The texture of time: Even educated fleas do it
« previous post | next post »
[Attention conservation notice: this post wanders a bit too far into the psycholinguistic weeds for some readers, who may prefer to turn directly to our comics pages.]
In a recent paper, Ansgar D. Endressa and Marc D. Hauser document a puzzling result: Harvard undergraduates fail to recognize the regularities in "three-word sequences conforming to patterns readily learned even by honeybees, rats, and sleeping human neonates" ("Syntax-induced pattern deafness", PNAS, published online 11/17/2009).
Randy Gallistel is famous for his demonstration that rats sometimes seem smarter than Yale psychology students, but if worker bees and sleeping newborns really out-test Harvard undergrads, that would be a new low for Ivy-league intellect. In this case, however, it's not really true. The insects, rodents and infants would surely also fail in the form of the task inflicted on the Harvard students, who in turn would surely succeed if tested in the same way as the other animals cited.
Despite this disappointing come-back for eastern elitism, the experimental results are nevertheless interesting — although Endressa and Hauser offer an explanation that doesn't seem to me to go far enough. But first, let's rescue the honor of zip code 02138 by looking briefly at the perceptual successes of those bees, rats, and babies.
According to M Giurfa et al. ("The concepts of ‘sameness’ and ‘difference’ in an insect", Nature 410:930–933, 2001), honeybees can
… learn to solve 'delayed matching-to-sample' tasks, in which they are required to respond to a matching stimulus, and 'delayed non-matching-to-sample' tasks, in which they are required to respond to a different stimulus; they can also transfer the learned rules to new stimuli of the same or a different sensory modality. Thus, not only can bees learn specific objects and their physical parameters, but they can also master abstract inter-relationships, such as sameness and difference.
The set-up was a simple one:
Training was carried out using a Y-maze placed close to a laboratory window. Each bee entered the maze by flying through a hole in the middle of an entrance wall. At the entrance, the bee encountered the sample stimulus. The sample was one of two different stimuli, A or B, alternated in a pseudo-random sequence. The entrance led to a decision chamber, where the bee could choose one of two arms. Each arm carried either stimulus A or stimulus B as secondary stimulus. The bee was rewarded with sucrose solution only if it chose the stimulus that was identical to the sample.
After 60 training trials where the stimuli varied either in color or in (horizontal vs. vertical grating) pattern, the bees got to about 70% correct:
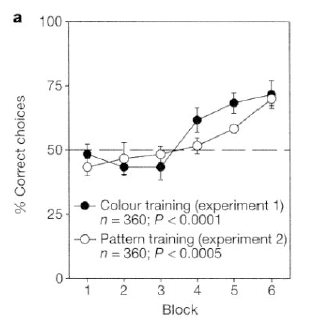
Bees who reached criterion on same-or-different color choice were able to generalize well to a test on same-or-different patterns, without further training; and similarly for bees trained on patterns and tested for generalization to colors. Although Giurfa et al. didn't check, I suspect that Harvard undergraduates could have done at least as well, as long as the apparatus was re-sized to fit them and they weren't required to fly in through the laboratory window.
Murphy et al. ("Rule learning by rats", Science 319:1849–1851, 2008) found that
Rattus norvegicus can learn simple rules and apply them to new situations. Rats learned that sequences of stimuli consistent with a rule (such as XYX) were different from other sequences (such as XXY or YXX). When novel stimuli were used to construct sequences that did or did not obey the previously learned rule, rats transferred their learning.
Their experiments worked as follows. Rats were trained with a pattern (either XYX, XXY, or XYY) made up of simple visual or auditory stimulus elements. For example, two tone bursts of different frequencies (e.g. A=3.2 kHz, B=9 kHz) would correspond to the XYX pattern either as ABA or BAB. If trained with XYX, therefore, the rats would get fed after hearing ABA or BAB, but not after hearing BBA, AAB, BAA, or ABB.
After acquisition, we presented them with transfer stimuli composed of two novel pure tones (C = 12.5 kHz and D = 17.5 kHz). The stimuli were counterbalanced so that the stimuli in the roles of A, B and C, D were reversed for half of the animals and were chosen to ensure that no common frequency relation was present between the pairs. If rats had simply learned something specific about the reinforced elements ABA, they should have been unable to choose CDC and DCD over CCD, DDC, CDD, and DCC. The amount of time that the rats kept their heads in the food trough during the final element of the sequence was used as a measure of learning. The results of the transfer test are presented in Fig. 1, excluding two rats that failed to learn the initial discrimination. More anticipatory behavior for food was exhibited during sequences that were consistent with the previously learned rule, even though the rats had never been presented with these particular instances and there was no food presented during the test.
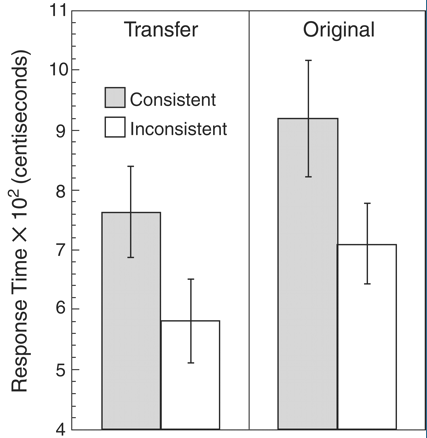
The article doesn't specify how many training trials were required to achieve this level of Pavlovian conditioning, but whatever the learning curve, I expect that Harvard undergrads could do at least as well, though some other rewards would probably need to be substituted for rat chow.
As for those newborn babies, Gervain et al. ("The neonate brain detects speech structure", PNAS 105:14222–14227, 2008) found that they didn't even require training. From the abstract:
[W]e investigated the ability of newborns to learn simple repetition-based structures in two optical brain-imaging experiments. In the first experiment, 22 neonates listened to syllable sequences containing immediate repetitions (ABB; e.g., “mubaba,” “penana”), intermixed with random control sequences (ABC; e.g., “mubage,” “penaku”). We found increased responses to the repetition sequences in the temporal and left frontal areas, indicating that the newborn brain differentiated the two patterns. The repetition sequences evoked greater activation than the random sequences during the first few trials, suggesting the presence of an automatic perceptual mechanism to detect repetitions. In addition, over the subsequent trials, activation increased further in response to the repetition sequences but not in response to the random sequences, indicating that recognition of the ABB pattern was enhanced by repeated exposure. In the second experiment, in which nonadjacent repetitions (ABA; e.g., “bamuba,” “napena”) were contrasted with the same random controls, no discrimination was observed. These findings suggest that newborns are sensitive to certain input configurations in the auditory domain, a perceptual ability that might facilitate later language development.
There's no reason to suppose that the pre-attentive ability to perceive adjacent repetitions is lost later in life, even in the Ivy League. (In fact, there's some experimental evidence bearing on this very question, about which more later.)
OK, now to what Endressa & Hauser's subject really did (or failed to do). The experimental paradigm was this:
[P]articipants were told that they would listen to three-word sequences (triplets) and were instructed to memorize them …. Then 40 example triplets were played, all conforming to the same repetition pattern. Half of the participants were familiarized with AAB sequences where the first two categories were identical, and half were familiarized with ABB sequences where the last two categories were identical. Following this familiarization, participants were informed that the triplets had conformed to a common structure. The participants were then presented with pairs of new triplets made of new words, one conforming to an AAB pattern and one to an ABB pattern. Participants were asked to indicate which of the two triplets was like the familiarization triplets.
When the A's and B's were members of two semantic classes — specifically animals and clothing, e.g. bear-hawk-coat or dog-swan-shirt vs. coat-skirt-swan or hat-blouse-hawk — the kids were alright. At least, they gave the correct answer 64.25% of the time. This was significantly better than chance, though perhaps not up to the standard one would hope for at Harvard.
But when the A's and B's were members of two syntactic classes — specifically nouns and verbs, e.g. camel-pliers-furnish or window-baby-scavenge vs. annoy-guitar-napkin or carry-water-brick — the correct answer was given only 53% of the time, not significantly better than chance.
In a separate experiments, E & H showed that their subjects were generally able to classify the words correctly as nouns or verbs when explicitly asked to do so. And when the subjects were primed with a part-of-speech classification task, and "were informed that they would listen to triplets that conformed to an extremely simple pattern involving nouns and verbs and were instructed to find the relevant pattern", performance improved to 67.5%. This is better than peformance on the semantic task, though again it would be an average of D without grade inflation.
And there was definitely a curve to grade against:
… the group performance was carried by five participants who performed at 100% correct; after removing these participants, the group performance did not differ significantly from chance [(M=56.7%, SD=13.5%), t (14)=1.92, P > 0.05]. Moreover, even when including the five successful participants, 60% of the participants reported that they had not noticed the repetition pattern—although they were explicitly informed about a pattern before starting the experiment.
I'd be inclined to take these results as more evidence (if more were needed) that most Americans today are singularly clueless about all aspects of linguistic analysis. (And I'd try to find out what school those five clueful participants went to…)
But it's not just Americans, apparently, and we can't even blame the effects entirely on the often-noticed fact that in English, any noun can be verbed (and vice versa). E & H replicated the experiment in Hungarian, where (in general) nouns are nouns and verbs are verbs and never the twain shall meet. Now the sequences become things like szamár-kules-tép or ablak-gyerek-visz vs. kever-hallgat-kendö or szeret-ellát-szamár, and the subjects were recruited from the Hungarian Academy of Science rather than the Harvard University Study Pool — and again the result was failure, at least on the group level [(M=56.8%, SD=16.5%), t (19)=1.83, P>0.05]. So I'm convinced that for most unprimed subjects, part-of-speech is not a salient feature in sequence-familiarization experiments of this type.
I promised to explain how Endressa & Hauser don't go far enough. In my opinion, there are two failures, a general one and a specific one.
First, it seems to me that this experiment (and many others like it) are really not about syntax learning at all. Rather, they're extensions, into the dimension of time, of the research pioneered by Bela Julesz on pre-attentive texture discrimination in static visual displays. See e.g. Bela Julesz, "Textons, the elements of texture perception, and their interactions", Nature 290: 91-97, 1981:
The study of pre-attentive (also called effortless or instantaneous) texture discrimination can serve as a model system with which to distinguish the role of local texture element detection from global (statistical) computation in visual perception. […] Without using the sophisticated techniques described in this article, it is not ovious, even in the case of pre-attentive texture discrimination, whether local differences between the texture elements directly contribute to discrimination or whether these differences are sensed in a global way only through differences in the statistics of the texture.
One of things that emerges from the earlier research that Endressa & Hauser cite (and much more that they didn't) is that repetition in time is probably a sort of temporal texton for most animals — that is, adjacent elements that are identical in terms of a salient feature form a local temporal pattern that "directly contribute(s) to pre-attentive texture discrimination", rather than constituting a "[difference] sensed in a global way only through differences in the statistics of the [temporal] texture". Endressa & Hauser come close to saying this, but they don't get there, and their bibliography fails to cite the texture-perception literature at all.
E & H show that (at least under the circumstances of their experiments) part-of-speech is not a feature whose repetition is tracked by human pre-attentive perception. This is interesting, but by no means a novel type of discovery. The texture-perception literature is full of contrasts among local features that "directly contribute" to texture discrimination, local features that contribute via their statistical distribution, and local features that are not accessible at all to pre-attentive texture discrimination. Here's one example of textural blindness from Julesz 1981, where local texture elements that are easily discriminated in isolation are ignored in texture perception:
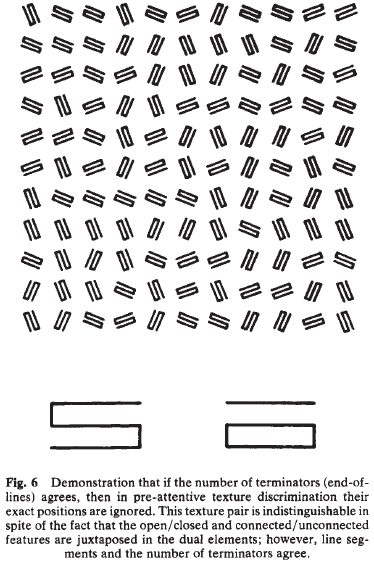
One of the aims of texture-perception research has been to figure out what sorts of statistics of what sorts of local features play a role in pre-attentive texture discrimination — and the main method has been to accumulate lists of things that work and things that don't, and then to test perceptual models against those lists — for a review, see Michael Landy and Norma Graham, "Visual Perception of Texture" (in Chalupa & Werner, Eds. The Visual Neurosciences, 2004).
In the so-far-mostly-nonexistent field of temporal texture perception, and more specifically with respect to human pre-attentive texture perception in sequences of spoken words, E & H, have contributed to the lists of "things that don't work (very well)" — unprimed sequences of syntactic categories — and of "things that (sort of) work" — sequences of semantic categories. They call this "syntax-induced pattern deafness", and they argue that the failure of their subjects to notice part-of-speech textures "give(s) credence to the proposal … that syntactic processes are just as modular and inpenetrable as other perceptual processes". A more tentative way to put this would be to note that unprimed part-of-speech is not a salient feature to the perceptual system(s) responsible for pre-attentive detection of temporal textures, and that the other properties of these systems are at present mostly unknown.
And here's the second way I think that Endressa and Hauser should have gone farther than they did. They should have explicitly (rather than implicitly) retracted the claims in an earlier paper by Fitch and Hauser, ("Computational Constraints on Syntactic Processing in a Nonhuman Primate", Science, Vol 303, Issue 5656, 377-380 , 16 January 2004), which used familiarization/discrimination experiments with patterns XYXY and XYXYX versus XXYY and XXXYYY to argue that cotton-top tamarins could master different finite-state but not context-free grammars.
From the perspective of the paper currently under discussion, this earlier work looks rather like evidence for an asymmetry in the relative salience (to the tamarins) of gaining vs. losing local repetitions, with no implications for grammar learning at all. (See here, here, and here for further discussion. For an earlier attempt to relate such so-called "grammar learning experiments" to the literature on texture discrimination, see "Rhyme schemes, texture discrimination and monkey syntax", 2/9/2006. And for a recent contribution to the literature on animal learning of sequential acoustic patterns, see Caroline van Heijningen, Jos de Visser, Willem Zuidema, and Carel ten Cate, "Simple rules can explain discrimination of putative recursive syntactic structure by a songbird species", PNAS, published online 11/16/2009. )
marie-lucie said,
November 24, 2009 @ 2:25 pm
Of course one would expect Harvard students to be given a more demanding test than bees and rats, but the test was not really of the form "identify the pattern ABB (or AAB)", such as colour patterns of green-green-red or blue-yellow-yellow, or word patterns of bird-bird-run or eat-wind-wind, where the repetitive pattern would have been obvious. The two nouns or the two verbs were never a repetition of each other (unlike the experiments with newborns, which focused on repeated syllables), they were often semantically incongruous with each other, as was the lone other part of speech, and even if the words were not themselves ambiguous as to what part of speech they were, the person being tested would have to determine the parts of speech, independently of the semantic properties which are what speakers are particularly attentive to, and in the total absence of a syntactic context within which parts of speech normally operate. The task then was not just to determine the parts of speech before stating the correct pairing, it first required abstracting both the sound and the meaning (the "texture" of the words?) of all three words in the sequence, but speakers are likely to attend to the meaning of a word before attending to its syntactic category (this is what young children do in the pre-grammatical stage of language acquisition, and asking an untrained person the meaning of a word also shows that many speakers' spontaneous definitions are often largely independent of the part of speech of the word to be defined). The phrase syntax-induced pattern deafness, used to explain the high failure rate of the test even among educated speakers, seems to suggest that people who have mastered even simple syntax (which would include most children over the age of 3 or 4) are no longer able to recognize parts of speech, something which suggests that they had mastered the task as even younger children (or that the recognition was innate and later "unlearned"). This paradoxical conclusion seems to me to show that the test was poorly designed and reflected incorrect assumptions about the nature, development and functioning of language.
[(myl) I'm afraid that you may have been misled by my feeble attempts to lighten up a somewhat ponderous discussion with a little post-human populist humor. The main point of the paper is precisely that most patterns of syntactic categories are not consciously salient, although these categories clearly play a role in speech production (e.g. the "syntactic category effect" in speech errors) and perception. This is a valid and interesting point, in my opinion, although I'm much less certain than the authors are about what it means.
It's not enough to say that people attend preferentially to meaning, since comparably abstract patterns of sound (e.g. rhyming or alliteration) would (I believe) be noticed at higher rates.]
Forrest said,
November 24, 2009 @ 2:44 pm
As for the poor Harvard students, I'm sure there's "a gene for not passing this test." More realistically, I'm sure there's more survival value in being able to distinguish between clothing ( and other artifacts ) and animals ( predators or prey ), than between part-of-speech categories. It seems pretty obvious why one of these would be more salient than the other. Has anyone tried asking them "mubaba" and "mubage?"
[(myl) The authors' mentions of "modularity", "encapsulation", and "impenetrability" are meant to index exactly the idea that syntactic categories are part of an innate language module whose internal features are not accessible to consciousness, unless they are arranged in a limited sort of "natural" pattern. In that sense, they are suggesting that all humans have "a gene for not passing this test", or at least a genetic bias in that direction.]
Levi Montgomery said,
November 24, 2009 @ 4:51 pm
"…were alright." Was that a joke?
[(myl) More of a classical allusion, really]
Rubrick said,
November 24, 2009 @ 5:57 pm
What I want to know is, if the auditory stimulus for the rats, instead of being ABA, were ABBA, would someone take a chance on them?
Less frivolously: the Harvard task reminds me of a common type of word puzzle in which the solver is given a list of words and must determine what feature all but one of them has in common. What makes these puzzles surprisingly difficult (and hence interesting) is the unexpectdly large number of attributes a word has, any one of which might be the key.
Take one of the Harvard examples given: "window-baby-scavenge". Here are some ways to partition these words:
Has ascenders: window, baby | scavenge
Has descenders: baby, scavenge | window
Is an English word when the first two letters are removed: baby, scavenge | window
Includes two consonants in a row: window, scavenge | baby
Begins and ends with different letters: baby, scavenge | window
With only three words given, there are many different ways to make any one of them the odd man out. For this reason, in puzzles there are generally at least six words given.
Of course, in the Harvard study the stimuli were auditory, but there still could have been a lot of red herrings— more, certainly, than in the pure-tone rat studies.
[(myl) It's worth noting that the subjects in Experiment 1 were not told to look for a pattern (of whatever kind), but rather just to memorize the words in the list. Presumably in this case, they simply didn't find the syntactic categories salient enough to pay attention to. But in Experiment 2, when they were first drilled on noun/verb distinctions with individual words, and then specifically told to look for a pattern of syntactic categories, 5 out of 20 subjects performed perfectly, while the other 15 responded randomly. Something odd was going on there, it seems to me. I'm inclined to wonder about what we used to call the "paper airplane effect", after an occasion where someone monitoring a group of subjects in an especially boring experiment noticed that they were making and flying paper airplanes while supposedly listening to our stimuli.]
D.O. said,
November 24, 2009 @ 7:19 pm
I have a comment only tangentially related to the post. I fail to recognize any pattern in the coloring of quotations. For me the red is somewhat annoying (I mean, the color is annoying, not quotes). And I really liked this
It's simple, but nice.
marie-lucie said,
November 24, 2009 @ 7:34 pm
myl, thank you for replying to my comment. I don't think I totally missed your humour, since I thought your post was one of the funniest ones I had ever read and I laughed aloud a number of times while reading it. But I wondered what the experimenters meant by "syntax-induced pattern deafness", since there was nothing in the experimental data that suggested a pattern, except for the difference in parts of speech: without syntactic clues, there were no morphological or phonological "patterns" which could have pointed to the "right" conclusion. (I missed the point that the words were heard not read, so I agree with you that phonological patterns would probably have been noticed, if there had been any, which did not seem to be the case).
D.O. said,
November 25, 2009 @ 2:55 am
The researches had to get Harvard students some incentives to answer the questions correctly. The students are no stupider than bees and rats. On a more serious note, it is interesting that in the second experiment students separated into "get it" and "don't get it" categories without significant fraction of "have some idea".
Rubrick said,
November 25, 2009 @ 3:58 pm
I think D.O.'s first point is a good one, humorous or not. I wouldn't be surprised if the number of subjects getting the "right" answers increased markedly if they knew they were receiving, say, $50 for each correctly-categorized triplet. There's a big difference between pretending to try your hardest and actually trying your hardest.
(Hm, this was Harvard. Better make it $100.)
Ansgar Endress said,
November 28, 2009 @ 9:48 pm
As usual on this blog, reading the actual paper before posting about it seems a no-no. (Supplementary information is useful too, that's why it's published.) If you had read the paper, you would have seen that it's simply not the case that people don't "perceive" the syntactic categories in the context of the sequences. Therefore, people do access the categories in sequences, they perceive repetition-patterns with other (linguistic or non-linguistic) categories, they do not seem to suffer from other confounds we controlled for, and yet they cannot perceive repetition-patterns with nouns and verbs. The entire pattern of result is not really consistent with the stuff Mark L. puts forward.
Regarding the question of whether what the bees/rats/neonates can do is comparable to what our participants cannot do (in some circumstances), we would have thought that Marr's level of analysis would be known even on this blog. On the computational level, all these species can perceive repetition-patterns/identity relations, and it's just this kind of pattern that our participants fail to perceive when using syntactic-categories. But it’s just a blog after all…