, pot, god, and stop.
In most dialects of North American English, /o/ has been unrounded and lowered to [ɑ]. In many of these dialects, /o/ has moved towards the front, and is unrounded. In these dialects, the best phonetic representation would be [a]. This is especially the case in the North where the fronting of /o/ as the second stage of the Northern Cities Shift has caused /o/ to move close to the position formerly occupied by /æ/. In other dialects, /o/ has maintained its roundedness, merging with /oh/ in the low back position. This is the case for the Western Pennsylvania dialect centered around Pittsburgh.
The symbol /oh/ is used to represent the long open-o class, and corresponds to Wells’ THOUGHT lexical set. It is derived primarily from the monophthongization of the Middle English diphthong au, which itself was derived from a variety of sources (such as Old English /aw/, OE /a/ + /x/, as in fought, vocalization of OE coda /g/, as in draw, and Middle French loan words, as in applaud). Another large source for /oh/ words was the lengthening of /o/ to /oh/ before voiceless fricatives, as in lost, and the velar nasal, as in strong. The distribution of /oh/ is severely restricted, and it occurs before only a small number of consonants, mainly before /t/, /d/, /k/, /z/, /n/, /l/, and word-finally. Some examples of words with /oh/ include thought, hawk, caught, and law.
In dialects of North American English where /o/ and /oh/ have not merged, /oh/ has changed in three different directions: 1) In the Mid-Atlantic region and New York City it has raised substantially and developed a central offglide, 2) In many areas of the South, it has developed a back upglide, and 3) In the North, it has lowered and fronted as Stage 3 of the Northern Cities Shift. In dialects where /o/ and /oh/ have merged, /oh/ can become unrounded and rather front, especially in the West.
Here's an F1/F2 scatterplot of 56 /o/ vowels and 24 /oh/ vowels from the speech of someone who maintains a robust distinction:

Figure 6.1: /o/ and /oh/ from Walter K., born 1927 in Buffalo,
Mean(/o/) = (841, 1451), N=56; Mean(/oh/) = (684, 1044), N=24; Dist(/o/, /oh/) = 436
In such plots, the origin is by convention in the upper right-hand corner, which makes the dimensions of vowel quality run the same way that they do in the IPA vowel chart: front-to-back on the horizontal axis, and low-to-high on the vertical axis. (These scatterplots only show the small area of the vowel space occupied by the collection of vowels being displayed.)
As the plot indicates, Walter K.'s /oh/-vowels are substantially backer and a bit higher than his /o/-vowels, though there's an indication of occasional overlap, perhaps especially for certain words.
Here, in contrast, is a similar plot for someone who pretty thoroughly merges the categories:

Figure 6.4: /o/ and /oh/ from Dan R., born 1912 in Erie,
Mean(/o/) = (704, 1338), N=55; Mean(/oh/) = (707,1283), N=31; Dist(/o/, /oh/) = 55
Keelan's comment:
His means for /o/ and /oh/ are only separated by 10 Hz in the F1 dimension and 78 Hz in F2. The two vowel clouds show considerable overlap throughout their entire ranges. To complement this acoustic evidence, the minimal pair data from Dan R. also point to a complete merger. He produced the pairs cot / caught and Don / dawn identically and judged them both to be the same.
There's a hint in the scatterplot that Dan R. might still have some residual tendency towards a fuzzy distinction — and there are plenty of "transitional" speakers whose distributions are more clearly distinct, though still heavily overlapped. Here's an example:

Figure 6.7: /o/ and /oh/ from H. O. Hirt, born 1887 in Erie,
Mean(/o/) = (745, 1311), N=36; Mean(/oh/) = (664, 1074), N=21; Dist(/o/, /oh/) = 250
So to sum up what we've got so far:
1) Speakers are variable. In the case of categorical choices, individual speakers rarely behave in a consistent way, taking a given alternative 0% of the time or 100% of the time. More often, their behavior is somewhere in the middle, and is modulated by circumstances in a complex way. And in the case of gradient choices like vowel quality, an individual speaker must be characterized as a "cloud" of possible outputs, a multi-dimensional probability distribution that again is modulated by circumstances in a complex way.
2) The "behavior cloud" corresponding to a particular speaker's propensity to pronounce a particular vowel category often overlaps with the same speaker's cloud for a nearby vowel category. This remains true even if we keep the circumstances as constant as we can.
As a result, the question of a whether an individual speaker is "merged" or "unmerged", with respect to a particular pair of vowel categories, may not have a clear, categorical answer. Their productions may overlap to a degree while remaining to some extent distinct; and the degree of cloud overlap will typically vary with style, speaking rate, vocal effort, formality or precision of articulation, and so on.
Next time: how well do speakers know themselves?
Tadeusz said,
July 28, 2010 @ 9:32 am
This is a fine nerdy answer. However, I would have one question: can this objective, quantitative approach to description of sound segments establish what are distinctive oppositions/contrasts? Or are these oppositions established — subjectively ? — by the speaker on the basis of his/her competence? I think that I can hear, and imitate, sounds in various languages, but I have no idea which sounds form oppositions, which are allophonic, or which are individual preferences of the speaker on the given occasion.
[(myl) This line of research presupposes that there's a qualitative phonological distinction, with known lexical support and generally understood quantitative phonetic correlates, which appears on the face of it to have been lost by some speakers. We're interested in a careful, quantitative study of how this merger is distributed in time, space, and social structure. And our study needs to be sensitive to the fact that individual speakers and groups of speakers are likely to be in a transitional state, and also to the fact that subjective judgments of what is "the same" are not very reliable, especially in the transitional stages.
A similar approach could be (and has been) used to investigate the development of new qualitative phonological categories.
If we're starting from scratch to try to figure out what the phonological inventory of a newly-studied language is, then a different methodology is appropriate — which may leave some loose ends of this kind to be tidied up, but will sketch out the basic system fairly quickly.
If you're asking whether it's possible to automatically (i.e. computationally) induce the relevant phonological categories from a corpus of recordings, the basic answer is "no", but there are some interesting research ideas in that area that might the topic of another post.]
Randy Alexander said,
July 28, 2010 @ 11:38 am
Don't your overlapping clouds ignore the speed of speech which you carefully brought to our attention in the first chart? When I say cot/caught, they are merged in allegro speech, but distinct in "careful" or "reading style" speech.
It seems to me that mergers are more complex than "merge" vs "not merge", and depend heavily on how "carefully" the speech is delivered. Isn't that the key to the variability in a speaker? (Or is it more complex even than that?)
[(myl) Another factor that's ignored is phonetic context — especially in shorter syllables, vowel formants are heavily influenced by surrounding articulations. But you could get similar plots for controlled lists of words spoken carefully in isolation — see e.g. Hillenbrand et al., "Acoustic characteristics of American English vowels," Journal of the Acoustical Society of America 97: 3099-3111, 1995, for which the raw data and formant measurements are available here.
In Evanini's dissertation chapter, he took his values from a variety of speech styles, because in the case of historical data, he had to work with what was available. So there are measurements from interviews, narratives, story reading, and word lists, all of which give a quantitative picture that agrees qualitatively, at least in broad outlines, with more subjective impressions of who has the merger and who doesn't.
Similar same techniques could be used to test your belief that you merge cot/caught in allegro speech, but keep them separate in careful speech. My own guess would be that if you really keep them well separated in careful speech, there's a good chance that your distribution in recordings of casual conversation or informal narrative would also be statistically distinct even if heavily overlapped.
This is not always true — some Americans, for example, undo flapping and voicing in hyper-careful speech, so that they are capable of distinguishing latter and ladder in this rather artificial way, even though they merge them completely in more natural circumstances (including normal reading style). And you may be an instance of the reverse "Bill Peters effect".]
Peter said,
July 28, 2010 @ 12:44 pm
Regarding the g-dropping post, I didn't see the Sopranos episode in question, but could the guest actor have actually pronounced "motherfucking" both without dropping the g and with a hard g?
I do a mean impression of James Hatfield (lead singer of Metallica), where I'll say something like "I am getting a drink of waterrrrrrrrah!" (or more obnoxiously, I add the "ah" to every word, "Iiiiah ammmmah gettinnnnnngah…"). Could the actor have said "motherfuckingggg-guh" (the last sound more of an an exhaled hard g sound than actually enunciating a hard g sound)?
[(myl) Could? Maybe. Did? No. Should have? Unlikely, since the word in question is pretty much always used as a preceding modifier, whereas the kind of performance you cite (even if it were appropriate in this case, which it wasn't) is excessively weird outside of pre-pausal contexts (and weird enough there).]
Peter said,
July 28, 2010 @ 12:59 pm
@Mark: Thanks for the clarification. Like I said, i didn't see the ep or have any context. I could see it in a piece of dialog where the character is trying to emphasize each word. "Do. Your. Motherfuckinggg-guh. Job."
(For some reason, I am visualizing Tom Wilkinson saying this line in an American accent. Actually, I think I have oftenheard that pronounced "hard g" — what would be the technical term for what I am describing? — from British actors doing American accents. Perhaps that's something, depending on which native British accent an actor has, that an actor needs to focus on to affect an American accent, provided the American character wouldn't drop their g in the first place.)
David Costa said,
July 28, 2010 @ 5:28 pm
"some Americans, for example, undo flapping and voicing in hyper-careful speech, so that they are capable of distinguishing latter and ladder in this rather artificial way, even though they merge them completely in more natural circumstances"
My teenage daughter takes this in a different direction. She naturally merges words like 'latter' and 'ladder', but what's really remarkable is that in careful speech, she can unflap and devoice LADDER. She's merged the two consonants so thoroughly in her phonology, that she has both as a single 'archiphoneme' that's always treated the same way in careful speech.
Jerry Friedman said,
July 28, 2010 @ 8:49 pm
@David Costa: I heard that occasionally from other kids in my teen and pre-teen days, thirty-some years ago. Or I think I did.
Dan S. said,
July 28, 2010 @ 9:56 pm
What program is used to make those graphs?
Keelan said,
July 28, 2010 @ 11:03 pm
@Dan S.: I made those graphs using some R functions I wrote intending to mimic the presentation style of Bill Labov's program Plotnik. If you're interested, the (undocumented) code is available here. An example data file (used to produce the plot for Walter K. in Figure 6.1 that Mark showed in the post) is available here.
After downloading the two files, the R commands that will reproduce Figure 6.1 are as follows:
> source('vowel.r')
> data plotVowels(data, c(5,53), zoom=T)
> plotMeans(data, c(5,53))
(5 and 53 are the Plotnik-style vowel codes used for the vowels /o/ and /oh/, respectively.)
Keelan said,
July 28, 2010 @ 11:07 pm
Sorry, my R code snippet got mangled. Trying again with HTML character references instead of brackets:
> source('vowel.r')
> data <- read.delim('walterKformants.txt')
> plotVowels(data, c(5,53), zoom=T)
> plotMeans(data, c(5,53))
john riemann soong said,
July 29, 2010 @ 9:37 am
Are there any (crude) algorithms used to "correct" for articulations before and after the vowel? (e.g. "unaspirated /k/ following /a/ tends to raise formant F1 of /a/ by x hz and F2 by y hz, etc.") If so, do they make the data "cleaner"?
[(myl) There's regression. You can't get much cruder than that.]
Rebecca said,
July 29, 2010 @ 1:35 pm
@Peter,
I think maybe you're missing a three-way distinction: there's [n] (motherfuckin'), [ŋ] (motherfucking), and [ŋg] ("hard g": motherfuckinguh). The "uh" is the release that you hear after the stop [g].
Wordoch said,
July 31, 2010 @ 7:32 am
That kind of "g-adding" in -ing is characteristic of Birmingham English as in /ˈbɝːmɪŋɡəm/.
exackerly said,
August 1, 2010 @ 12:17 am
That chart leaves out the upper class. What's that you say, there's no such thing in America? Well probably not, but there used to be one in England, and they dropped their g's with regularity. All that huntin' and fishin', you know…
Sili said,
August 1, 2010 @ 5:43 pm
I love these 'nerdy' posts.
xyzzyva said,
August 23, 2010 @ 3:27 pm
Not to be impatient, but is Part Deux forthcoming?