Pharyngula minutes
« previous post | next post »
A graph of the current Google hit counts for "N minutes", 2 ≤ N ≤ 66, expressed as a proportion of the total hits for all 65 searches, looks like this:
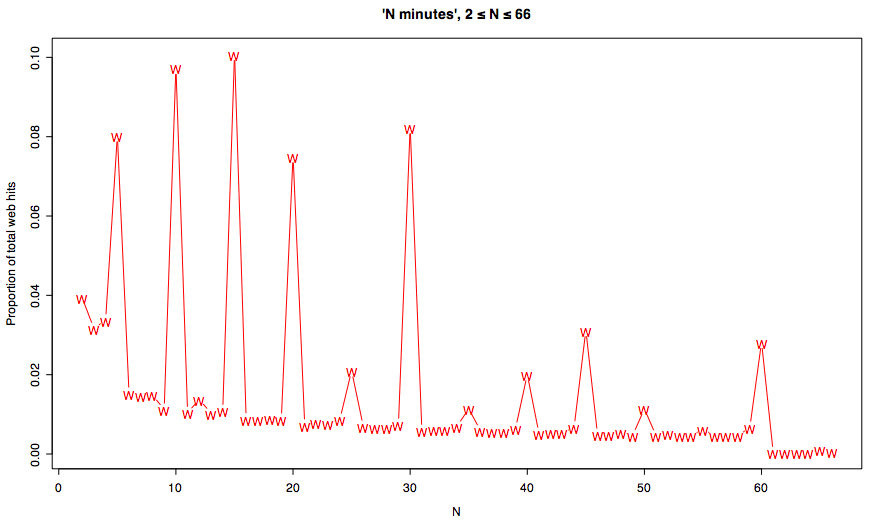
(As usual, click on the image for a larger version.)
There seem to be several different things going on here: a preference for multiples of 5, 10, and 15; a preference for smaller numbers; and perhaps some other factors as well.
You could model this sort of distribution with the kind of approach that Tenenbaum and Griffiths used to predict how people generalize from (small) sets of numbers ("Generalization, similarity, and Bayesian inference", Behavioral and Brain Sciences, 24: 629-641, 2001). In fact, for exploring the structure of certain kinds of cognitive/cultural spaces, web-text counts might be better than lab-subject responses, since web text samples are certainly larger and arguably more representative. (There are plenty of obstacles — certainly Google counts are not really reliable enough for this purpose — but never mind for now…)
Distributional patterns of this kind can also be used to explore cognitive and cultural differences. For example, if we compare the overall web frequency of N = 5, 10, 15, …, 65 in "N minutes" with the relative frequency of N in the Google search patterns {X "N minutes or less"} for X = "recipe", "learn", and "muscles", we get this:

The distribution for N in {learn "N minutes or less"} (e.g. "Tech savvy in 15 minutes or less") and {muscles "N minutes or less"} (e.g. "instant fitness workout in 15 minutes or less") follow the general web distribution for {"N minutes"} (the yellow line) pretty closely, except for a bit of enrichment at N=30 (and maybe a slight muscle bulge at N=20). But {recipe "N minutes or less"} is more different from the background: the counts for N=5 and N=10 are quite a bit lower, while N=30 is much higher.
The dearth of recipes at N=5 and N=10, I speculate, reflects a victory of realism over marketing: readers really will try out recipes, and notice if they take a lot more time than advertised. And the recipe sweet spot at N=30 probably reflects the fact that 30 minutes is the largest quantum of time that most people still generally view as small.
But anyhow, it's not because of recipe marketing that I decided to devote this morning's Breakfast Experiment™ to the contextual distribution of N in "N minutes" — instead, you can blame it on PZ Myers. Reading the Pharyngula archives a few days ago, it seemed to me that Prof. Myers (and his commenters) used a few values of "N minutes" — especially N=5 and N=10 — unusually often and in a somewhat characteristic way.
Now, I've pointed out in the past that the verbal tics that we perceive as "characteristic" of particular people are often very low-frequency events (see e.g. "And yet", 3/28/2004; "Per usual", 6/21/2004; "Strange bookfellows", 5/26/2005; "Deep in the Hookergate weeds", 5/8/2006; "Cold comfort for whomever", 10/26/2007). On the other hand, we've also seen that subjective estimates of relative frequency can be way off the mark, quantitatively ("What 'a hundred times' means", 10/2/2004) and even qualitatively ("Near? Not even close", 1/2/2005).
In this case, a quick check suggests that my subjective reaction fell into the "complete crock" category:
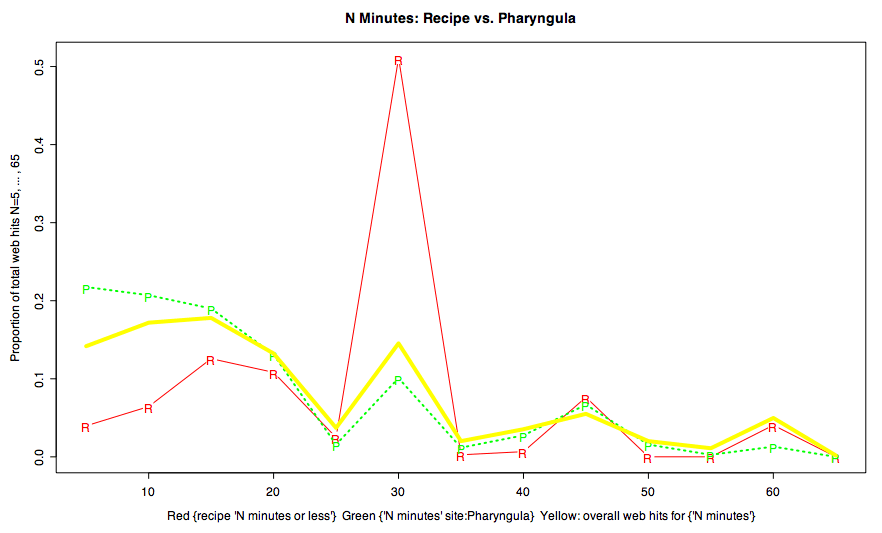
Overall, Pharyngula's distribution of values for N in "N minutes" seems to be reasonably close to the overall web norm — certainly closer than the distribution of N for recipes executable in "N minutes or less" is. There's a small pharyngular excess at N=5 and N=10, and a small deficit at N=30, but the differences don't seem very impressive.
But wait — if we plot the data a little differently, the differences look bigger, and it seems more plausible that I might have been picking up on something real:
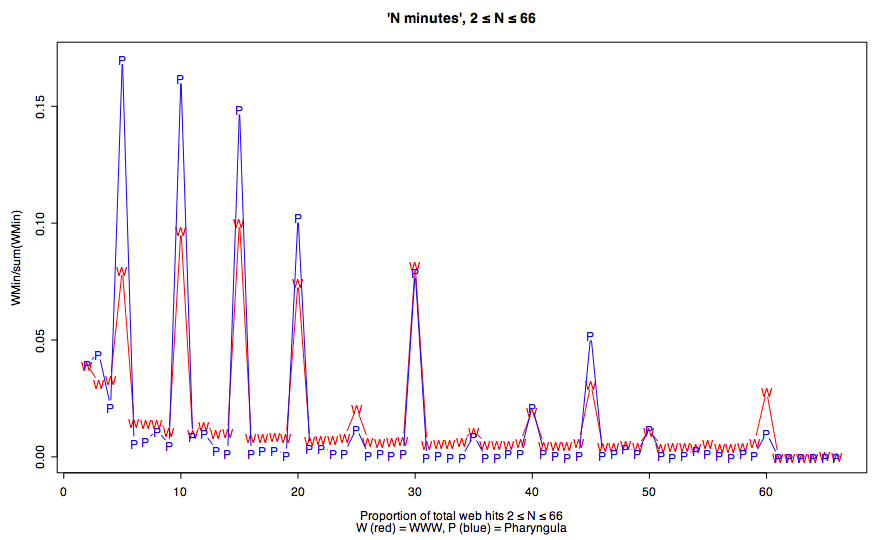
OK, looking at graphs is all very well, but what's the Right Way to evaluate a hypothesis like "text at scienceblogs.com/pharyngula has a different distribution of values for N in 'N minutes' than the web at large does"? (I mean, besides saying "who cares?" and moving on.) This is trickier than you might think, especially if at this point you're trying to remember how to perform a Kolmogorov-Smirnov two sample test, because it's not easy to be precise enough about what question(s) we really want to answer.
But I've already run out of breakfast time for today — in fact, I had to finish this write-up over lunch — so my (attempt to provide an) answer will have to wait for another morning.
[Update: PZ Myers attempts that characteristic artefact of the internet age, an overt attempt to elicit the Observer's Paradox ("It's 42 minutes after 7", 8/2/2008). But it's too late, PZ, unless you go back and edit your copious archives! And really, it could be worse: consider the sad fate of Ronald Frobisher.]
Bob O'H said,
August 1, 2008 @ 3:24 pm
Some thoughts (before the Pharynguloids get here):
1. You have count data, so from a technical point of view, a chi-squared test or a log-linear model would be more appropriate.
2. You need to be clear about the hypothesis you are testing. From that, all else follows.
3. What is the population you are comparing Pharyngula to? All of the web? Just blogs? Blogs by radical atheists with an irrational contempt for wafers?
4. You're almost certainly using the same data you used to generate the hypothesis as you are to test it. That is naughty, and of curse you're more likely to see the pattern you thought was there. You can use the data you have to refine your hypothesis, and then test it with new data (in the future). Of course, you just know what will happen if someone over there realises what you're doing.
5. Why 66 as the upper bound? Why not, say, 69?
rootlesscosmo said,
August 1, 2008 @ 3:57 pm
"30 Minute Meals" is a very popular show on the Food Network; might this skew the results?
Isabel Lugo said,
August 1, 2008 @ 4:00 pm
It's interesting to see that 45 is higher than 40 or 50, and 15 is higher than 10 or 20; it illustrates that people are really thinking in terms of quarters of an hour. (There's an interesting question — why do we seem to do things in terms of quarters of an hour, instead of thirds or sixths? For example, I'm much more likely to make an appointment with somebody for 4:15 than for 4:10 or 4:20.)
Milt Boyd said,
August 1, 2008 @ 5:22 pm
In many fields, it is relatively easy to find halves, and halves again, and so on. The Imperial system of units is filled with 2:1 ratios, for lengths, weights, volumes. It's often rather difficult to find one-third, and more difficult to check that you got it right. Hence a bias for quarters and such.
Isabel Lugo said,
August 1, 2008 @ 5:55 pm
That's a good point. I suppose the reason we stop at quarter-hours, instead of using an eighth of an hour, is because that's not a whole number of minutes. It seems like the next finer clump of time we tend to use, after 15 minutes, is 5 minutes; of course that's half of 10, which is the base of our numerical system.
People have suggested dividing the hour into 100 minutes, as a sort of "metric time". Has anybody seriously suggested 64?
Jonny Rain said,
August 1, 2008 @ 7:47 pm
"What is the population you are comparing Pharyngula to? All of the web? Just blogs?"
I don't know why, but you could do the same analysis but limited to searching blogs:
http://blogsearch.google.com/?hl=en&tab=wb
Jim Fowler said,
August 1, 2008 @ 9:36 pm
Aside from comparing distributions, the distribution of Google hit counts for integers (without any accompanying text) is pretty cool. Here is a graph of Google hit counts for "N" where N is a number between 1 and 500. A regression on this data suggests a power law at work.
For a fun party trick, you can try the following: there are 345 million hits for "241", and just about half as many (172 million) hits for "482," a number twice as big. Generally, doubling a number halves the number of hits.
Maybe this says more about random numbers than about people…
Jonathan Lubin said,
August 2, 2008 @ 9:10 am
To an old fogy like me, wearing one of those funny round analog devices strapped around his wrist, counting time in multiples of five is perfectly natural: the hour is conveniently divided for you into those twelve blocks, after all. It’s only someone using a digital clock who would have even asked this question.
Brian Macker said,
August 2, 2008 @ 10:01 am
This is pretty much useless without knowing quantity of text. It might be that the proportion of usage to text is much higher on one source vs. another and that may cause differences in small and large number effects. Was quantity of text taken into account? Perhaps Myers and company uses "n minutes" far less than anyone else.
craig said,
August 2, 2008 @ 11:02 am
How often do Pharynguloids use the word "cracker" compared to the rest of the web?
Sven said,
August 2, 2008 @ 11:07 am
Just a thought: I suspect that there'd be a "sports writing about soccer" shaped blip at 90 minutes….
BaldApe said,
August 2, 2008 @ 11:34 am
I'm not sure if the marketing idea pans out. (the idea that it is unrealistic to think that you could master Urdu in 5 minutes, for instance) People just don't pay much attention.
Look at a prepackaged food item which requires preparation (like mac and cheese, for instance) Commonly, you will see the words "Simple one step directions" on the front of the box, then when you turn it over you see Step 1, Step 2, Step 3….
mgh said,
August 3, 2008 @ 6:31 pm
the first page of google movie listings in my neighborhood gives the following distributions of minutes-after-the-hour movie start times:
00 214
05 34
10 66
15 71
20 54
25 18
30 78
35 19
40 39
45 54
50 43
55 13
the suppression of 55, 35, and 25 probably reflects shifting those values onto 00 and 30. no idea why this effect isn't seen as much for 05.
Sili said,
August 4, 2008 @ 3:27 pm
Wait – you read the archives of Pharyngula in a coupla days? I'm still trying to catch up after 36 hours offline. My envy knows no bounds! In fact I shall comfort-snack furiously for 27 minutes in order to calm down.
Hmmm – We need to get you an invitation to the next Amaz!ng Meeting. There are rumours of photographs of PeeZed and Ben Goldacre together. Throw in Liberman and we'll have reached the blogularity!
PS: the proper term is "Pharyngulistas".
Jack Picknell said,
November 4, 2008 @ 3:34 pm
Check out the word "Catholics" from Pharyngula. He is an obsessed anti-Catholic bigot.
Bookmarks about Bayesian said,
January 12, 2009 @ 9:44 am
[…] – bookmarked by 1 members originally found by lowf on 2008-12-16 Pharyngula minutes http://languagelog.ldc.upenn.edu/nll/?p=429 – bookmarked by 3 members originally found by hfishel […]