Gun phrases
« previous post | next post »
 In response to yesterday's tragedy, Nate Silver takes an interesting look at changes over recent years in the frequency of certain gun-related phrases in the news ("In Public ‘Conversation’ on Guns, a Rhetorical Shift", NYT 12/14/2012):
In response to yesterday's tragedy, Nate Silver takes an interesting look at changes over recent years in the frequency of certain gun-related phrases in the news ("In Public ‘Conversation’ on Guns, a Rhetorical Shift", NYT 12/14/2012):
Friday’s mass shooting at an elementary school in Newtown, Conn., has already touched off a heated political debate. Opponents of stricter regulation on gun ownership have accused their adversaries of politicizing a tragedy. Advocates of more sweeping gun control measures have argued that the Connecticut shootings are a demonstration that laxer gun laws can have dire consequences. Let me sidestep the debate to pose a different question: How often are Americans talking about public policy toward guns? And what language are they using to frame their arguments?
He took the data from NewsLibrary.com's search facility, whose popularity will no doubt get a boost. But as far as I can tell, he had to run 33 date-limited searches for each of the four phrases in his graph, and then transcribe the count given in the results page, e.g. in order to learn that there were 9172 mentions of "gun control" between 1/1/1995 and 12/30/1995. I'm not sure how he got the total number of news articles that year, in order to calculate the number of mentions per 1000 articles. Maybe he did 33 more date-limited searches for a common word like "the", which NewsLibrary tells me occurred 4,902,412 times in 1995. That would yield 1000*9172/4902412 = 1.870916 mentions per thousand articles, which would fit with his un-averaged graph:
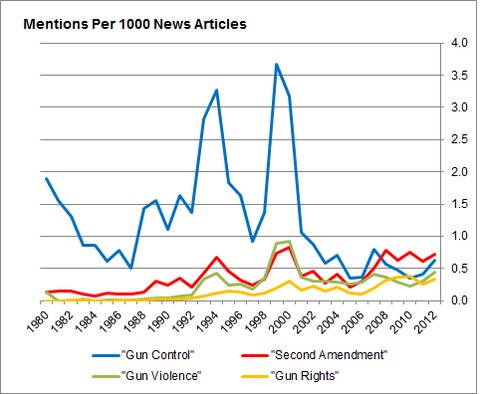
Of course, Mr. Silver might have had an intern do the searches… Or maybe he wrote a bot — an automated intern — to run the searches for him. Or again, maybe NewsLibrary has given him special access to an API.
In any case, NewsLibrary ought to consider offering a service like that of the Google Ngram Viewer, or Mark Davies' COHA interface, which would automate such culturomical researches. It would take some semi-clever hacking (and probably some additional server capacity) to give good performance on the needed scale, but it ought to be possible to derive added revenue to cover the costs. I'd certainly urge Penn's library to sign up for such a service, or pay for it myself if the charges were reasonable.
Ben Zimmer said,
December 15, 2012 @ 7:50 am
Silver described normalizing NewsLibrary results in a post last year about media coverage of Irene and other hurricanes:
[(myl) Interesting. But again, he doesn't say how he gets the "average nmber of stories per day that were available to the NewsLibrary.com database during that period." My method — count the stories containing a ubiquitous word like "the" — would work here as well, but maybe he has access to the data in a more direct way.
(If the NewsLibrary interface offers a more direct form of the information to the public, I missed it.)]
Jayarava said,
December 15, 2012 @ 10:05 am
Ngram tells quite a similar story. Though in my experience ngram almost always falls off after 2000.
Ben Zimmer said,
December 15, 2012 @ 12:22 pm
Jayarava: As the culturomics site notes, "the best data is the data for English between 1800 and 2000… after 2000, the corpus composition undergoes subtle changes around the time of the inception of the Google Books project." This is in large part because the post-2000 holdings skew more toward books provided by publishers, which leads to various kinds of under- and over-representation in relative corpus frequencies.
Drei Bemerkungen zu Waffengesetzen in den USA « USA Erklärt said,
December 15, 2012 @ 12:31 pm
[…] Weiter gibt es Hinweise, dass eine Polarisierung in der öffentlichen Debatte stattfindet: Die "New York Times" berichtet heute, dass in den US-Medien neutralere Begriffe wie gun control zunehmend durch Begriffe wie gun violence und gun rights ersetzt werden. Im Language Log werden diese Ergebnisse kommentiert. […]
Por qué no habrá un cambio radical en las leyes de tenencia de armas en USA | Desde el exilio said,
December 19, 2012 @ 3:57 am
[…] o "derecho a las armas". interesantísimo el pequeño estudio que ha realizado "Language Log" al respecto y del que les dejo una […]
Similarly, The Rate Cannot Be Blamed On Poverty Levels, Which Are Not Higher Than Other Industrialized Nations. | Dziewonski Town said,
September 8, 2013 @ 11:47 pm
[…] or possibly killing whoever was near it at the time. – Or would you still prefer a gun and special forces wait for threat of invasion are spurious, to say the least, given the power of the US military. […]