Word-order "universals" are lineage-specific?
« previous post | next post »
This post is the promised short discussion of Michael Dunn, Simon J. Greenhill, Stephen C. Levinson & Russell D. Gray, "Evolved structure of language shows lineage-specific trends in word-order universals", Nature, published online 4/13/2011. [Update: free downloadable copies are available here.] As I noted earlier, I recommend the clear and accessible explanation that Simon Greenhill and Russell Gray have put on the Austronesian Database website in Auckland — in fact, if you haven't read that explanation, you should go do so now, because I'm not going to recapitulate what they did and their reasons for doing it, beyond quoting the conclusion:
These family-specific linkages suggest that language structure is not set by innate features of the cognitive language parser (as suggested by the generativists), or by some over-riding concern to "harmonize" word-order (as suggested by the statistical universalists). Instead language structure evolves by exploring alternative ways to construct coherent language systems. Languages are instead the product of cultural evolution, canalized by the systems that have evolved during diversification, so that future states lie in an evolutionary landscape with channels and basins of attraction that are specific to linguistic lineages.
And I should start by saying that I'm neither a syntactician nor a typologist. The charitable way to interpret this is that I don't start with any strong prejudices on the subject of syntactic typology. From this unbiased perspective, it seems to me that this paper adds a good idea that has been missing from most traditional work in syntactic typology, but at the same time, it misses two good ideas that have been extensively developed in the related area of historical syntax.
This paper's good new(-ish) idea is that new languages develop by an evolutionary process from older ones, and therefore the explanation for the current distribution of "states" (here viewed as distributions of eight superficial word-order generalizations) may lie (mainly or entirely) in the "transition probabilities" that characterize the process of change, rather than in a set of constraints on a static view of the state space.
The paper's main result starts with a demonstration — which I find convincing — that these transition probabilities cannot be factored into entirely independent contributions of the eight individual features, but rather have at least two-way interactions, in which the probability of (say) evolving from postpositions to prepositions is different in a language with verb-object order than in a language with object-verb order.
This much is predicted by all extant theories, including those that this paper's authors call "generative" and those that they call "statistical". Even if you believe that the only explanatorily-relevant forces arise from static constraints on synchronic grammars, you'll expect these constraints to drive state-dependent probabilities of change, especially when the states are described in superficial ways. Thus if you believed that languages prefer consistency in the position of grammatical "heads", you would conclude that changes increasing such consistency (e.g. arranging for both verbs and adpositions to precede their objects) should be favored, other things equal, over changes that decrease it.
But this paper's focus on the distribution of state-transitions rather than on the distribution of states, along with its method for quantitative estimation of the transition probabilities, leads the authors to a second result, namely that the correlations among estimated transition probabilities for the eight individual features are different in the four different language families that they studied. On the face of it, this seems to be inconsistent with any theory where the relevant forces — whatever their explanation — are universal.
I'm convinced that this result is interesting, but I'm less certain that it's true. My first concern is that the paper is modeling an implicit transition matrix with 65,536 cells: there are 2^8 = 256 possible configurations of the 8 superficial syntactic features, and therefore 256*256 = 65,536 transition probabilities between language-states. The empirical basis for their effort is large in terms of the effort involved in creating it — evolutionary trees estimated from 589 languages in 4 families (400 Austronesian, 73 Bantu, 82 Indo-European, and 34 Uto-Aztecan) — but small relative to the number of parameters implicit in this problem. They solve this difficulty by transforming the 65,536-dimensional problem into a much lower-dimensional one — the relevant numbers are the 8*8 = 64 pairwise correlations among the 8 superficial syntactic features.
But their conclusion still depends on being able to estimate these 64 correlations separately for each of the 4 lineages. And prior to exploring the methodological background carefully, it's not obviously to me that this can be done accurately-enough for the phylogenetic analysis of 34 nodes (Uto-Aztecan) or 73 nodes (Bantu) or 82 nodes (Indo-European). [The BayesTraits software that they used uses Markov Chain Monte Carlo simulations in a credible way to estimate the relevant correlations and confidence intervals — but the relationship between the number of parameters and the amount of data still worries me.]
And even if the lineage-wise correlation estimates are entirely correct, there might still be some structure hidden in the 65,536 – 64 = 65,472 ignored dimensions that would motivate an explanation in terms of constraints on synchronic grammars after all. All the same, it's a challenge to synchronic-constraint theories that the correlations in different lineages look so different; and the authors of this paper deserves kudos, not just for the amount of work involved in the analysis, but also for posing the question in this form in the first place.
As for my claim that there are two good ideas from work in historical syntax that are missing from this paper, I don't have time this morning to give more than a brief sketch of what I mean. I'll come back with more detail some other time.
The first point is easy to understand: historical change in syntactic structures, as in all other aspects of language, is often driven by language contact. In the abstract, this is an old and obvious idea, but there are many specific relevant facts and generalizations, some of them recently discovered or elaborated. For a survey, see Sally Thomason's Language Contact: An Introduction.
One reason for bringing this up is that contact between languages is entirely outside the range of models considered by Dunn et al. But if language contact has played an important role — and some people think that it plays a dominant role in syntactic change — then it's likely to create real lineage-specific correlations of the type that Dunn et al. observe, since their linguistic lineages are almost entirely geographically disjoint, and thus subject to disjoint areal phenomena caused by disjoint patterns of contact. I don't see any reason that these areal phenomena should not include correlations among the estimated transition probabilities for their eight superficial syntactic features.
And note that in this sense (and some other senses as well), historical linguists have always understood that language change is driven by forces outside of preference-relations (whether statistical or categorical) among synchronic grammars. The Dunn et al. paper gives the impression that all prior theories of syntactic typology have missed this point. But in fact, a failure to attend to "path effects" and historico-cultural influences has been the exception rather than the rule among linguists. Indeed most linguists have in fact been attentive to some grammar-external effects, such as language contact, that Dunn et al. ignore.
The second missing idea from work in historical syntax is that features like "OBV" (the code for whether objects follow verbs) should be seen as superficial grammatical symptoms rather than atomic grammatical traits. To give a biological analogy, having a determinate genomic variation (like the HbS mutation behind sickle-cell anemia) is a trait whose distribution it makes sense to model using techniques like those used by the BayesTrait software. But having a phenotypic property like being short is much more problematic. Height (though quite heritable) is a complex interaction among many genes and environmental influences. And if your sample includes short people from groups with several quite different reasons for being short, but your model treats shortness as an atomic trait, then your estimates of trait-transition probabilities are likely to be garbage, at least with respect to the underlying science.
If you don't know what this might mean in a syntactic context, and you can't wait for my promised forthcoming discussion, take a look at Anthony Kroch, Ann Taylor, and Donald Ringe, "The Middle English verb-second constraint: a case study in language contact and language change", in Susan Herring, Ed., Textual parameters in older languages, 2000.
[Amazingly enough, there's another interesting new paper out of Auckland on linguistic evolution this week: Quentin Atkinson, "Phonemic Diversity Supports a Serial Founder Effect Model of Language Expansion from Africa", Science 4/15/2011. More on this later…]
Tadeusz said,
April 15, 2011 @ 7:59 am
Unfortunately, I cannot read the Science version, as I do not subscribe to it, I read a summary in the New Scientist (UK).
Oh my God, what nonsense the NS editor managed to put into the text… confusion of characters with sounds was not the least of them.
Simon Greenhill said,
April 15, 2011 @ 8:04 am
Hi Mark, and thanks for the nice review. Always good to get discussion going on LanguageLog. A few quick responses, if I may?
1. Thanks for linking to the overview – that took me about a day to write, so I hope very much that people find it useful.
2. Regarding the borrowing of structural features: We're very aware that this occurs (hey, I even have a paper where I argue that it's one of the dominant processes in language prehistory).
In hindsight it would have been good to have discussed this issue in a bit more detail in the paper. So what does borrowing of structures do to the results? if there is a functional dependency then the two features should be borrowed together. If they're functionally independent then they should be borrowed independently. In fact – these two cases are great evidence of functional relationships (or the lack of). These situations should be handled correctly by the analyses.
3. Regarding the amount of data required to identify the correlations – this is, naturally, an issue. However, the correlations we have reported are exceptionally strong (at least five times more likely to be linked then not) and reasonably robust – so it would be rather unusual to have missed some. This paper is, of course, not intended as the last word on the topic, but was us trying out a new approach and showing a a new way of conceptualising these issues. Extending this study with more data and more comparisons will be great fun.
4. The final point about the superficial vs atomic features is an interesting one. However, these features were identified as atomic by other people than us and we just tested them. In addition this method is often successfully used on continuous data that is often polygeneic in biology (say, body size, or length of bird beaks etc). The important question in biology here is where is natural selection operating – the many genes operating on body size are only acted on indirectly filtered through the phenotypic combination of everything in that organism. I would assume this is the same for linguistics – the important question here is what is relevant to the speakers?
Simon
Cy said,
April 15, 2011 @ 8:06 am
So they've defined path dependency, but as you note, they haven't taken substrate effects into the calculation. The problem you give as an example, namely, that not only can 'OBV,' for example, be a phenotypical symptom, but also, given the finite variations in real language, long-branch attraction would seem to further complicate these kinds of language-family study: two unrelated OBV languages, even in the same family, didn't necessarily get that trait from a common ancestor. All of which is saying, of course, that more linguists need more statistics and computer science if we're going to start using graph theory and network models to advance the field. Seems like a good start though.
Simon Greenhill said,
April 15, 2011 @ 8:17 am
In response to Cy – Long branch attraction is definitely not happening in these data. We built the trees from different sources of data and then mapped the features on to them.
–Simon
Cy said,
April 15, 2011 @ 1:05 pm
Hi Simon
Regarding your point number 4: – I'm sure you have a well-reasoned basis for this, but however much language evolution mirrors biological evolution, there's still the difference between language change in linguistics and differential reproductive success in organisms. A lot of the methods seem to produce usable results, but they are still different processes – a daughter language isn't a daughter, and creoles aren't like sexual reproduction.
As for features – linguistics has a lot of problems in this area – they're often misidentified as 'atomic' (or distinctive or other nomenclature), and they simply aren't. Descriptions of languages are full of these issues, see the recent Piraha debate for a real disturbing example. Little things like that can really mess up your results, even if your model is theoretically, functionally perfect.
For example, take tone: someone without specific experience in tonal languages could conclude from a survey or from SIL or somewhere that there are register tones, and contour tones, and count that as two features. But the reality is that there is both contour as well as tone+phonation. Without this distinction, connections can be made that aren't there. Relying on others in linguistics can garble your data.
Jerry Friedman said,
April 15, 2011 @ 4:49 pm
I must be missing something basic, because the trees in the pdf of the paper (thanks to whoever put that on line!) look like spectacular corroboration of Dryer's hypothesis that adposition order and verb-object order are correlated. They also show the interesting phenomenon that the degree of correlation varies among language families. But I can't see how they're "contrary to the Greenbergian generalizations" for this particular pair of features. Would things look very different if the paper had shown trees with other pairs of features?
John Lawler said,
April 15, 2011 @ 7:08 pm
Both of the papers Mark refers to (Dunn et al in Nature, Atkinson in Science) are discussed in the latest Economist, referenced by a post in its Johnson blog.
Tunji C. said,
April 15, 2011 @ 8:12 pm
The article and the publicity around it also takes up the ever-popular "Chomsky sucks" theme, and hits that note quite shamelessly. I dont' think there is anything to this at all, and the reason is exactly your "second missing idea". Excellent post!
[(myl) In this particular case, the argument is muddied by the fact that the parameter-setting theories of C and his followers did not make categorical predictions about the distribution of observable constituent orders (though particular versions of these ideas did imply markedness relations implying that some orders were more natural and therefore more likely to develop than others); and the argument is further muddied by the fact that the term "parameter" itself belongs to an earlier iteration of C's ideas, which he has since repudiated. (Dunn et al. cite Lectures on Government and Binding (Foris, 1981).)
I should add that the "popular 'Chomsky sucks' theme" was discussed at some length in an earlier LL post, "Universal Grammar haters", 7/31/2010 (though I think that the reasons for the straw Chomsky in the Dunn et al. paper are bit different). ]
Olaf Koeneman said,
April 16, 2011 @ 4:24 am
I personally do not know a generative linguist who believes that we need a universal rule to constrain (or steer) harmonization of headedness, let alone a generative linguist who thinks that such a constraint should be part of an innate language capacity. It could be that I am just blessed but it could also be that these authors are trying to slaughter a strawman.
[(myl) But a Google Scholar search for {headedness parameter} yields thousands of hits. Most of the examples on the first couple of pages involve theories that see universal grammar as "constraining" or "steering" the linear order of heads and their dependents, e.g. variants of Kayne's "antisymmetry" theory among others. So perhaps you have a somewhat narrow circle of acquaintances, or they have somewhat short memories.]
Pavel Iosad said,
April 16, 2011 @ 5:53 am
A genuine question: how (if at all) can the results be affected by the selection of source material? In Figure 1, we see that, for example, Dutch, Flemish, Standard German, Pennsylvania Dutch and Luxembourgish are all separate nodes, whereas languages like Armenian or Albanian are represented as single entities, despite their internal diversity. Might that have created an effect artificially reinforcing those correlations supported by many nodes?
[(myl) This looks like a significant issue to me, but I'm not expert enough in the particulars of the BayesTraits software to be sure. I'll ask the authors of the paper.]
Olaf Koeneman said,
April 16, 2011 @ 6:19 am
Good point. And to make it worse, Dutch, Flemish, Standard German, Pennsylvania Dutch and Luxembourgish are all taken to be VO languages, just like English, showing that Dunn et al. make the classical Greenbergian mistake: "Only look at main clauses". It is clear that the VO order in Dutch and German is a derived word order and that they are underlyingly OV. If headedness is taken so surfacy, so "let's ignore anything insightful that generative linguistics has discovered on this point", then I am not inclined to look upon this paper as a linguistic one.
Tunji C. said,
April 16, 2011 @ 7:58 am
myl writes, replying to Koeneman: "But a Google Scholar search for {headedness parameter} yields thousands of hits. Most of the examples on the first couple of pages involve theories that see universal grammar as "constraining" or "steering" the linear order of heads and their dependents"
Yes, myl is right that a "headedness parameter" has been proposed, but always (when proposed intelligently) in the context made clear by most of these Google hits for "headedness parameter" — for example the third one, which includes the remark:
"However, the workings of one parameter may be obscured by the workings of another parameter (or other parameters), thus creating an illusion of exceptions to the clear-cut picture of language"variation."
That's why the present study isn't a Chomsky-killer and couldn't possibly be one.
[(myl) It's certainly true that the wide scope for interaction among parameters in such theories means that they predicted little or nothing about observable word orders, at least in categorical terms. But in typical instantiations of such theories, there were default settings, creating a scale or structure of relative markedness, which in principle would have generated predictions about the relative frequency of observable orders. However, I use the past tense, because (in my limited understanding) this whole line of inquiry has been ended among the orthodox, since C's current grammatical ontology does not include notions such as "head" or "parameter" as basic concepts, and thus no longer has any way even to formulate the issues.]
There are no parameter shifts that make predictions of the form "if the order of words X and Y changes, the order of words A and B also changes". It's never ever that simple,. I doubt any serious Chomskyan work on word order ever assumed that it is. In every language we know there are many factors that contribute to the relative ordering of any pair of words, and the whole interest of studying universals of word ordering for most of these linguists lies in the untangling of these complexities. Google "universal 20 Cinque", for example. Or "Final over final constraint".
So as far as generative grammar, parameters, Chomsky, etc. is concerned, this study shows nothing relevant at all.
By the way, the article ends with a proclamation that it's now been shown that language is a cultural phenomenon. Say what?
Olaf Koeneman said,
April 16, 2011 @ 10:14 am
I think people confuse constraints on headedness with constraints on word order. These are not at all the same thing.
In terms of the headedness parameter, I think that the standard theory says little more than "the head either precedes or follows the complement". In terms of restrictiveness, this is hardly a theory, as it predicts that the two logically possible options are actually realized across languages. I don't think it is fair to say that any burden of proof for the generative camp lies in constraints in this area. More strongly put, the fact that a language has two logically possible orders in which to linearize makes it unlikely that we have to specify the possibilities as encoded in the innate system. It is simply a consequence of the fact that words have to be ordered.
As Tunji C rightfully says, it is more useful to google "universal 20 Cinque" (or even better "universal 20 Abels Neeleman" :)) or the "final over final constraint" to get an idea of what is at stake. Or take the fact that no language exists that has verb second at the end of a clause. Things get increasingly more intricate, and therefore more interesting when we take into account movement and constraints on it. These are some of the restrictions pertaining to word order that the generative framework is concerned with and that are hardly taken into account when another article does another easy da peasy Chomsky-bashing.
As Jan Koster said today, "Chomsky deserves better critics".
Tunji C. said,
April 16, 2011 @ 10:37 am
MYL, I am taken aback by the content and tone of your replies, especially given how thoughtful your original posting was.
1. You write "It's certainly true that the wide scope for interaction among parameters in such theories means that they predicted little or nothing about observable word orders, at least in categorical terms." No. Specific parametric proposals do make very clear predictions about observable word orders, but because parameters interact, the predictions are complex. In virtually every language, different factors interact to yield the surface word order. That is what makes a study like the one in Nature pointless as a test of the validity of parametric approaches to syntax (or of any particular proposal I've ever seen). It's just not true that a theory with a head-final setting for a head-parameter predicts that all verbs and prepositions will follow their objects in the sentences of the language (or even in most of the sentences of most languages). It depends on what else each individual language does. That requires careful study of the relevant languages (which is what generative linguists try to do). Give a language the verb-second property or object shift or pronoun cliticization – and suddenly a head-final language is showing lots of VO orders (and as Koeneman points out, gets falsely categorized as head-initial in the Nature paper). This isn't an occasional perturbation in the data of a few random. Complex interactions are the rule, not the exception.
2. Then you write "But in typical instantiations of such theories, there were default settings, creating a scale or structure of relative markedness, which in principle would have generated predictions about the relative frequency of observable orders." There certainly are proposals that some parameters have default settings, for reasons (good or bad) connected to issues in language acquisition. But this idea makes no straightforward prediction about relative frequency of observable surface word orders for the same reasons such theories do not make simple predictions about word order in the first place.
3. Finally you write "However, I use the past tense, because (in my limited understanding) this whole line of inquiry has been ended among the orthodox, since C's current grammatical ontology does not include notions such as "head" or "parameter" as basic concepts, and thus no longer has any way even to formulate the issues." What purpose is served by snarky language like "among the orthodox" (or your earlier reference to "Chomsky and his followers")? When I discuss generative work relevant to word order, I am referencing some work that is influenced by Chomsky's ideas, but also by the results from many other linguists – and by deep engagement with the complex data of actual languages.
As it happens, however, as far as I know, the notion of "head" is alive and well even in Chomsky's thinking. The question of how to understand language variation, on the other hand, is a matter of continuing dispute and discussion, and there are many views being pursued. Mark Baker, for example, is still an advocate of the logic of parameters, as is (I believe) your own colleague Charles Yang. Other researchers pursue other ideas. It's like, you know, a field.
[(myl) Sorry for giving offense. But when I wrote that "generative" syntactic theories over the past couple of decades have "predicted little or nothing about observable word orders, at least in categorical terms", I meant exactly the same thing as what you state in your correction: Because of the interaction of parameters, these theories predicted little or nothing at the level of the crude and superficial features considered by Dunn et al. (which Simon Greenhill defends by writing "these features were identified as atomic by other people than us and we just tested them"). So I found it odd that Dunn et al. gave "Chomsky" responsibility for a position that he never held, except perhaps by several steps of implication from ideas that he has long since repudiated.
As for distinguishing followers of Chomsky's current program from those who retain allegiance to his earlier ideas, it's true that using the term "orthodox" suggests that peoples' choices involve a component of faith. Do you think that this is wrong?]
Tunji C. said,
April 16, 2011 @ 11:22 am
MYL,
Concrning your first paragraph above, thank you for the clarification.
Concerning the second paragraph: of course we favor the theories and hypotheses we do in part as an act of faith. But when you characterize adherents of a particular proposal as "followers" of a famous person who happens to advocate the proposal, it demeans both the proposal and its adherents. It's hard not to read it that way, since "follower" is not a flattering term, and characterizing someone's scientific views in personal terms is a way of implying that they hold those views for exclusively non-scientific reasons. A Google search for "Darwin and his followers", for example, produces a heavy preponderance of creationist sites and blog comments.
[(myl) It seems clear to me that the pattern of opinion-formation following Chomsky's changes of theoretical direction has been different from the effect of others in the field, in ways that suggest that many people are reacting (positively or negatively) for reasons of allegiance and group identity rather individual intellectual evaluation. Without wanting to offend anyone, I feel that both the positive and the negative allegiances are problematic, for linguistics as they would be for other disciplines.]
In the case at hand, by the way, what you describe as Chomsky's "earlier ideas" about language variation in fact were actually the ideas of Tarald Taraldsen, Luigi Rizzi and Richard Kayne. And what you describe as Chomsky's *later* ideas about language variation are in fact ideas of Hagit Borer's. If anyone was a follower here, it was Chomsky himself.
[(myl) Indeed. But this is not the way it's generally presented in the popular press. And the specialist literature is not entirely better, as you can see by searching Google Scholar for "Chomsky's Principles and Parameters" or "Chomsky's Minimalist Program".]
Stevan Harnad said,
April 16, 2011 @ 12:37 pm
LINGUISTIC NON SEQUITURS
(1) The Dunn et al article in Nature is not about language evolution (in the Darwinian sense); it is about language history.
(2) Universal grammar (UG) is a complex set of rules, discovered by Chomsky and his co-workers. UG turns out to be universal (i.e., all known language are governed by its rules) and its rules turn out to be unlearnable on the basis of what the child says and hears, so they must be inborn in the human brain and genome.
(3) Although UG itself is universal, it has some free parameters that are set by learning. Word-order (subject-object vs. object-subject) is one of those learned parameters. The parameter-settings themselves differ for different language families, and are hence, of course, not universal, but cultural.
(4) Hence the Dunn et al results on the history of word-order are not, as claimed, refutations of UG.
Harnad, S. (2008) Why and How the Problem of the Evolution of Universal Grammar (UG) is Hard. Behavioral and Brain Sciences 31: 524-525
[(myl) Interestingly, Chomsky seems to have always disagreed with this position about the role of evolution, as his back-and-forth with Pinker and others indicates.
Anyhow, you've given us a lovely example of the "turns out" rhetorical device. Thanks!]
YM said,
April 16, 2011 @ 2:15 pm
Fig. 3 in the Nature paper shows different probabilities in An and IE of going from Postposition-VO to other states. But where are the postposition-VO languages (blue-red) in either of these family trees in Fig. 1?
[(myl) I presume you mean this figure? (I ask because it has no colors…)
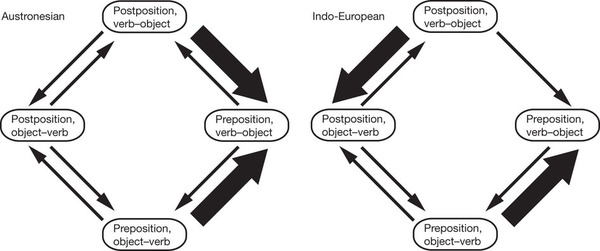
This is another good question for the authors' FAQ. Which is a short way of saying "I don't know".
But my guess is that this is the result of some kind of bayesian parameter estimation, in which an actual observed transition-count of 0 can reflect a non-zero underlying probability. But also, don't forget that their method involves averaging over many hypothesized histories of unattested parent languages, whose configurations of traits are (as I understand it) stochastically reconstructed by the software. So maybe there are some postposition-VO languages in the hypothesized history — and the lack of any very probable transition to the postposition-VO state is why none of them are left to tell the tale :-). Which is a long way of saying "I don't know".]
Dan Lufkin said,
April 16, 2011 @ 2:57 pm
As a side-issue, it'd be interesting so see how many actual students of Chomsky (i.e. people who've taken a regular academic class taught by him) we have on LL. Is there a Chomsky number in linguistics like the Erdös number in mathematics?
I took Syntactic Structures at MIT in the spring semester of 1958 and for my money Chomsky was one of the very best teachers I've ever had. At the time, he didn't appear to be interested in politics at all.
Ray Dillinger said,
April 16, 2011 @ 3:30 pm
As students in computer science, we studied Chomsky when we studied generative grammars. I mean, the idea of generative grammars with terminals and nonterminals (and even meta-grammars) was developed originally by Panini for his grammar of Sanskrit as I understand it, but Chomsky provided us the theory that divides grammars into types that depend on and define what language they generate, and that theory (specifically, the grammatical constraints for type 1 and type 2 grammars) forms the basis of the structure of virtually every programming language and other formal language developed since his work was published. We define the grammars of our formal languages in terms of production rules, and we constrain the production rules according to Chomsky's theory to produce type II languages because they are flexible and unambiguous but can be very efficiently parsed.
In computer linguistics, we find that generative grammars are also a reasonable model for parsing 99% of well-formed, grammatical sentences in natural (written) languages, although if you want to represent a natural language without resorting to meta-grammars or type III grammars, you will be writing books and books of production rules (or equivalently link-grammar rules) trying to get to that last 1%, and being confounded by "ungrammatical" sentences and unresolvable ambiguities even in correctly parsed sentences.
Remember that for computer linguistics we don't care so much about the question central to "real" linguists of how the process of language generation works in humans; we were looking for a process we could efficiently use in software and get results with. Chomsky's generative grammar theory provided us with an idea, related algorithms, and classification/constraint schema that can be covered in two lectures and fully fleshed out in another five.
I'm not a Chomsky "follower" or even a "real" linguist, and I don't believe that that model is how language generation in humans works — but I have not seen anything so devastatingly USEFUL as Chomsky's theory on generative grammars, for our purposes, anywhere else in the world.
I know there's a lot of rancor about Chomsky in the "real" linguistics community, and I know he's known more as a controversial political activist than as a linguist and that lots of people can't hear anything good about his work without assuming you support his politics — but for my purposes? Nobody else in the linguistics community, as far as I know, has produced a theory combining simplicity, elegance, and utility as well as Chomsky's work on generative grammars.
Ray Dillinger said,
April 16, 2011 @ 3:51 pm
I am intrigued by the idea of Universal Grammar. Where can I learn about it explicitly enough to build a software model of it and randomly provide sets of parameters to see if it functions as an automated model for automatically generating grammars for plausible languages, eg, conlangs?
Tunji C. said,
April 16, 2011 @ 4:26 pm
Ray,
you might contact Sandiway Fong at the University of Arizona, or Ed Stabler at UCLA.
YM said,
April 16, 2011 @ 5:28 pm
myl: If there are some guesses, based on Bayesian methods or whatnot, for the characters associated with the intermediate nodes — the protolanguages — I would like to see them. For now, I suspect that they do not agree so well with what the historical linguists would assign these nodes.
This is kinda important. If 20 langugaes out of a sample of 100 show some trait, but they all descended from a common ancestor showing this trait, that is less remarkable than 20 languages developing this trait independently, and would have a significant effect on the statistics. In the family trees shown in the paper, the oddballs tend to cluster as descendants of common proto-nodes.
Jerry Friedman said,
April 16, 2011 @ 11:41 pm
@Ray Dillinger: The paper of Stevan Harnad's that he linked to contains the sentence "And UG remains a set of rules that most of us (including me!) still don't know to this day — don't know explicitly, that is, in the sense that we were never taught them, we are not aware them, we cannot put them into words, and we would not recognize them (or even understand them, without considerable technical training) if they were explicitly told to us in words (and symbols) by a professional grammarian." For whatever that warning is worth to your request.
I've never been interested in conlanging, but if the universal grammar is or were to be known, and if I could understand it without years of study, my first impulse would be to invent a language that violated it. Or is the idea that no human being could do that?
Ray Dillinger said,
April 17, 2011 @ 9:47 am
Heh. My first idea too, as an experiment. We don't know what enforcement mechanisms UG has, if any. But language grammars have the complexity C( r ) of recursive structures, so a meta-grammar for them, if one exists, can be expressed in C( r ) or less.
If UG's rules can be formalized, then we can apply Gödel's technique to try to break it, by mechanically generating a "Gödel sentence" for UG: a C( r ) grammar that does not correspond to any possible UG parameter set. If we are successful in so doing, then we get to find out whether humans are capable of learning and using the resulting conlang, and that should teach us something interesting about UG and what it says about human cognitive capabilities. If people can learn and use the conlang, then it means that UG's enforcement mechanism is somehow a network effect rather than a limitation on individual performance.
Alternatively, we may discover that UG has only complexity C(k) of Kleene structures or C(*) complexity, in which case Gödel's technique would reveal that it cannot be broken at all. In that case we could prove that any C( r ) grammar that can be expressed at all corresponds to some setting of UG parameters, and that UG is therefore a null hypothesis predicting no constraint as to linguistic structure or human language capabilities. (the same "not even wrong" criticism has been leveled at String Theory in physics; no matter your model of the universe, it is possible to construct an instantiation of String Theory that corresponds to it – therefore String Theory itself makes no prediction as to the structure of the Universe.)
Either way, It would teach us something interesting.
Stevan Harnad said,
April 17, 2011 @ 10:19 am
MASTERING TECHNICAL CONTENT
@Jerry Friedman: "if the universal grammar is or were to be known, and if I could understand it without years of study, my first impulse would be to invent a language that violated it."
Maybe the first impulse should be the years of study. After all, that's what I'd have to do before I could know whether it makes sense to try to trisect an angle, count the real numbers, or hitch a ride on a tachyon.
Stevan Harnad said,
April 17, 2011 @ 11:15 am
PS And the question is not whether one can invent a language that violates UG (one can, and it's been done), but whether a child could learn it as a first language (no one's tried that, for obvious reasons)…
Jerry Friedman said,
April 17, 2011 @ 12:36 pm
@Stevan Harnad: Thanks for answering my questions. Your PS was particularly helpful.
On the subject of those obvious reasons, there was the guy who tried to bring his son up as a native speaker of Klingon.
By the way, this is not the place to get into detail, but the one about counting the real numbers would take less than an hour for anyone with any interest in the topic. There are many better examples in math and science, such as the proof of Fermat's Last Theorem or why quarks and leptons have to come in pairs.
SK said,
April 17, 2011 @ 1:06 pm
This is a pretty basic question, but one which I think other people following this thread may be wondering about as well: if UG is a set of rules that we do not know explicitly, cannot put into words, and would not recognize if we were shown them, what is the basis for saying we know that these rules are (a) unlearnable on the basis of linguistic input and (b) universal to all known languages? It strikes me that it would be hard to prove both (a) and (b) even for a rule which we can actually formulate, let alone for one we can't. Am I missing the point here?
It would be great if Stevan Harnad (or some other UG researcher reading this thread: I mention Stevan Harnad just because he's made the strongest claims for what we know about UG at this point) could give an example of a rule which we actually know to be both unlearnable and universal to all languages, and how we know those things to be the case. Just to be clear: I'm not trying to attack the concept of UG here, I just don't feel that I have a good sense of what kind of rules it is supposed to be made up of.
Olaf Koeneman said,
April 17, 2011 @ 1:47 pm
An example often used is subject-auxiliary inversion. The sentence in (1) is turned into a question (2) by a rule:
(1) The boy is smiling
(2) Is the boy smiling?
A child could hypothesize that the correct rule is "move the first auxiliary counting form the left to the front". This is the wrong rule, as it would predict that the kid could utter "Is the boy who in the corner is smiling?". A kid never does that, and no language has this rule. Question: why would a child never postulate this wrong rule? Answer: it would need sufficient examples with a subject modified by a relative clause (such as "the boy who is in the corner") and see that it is not the auxiliary in the relative clause that moves. As argued by Legate and Yang (The Linguistic Review 2002), those examples do not seem to occur enough in the input. So here would be a case of knowledge, probably true for all languages, for which it is unlikely that the kid picks it up from the input. It is not a universal rule, so to say, but a universal constraint that is unlearnable. But this constraint forbids the child to postulate a logically possible but not occurring rule.
SK said,
April 17, 2011 @ 3:03 pm
Thanks, Olaf! Is there a consensus on what sort of rule/constraint this suggests is operating in this case? What I mean is: as not all languages make questions by moving auxiliaries around, nobody would want to posit a rule in UG along the lines of 'To make a question out of a statement, move the auxiliary in the matrix clause'. So do people think the rule/constraint in UG which directs the acquisition process is likely to be something like 'When making questions, don't mess with the insides of subordinate clauses', or something more specific, or something more generally applicable, like 'Sentences have internal structure, so don't bother postulating any rules which are just based on linear order'?
Olaf Koeneman said,
April 17, 2011 @ 3:14 pm
The last thing you say, pretty much :)
SK said,
April 17, 2011 @ 3:58 pm
So is the idea that – without being told this explicitly by UG – a child could not even learn something at such a high level of generality as 'Sentences have internal structure', just from listening to hundreds of thousands of sentences and spotting that they behave as if they do have internal structure? I suppose my point is: presumably nobody believes that children (at the age when you can test them for subject-auxiliary inversion etc.) have no tacit knowledge that the language they're acquiring has sentence structure of some kind, so that isn't the issue. The question is, is that the kind of thing that a child would be unable to work out without being told in advance by UG?
David Marjanović said,
April 17, 2011 @ 4:25 pm
As a native speaker of German, I emphatically disagree that it's underlyingly OV. I readily accept, of course, that it has evolved from an OV language, but synchronically, in my head, it's verb-second by default, and conjunctions other than denn trigger verb-last word order, which is necessarily OV.
Sentence without an object, where the VO/OV distinction is inapplicable:
Es ist so. Main clause; verb-second by default.Ist es so? Question; verb-first., es ist so. Dependent clause not initiated by a conjunction; verb-second by default., weil es so ist. Dependent clause initiated by a conjunction other than denn; verb-last., denn es ist so. Dependent clause initiated by denn; if you count the denn as a slot in the word order, it's verb-third, if you don't, it's verb-second by default.
Sentence with an object:
Ich sehe ihn.Sehe ich ihn?, ich sehe ihn., weil ich ihn sehe., denn ich sehe ihn.
You're probably right about the rule… but the result happens to be perfectly grammatical German.
Ist der Bub, der in der Ecke ist, lächelnd?
Unidiomatic*, but fully grammatical.
But let's return to the rule. Is it really not a matter of simple logic to leave the relative clause alone? After all, its beginning and end are marked by intonation even if you don't understand it. Maybe "simple logic" is innate rather than this kind of word-order rule.
* There is no progressive, so we wouldn't say ist lächelnd, we'd say lächelt; but that's the only thing that's wrong with ist … lächelnd – the word order is just fine. Also, we'd strongly tend to clarify how the boy "is" in the corner: "stands", "sits", "lies"… again irrelevant to word order.
David Marjanović said,
April 17, 2011 @ 4:30 pm
Ah. The preview made the very weird error of putting an empty line between the fourth and fifth paragraphs of my examples, so I replaced the paragraph breaks by <br> tags, which worked in the preview but not after submitting. Again, with paragraph breaks:
==============
Sentence without an object:
Es ist so. Main clause; verb-second by default.
Ist es so? Question; verb-first.
, es ist so. Dependent clause not initiated by a conjunction (as in: Er sagt, es ist so.); verb-second by default.
, weil es so ist. Dependent clause initiated by a conjunction other than denn; verb-last.
, denn es ist so. Dependent clause initiated by denn; if you count the denn as a slot in the word order, it's verb-third, if you don't, it's verb-second by default.
Sentence with an object:
Ich sehe ihn.
Sehe ich ihn?
, ich sehe ihn.
, weil ich ihn sehe.
, denn ich sehe ihn.
Olaf Koeneman said,
April 17, 2011 @ 4:41 pm
Well, I don't think that the average generative linguist will tell you that children cannot learn any syntax whatsoever without being preprogrammed. Children can do a lot. The question is whether the input is enough to account for the full knowledge that children have obtained at around, say, four. And another question is whether children make all the mistakes you expect them to make on a trial-error basis or whether their error patterns show systematic gaps, i.e. things they never try out but could have tried out. So in short, there is a large part where the innateness hypothesis and the input hypotheses might do equally well. You have to look for decisive facts/observations.
And as Chomsky would stress, the learnability issue is just one thing. You also want to know why the facts are as they are. Why is there no language that would shift the first auxiliary? He recently verbalized his criticism on statistical approaches to language acquisition in a talk in Leiden. It's here:
http://www.chomsky.nl/component/content/article/10-noam-chomsky-in-nederland-maart-2011-/137-lezing-14-maart-van-noam-chomsky-in-leiden-over-syntax
It's in the first 20 minutes, and I think it is reasonably accessible.
Alan said,
April 17, 2011 @ 4:44 pm
The reaction to this article just once again demonstrates several problems in the culture of linguistics today:
1) Some Chomskyans see all research as either being for or against them, and they are very defensive and sensitive to any criticism, even implied, of their research program.
2) Many non-Chomskyans are all too willing to play into this, thus ensuring that discussion of their research, whatever that research may be, will be instantly transformed into a referendum on Chomsky, including endless debates about what Chomsky thinks, what he said, when he said it, ad nauseum.
3) The most exciting work in linguistics is increasingly being done by non-linguists publishing in mainstream science journals.
It's too bad.
Olaf Koeneman said,
April 17, 2011 @ 4:51 pm
@David Marjanović:
German is OV because the main clause word order is derived from the embedded clause order by the verb second rule. The verb second rule gives you superficially VO but it is not VO of the English type, as the subject can easily intervene: a German main clause can also have a (X)VSO main order. In other words, the VO order is main clauses is not a base order, it is derived. If you build a grammar that says that German is VO and the embedded OV order is derived, you get a much more complicated grammar. The fact that German is an OV language is undisputed, as far as I know. The only issue is whether or not this embedded OV order is again derived from a VO order, which is an entirely separate discussion which does not bear on main clauses.
>>But let's return to the rule. Is it really not a matter of simple logic to leave the relative clause alone?
How would the child acquire this logic? What tells the child "leave the relative clause alone"?
Olaf Koeneman said,
April 17, 2011 @ 4:55 pm
@Alan:
I am sorry, but your reaction is competely uncalled for. It is the Dunn article that very explicitly argues against the innateness hypothesis. Generativists defend themselves and then we are touchy. Come on!
I think that if some article says that the Chomskyan claim is wrong and that same article classifies German as a VO language, that is, well, either ironic or sad. You pick. I would say: Let's do some linguistics before we make claims about linguistics.
SK said,
April 17, 2011 @ 5:10 pm
Thanks very much for your responses, Olaf – and I look forward to watching the talk!
Olaf Koeneman said,
April 17, 2011 @ 5:28 pm
@SK
No thanks, and have fun!
@David Marjanović
Oh you mean logic is innate. But then what is the connection between more general logic and the logical principle that tells you to ignore relative clauses? Why doesn't logic tell you to pay special attention to relative clauses?
Alan said,
April 17, 2011 @ 5:54 pm
@Olaf
I intended that more as a criticism of non-Chomskyans, actually. Of course people should and have every right to defend their own research. But note that more time here has been spent interpreting Chomsky than, for instance, discussing the phylogenetic techniques which the study is based on. Then there's the "everyone's always mindlessly persecuting Chomsky" bit which we have, predictably, already seen in action here.
I should also say that I had in mind not just this thread, but the reaction overall to this article and many others like it.
Alan said,
April 17, 2011 @ 6:36 pm
This might be worth pointing out. As far as I can tell the paper never makes a claim about anything Chomsky said. It refers to "Generative linguists following Chomsky" and "the Chomskyan approach". Most of the references are to other linguists, such as Lightfoot and Baker.
Tunji C. said,
April 18, 2011 @ 12:05 am
Tunji C. Says:
Changing the subject for a moment, am I reading the chart of language data correctly? Scanning just the Indo-European list, I see:
1. Ancient Greek classified as post-positional. But it was not, was it?
2. Byelorussian classified as “polymorphic” with respect to verb and object, while Russian and Ukranian are classified as verb-initial. Don't these three languages have basically identical word order?
3.Kashmiri called VO – but isn't it actually a verb-second language like German are classified as “polymorphic" and not VO?
4. Lusatian (Sorbian), both Upper and Lower are classified as OV. But to judge from what I can see of these languages on the web, they are as VO as the rest of Slavic.
Am I misreading the chart? If not, is the rest of the data this bad too?
Tunji C. said,
April 18, 2011 @ 12:21 am
Slight correction to point 4 above: in a book by Siewierska (via Google Books) she remarks that SOV order in Sorbian is "much more common than in the other Slavic languages", but adds that "there is currently no statistical data available to suggest that SOV order is in fact the dominant main clause order".
Norvin said,
April 18, 2011 @ 12:34 am
The case of the language they call "Papago/Pima" (Tohono O'odham) is maybe similar to Sorbian: they list it as a verb-object language, perhaps because Dryer claims in WALS on the basis of text counts that it's verb-initial. But Dryer's criterion for "verb-initial" is "verb-initial at least two-thirds of the time in texts", and Tohono O'odham is famous for its free word order, so this seems like another judgment call that could have gone another way.
Alan said,
April 18, 2011 @ 12:42 am
From the supplemental materials:
"The typological data and coding principles used in this study are derived from Dryer's word order typology data published in Haspelmath et. al (2005). A form of this data is also available online at http://wals.info (Dryer 2008a-h)."
But apparently they supplemented this with other sources, which they explain in this document.
Olaf Koeneman said,
April 18, 2011 @ 1:39 am
@Alan:
Thanks for your clarification above.
About the source, if I look at the map on internet, then Dutch, Frisian and German are classified as "no dominant word order".
http://wals.info/feature/83?tg_format=map&v1=c00d&v2=cd00&v3=cccc&s=20&z3=3000&z1=2999&z2=2998
This shows that what is indeed used in the notion "dominant", with references to very old literature (Shetter 1958 for Dutch, which causes the mistakes. So I don't know on the basis of what Dunn et al classified Dutch, Frisian and German as VO, but it wasn't on the basis of well known, very accessible generative insights from the late 70s (!).
Tunji C. said,
April 18, 2011 @ 9:00 am
I wonder just how much of the classification that underlies the paper will turn out to be (1) indisputably and obviously false, (2) random, with differing "judgment calls" covering up essential identical word orders, (3) false if longstanding research results ignored by the authors are taken into account (Koeneman's cases: verb-second exists & can obscure underlying orders). And if you fix the mistakes and flip some of the judgment calls so similar languages get similar classifications, what will we be left with?
[(myl) In my opinion, one problem here is that no one has offered a comprehensive, stable, and usable alternative to Greenberg's word-order classification scheme as adapted by Dryer for WALS. The Greenbergian scheme is rather crude and superficial, especially with respect to clause-element orders. It entirely fails to give even the observational categories needed for registering the data behind most of the (in my opinion interesting and suggestive) work in historical syntax over the past century, much less the past couple of decades. But as long as it appears to be the only game in town, outsiders (i.e. non-syntacticians) will use it (with all the necessarily resulting equivocations and inaccuracies) and try to explain its distributions in space, time, and linguistic history.
Why is there no better alternative? I'm not sure. Perhaps it's because the work in historical syntax is (for good reasons) focused on details that are simply not available for most of the world's languages. Perhaps it's because the relevant theoretical background has been constantly changing, requiring at a minimum that all the work needs to be translated into new terminology every decade or two, and suggesting that any overall descriptive scheme would soon be overtaken by events.
To the extent that the second of those speculations is true, this is one of (the least important of the) many unfortunate consequences of our field's recent failure to define a stable descriptive system.]
Olaf Koeneman said,
April 18, 2011 @ 9:55 am
@myl:
I fully agree with your first observation but a bit less with the second, I guess. To use the same example for the sake of coherence, saying that Dutch and German are SOV languages with a V2 rule in main clauses is a completely neutral, framework-independent description of a fundamental word ordering property of these languages. Although theories about how to describe these facts theoretically may change every year (in terms of what is more basic and what is derived, and what kind of structure and functional projections are needed to describe it), the basic description has not changed since the 70s and will not change any time soon. You therefore just have to find them and, to be honest, these descriptions are all over the shop and can be found in many introductory textbooks.
[(myl) Yes, I agree — framework-neutral informal descriptions of this kind are ubiquitous in syntax (and in phonology as well). The trouble is, no one has taken the step of crystallizing this shared descriptive vocabulary into a form that would allow it to be used as (say) an overall alternative to the Greenbergian word-order typology, or (more importantly) as a source of framework-neutral "treebank" descriptions for the world's languages, or (even more importantly) as the basis for an accessible system of syntactic description that could be taught to schoolchildren.]
If the only feasible way of doing the kind of research Dunn et al engage in is by taking one source and work with it the best you can, you have to accept (i) that there may be fundamental flaws in it (ii) that this kind of criticism comes your way and (iii) that the claims you are going to make on the basis of the data you use have to be way more modest than you want them to be. The Dunn et al paper does not score well on the last point.
Tunji C. said,
April 18, 2011 @ 10:12 am
@(MYL@me)
I couldn't disagree more.
1. It seems you are arguing that we should forgive or even condone papers that draw sweeping conclusions about language from an analysis based on a "crude and superficial classification because "it's the only game in town" for people who want to do this work. If it's the only game in town, and the game's bad, then maybe the kind of work that the Nature authors wanted to do just needed to wait. Or maybe they should have launched a multi-year project to figure out a more informed classification system as a precondition to the work they really wanted to do.
Frustrating for folks in a hurry, sure. But tough luck. If you don't have the data you need for your work, you're supposed to go out and *get* it, not use bad data (Ancient Greek was postpositional?) – just because it's "the only game in town".
2. If syntax really is changing its terminology and theoretical background every decade or two, maybe it's because there are new ideas and findings that demand it. In which case why shouldn't researchers other fields learn how to keep up. (One easy way: add some syntacticians to the project.) But I think you are exaggerating the problem. The basic widely accepted analysis of verb-second, for example, goes back many decades, unchanged in its essentials. People do argue over details like the best name for the position in which the verb is found and whether it is always the same position (or exactly what kind of rule puts the verb there). But here we have a study of word order that never even heard of verb-second in the first place. That's inexcusable in a study like this one. Don't blame that on the syntacticians.
Link love: language (29) « Sentence first said,
April 18, 2011 @ 3:17 pm
[…] New findings in word-order universals: summary; report from the Max Planck Institute; paper; discussion. […]
Olaf Koeneman said,
April 18, 2011 @ 4:59 pm
>>But here we have a study of word order that never even heard of verb-second in the first place. That's inexcusable in a study like this one. Don't blame that on the syntacticians.
Amen.
From where I stand, looking at a scientific field that has progressed as much as linguistics has in the last 60 years, a defense of the type "these features were identified as atomic by other people than us and we just tested them" is a bit like saying "the earth was identified as flat by other people than us and we just tested that" (where the verb "tested" has to be taken in a very loose sense, obviously.). It doesn't radiate an interest in state of the art. It doesn't radiate an interest in linguistics.
Tunji C. said,
April 18, 2011 @ 7:29 pm
Since it looks like this discussion is winding down, I wanted to summarize what I think I've learned. This is an article:
1. whose data are bad,
2. whose analysis is dodgy,
3. whose grip on relevant literature is weak, and
3. whose conclusions are non-sequiturs.
Those details aside, it's a good paper.
[(myl) In my opinion, you should try to be more charitable and less defensive. You remind me of the embittered structuralists I knew in the 1970s and 1980s; and trust me, you don't want to end up like them!
Throughout the history of generative syntax and phonology, there have been justly-influential papers, based on clearly-false simplifying assumptions; whose data was always methodologically problematic in general and sometimes factually problematic in detail; whose analysis of that data was at least partly questionable; which ignored relevant prior work in other frameworks; and which made some pretty breath-taking jumps from data and analysis to conclusions. To discount these papers and the research community behind them would have been easy — many excellent scholars with other perspectives did so — but it would have been wrong.
It's normal for there to be different approximate models that abstract away from reality in different ways, for different purposes. It's always relevant to ask whether the abstractions are fatal ones, given the purpose of the enterprise, and to explore or suggest exploring other ways to do it. But rejecting an entire enterprise because some of its assumptions are false or incomplete is not a good idea. For example, we'd have to reject essentially all of the kind of syntactic research that you favor, on the grounds that it presupposes an ideal and isolated speaker-hearer with categorical grammaticality judgments, among other obviously false assumptions.
Given that the WALS word-order categories are too coarse, especially in the parts having to do with subject, objects, and verbs, why not suggest better ones? Is there an appropriate taxonomy of V2 that could be added, for example?]
Olaf Koeneman said,
April 19, 2011 @ 12:51 am
Meanwhile my own Dutch newspaper reported this weekend that the idea of an innate language capacity can be thrown in the garbage bin. As reporter Mieke Zijlmans concludes her article: There is no way you can maintain the possibility that there exists something like a universal grammar.
You know what? This annoys me.
[(myl) Welcome to the club of those who wish science journalism were better, or even competent.]
Olaf Koeneman said,
April 19, 2011 @ 12:54 am
Oh, for clarity's sake, the newspaper article was about the Dunn paper…
Olaf Koeneman said,
April 19, 2011 @ 5:52 pm
>>But rejecting an entire enterprise because some of its assumptions are false or incomplete is not a good idea.
Perhaps. But if the enterprise is to argue against a generative claim that does not even exist in the first place, I am inclined to be skeptical about the enterprise nevertheless. We have been discussing this paper for days now, but I still have no idea which existing, still relevant, prominent, generative idea/hypothesis/constraint is on trial here. Generativists expect a certain development over time across different lexical head-parameters? Really, I have no idea.
>>Given that the WALS word-order categories are too coarse, especially in the parts having to do with subject, objects, and verbs, why not suggest better ones?
Well, we have been mentioning introductory textbooks. I don't think this helps, though, if e.g. taking Dutch/German as an SVO language qualifies as an ignorable detail, a passable abstraction. Note, by the way that this does not entail an abstraction away from data that we don't really know how to describe. It's an abstraction away from data that we DO know how to describe.
Claire Bowern said,
April 19, 2011 @ 10:16 pm
At the risk of bringing this comment thread back to Mark's original post… two points.
First, I'm surprised no one has commented on Bantu yet. The Bantu data appear to show a pretty stable (again, lineage-specific) set of correlations, so stable in fact that there was no variation, so nothing to test in the transitional probabilities.
Secondly, I wonder whether the etymology of adpositions might be relevant to the different alignment changes in Austronesian vs Indo-European. A lot of Austronesian prepositions come from serial verb constructions, so it's not at all surprising to me that Postpos/VO with grammaticalized adpositions should grammaticalize as Prepositional order.
Alan said,
April 20, 2011 @ 2:49 am
First, I would just like to say that I thoroughly agree with (or at least enjoyed) Liberman's most recent response to TC.
@Claire
Aren't both of these points in line with the thesis of the paper?
Tunji C. said,
April 20, 2011 @ 7:26 am
@Alan
I think the ad hominem turn of Mark's remarks was unfortunate. But if you think after all the discussion here that something of value can still be identified in this paper, taking into account the discussion here, which has touched on so many points – could you tell us what that is?
David Bloom said,
April 20, 2011 @ 7:18 pm
It was the cladogram that got to me, and the vivid picture of how the weak Greenberg correlations (those universals were never anywhere near universal) could be reduced to a pattern of very strong correlations in some families and no correlations in others, a far smarter-looking account of the old data. I suspect if you cleaned up the errors like Ancient Greek postpositions this effect would still hold, maybe less dramatically.
It's very difficult by the way to do this kind of typological coding, with sources ranging from old missionary grammars to the latest and grooviest thing, and the categories themselves are really a problem. I don't see how anybody can confidently classify German as OV or VO when what really happens in the normal declarative is that the V is a discontinuous unit that surrounds the object and all the other arguments. Or in French, which object is the one that counts, pronominal before the verb or noun afterward? On what grounds do you argue? And that's just the superfamiliar languages. As bad as it looks when you point out these mistakes, it is likely that any such study has similar issues–it goes with the territory.
Alan said,
April 20, 2011 @ 9:43 pm
@Tunji C.
Well, without going back and reading everything again, the important criticism has been on individual data points used in the analysis. That's fine, it's always important to scrutinize the data and when it comes to large scale typological work there is always room for improvement. But I do not believe that a handful of questionable judgement calls (which were not, it seems, made by the authors themselves at least in most cases) invalidates the study.
The article employs sophisticated statistical techniques designed to detect phylogenetic signal by comparing traits in species. I am not an expert here, but I feel fairly confident in saying that the authors don't do anything which would raise an eyebrow from phylogeneticists. All of the issues I've seen raised are issues that biologists worry about too. But the nice thing about statistics is that it is expected that there will be some noise in the data. That's one of the reasons we use statistics in the first place. That's not to say that a lot of noise in the data can't produce garbage, of course that can happen. But to dismiss this paper is not, in my opinion, a good idea at this point. Again, this is not just a comment on what I've seen in this thread. This is something I see quite often.
Whether this study stands up to careful scrutiny remains to be seen. Please by all means keep picking away at the data; it's important work.
Olaf Koeneman said,
April 21, 2011 @ 12:36 am
>>I don't see how anybody can confidently classify German as OV or VO when what really happens in the normal declarative is that the V is a discontinuous unit that surrounds the object and all the other arguments.
Quick reply coz I have to catch a train. If Dutch and German are VO languages because in main clauses the verb can precede the object, then English is an OV language because in main clauses the object can precede the verb ("This book, I never read"). Both claims are equally silly, as they fail to see that one order is derived from the other by displacing constituents. Lesson: displacement has to be taken into account.
I will try to reply more detailedly today.
Robert Niblick said,
April 21, 2011 @ 12:43 am
Nice critique, thank you for keeping it real, etc. And thanks to Mr. Greenhill for dropping a couple of comments. I am very interested to see the kinds of progress being made in this area of linguistics and I am excited by these sorts of papers. Progress in linguistics as a whole, really, as you see the same sort of evidence-based ‘revolution’ occurring across the board, in my view. But I am biased and a rabid anti-UG type. I imagine the reality will be a bit more nuanced than a tossing out of old essentialized models. :)
Also, what's the deal with these Harnad comments? Is that a real person? Because I have literally seen the same comment posted at every single website that mentions this article. No discourse, just a hit-and-run copy/pasting. Frankly it's a bit creepy, and in my biased opinion it does little to brunt the force of the paper's implications.
Tunji C. said,
April 21, 2011 @ 9:12 am
@Alan, @Bloom
I think both of your comments amount to a guess that if you fix the problems with the data, the empirical findings will remain the same. In linguistics, that would justify a "revise and resubmit" recommendation to a journal editor, not publication – especially since you don't actually know what the results would look like if you did the work correctly.
@Alan
You write that "the important criticism has been on individual data points used in the analysis", but that disregards all the criticism of the article's supposed implications for competing research programs in linguistics. As I read the paper, that was its claimed point – the punchline – so if that's not right at all a big chunk of the paper goes away. I consider that very important too.
@Bloom
The thing is, linguists *know* what to make of word order in German, and we know how to analyze the position of object pronouns in Romance languages – and German comes out firmly OV (the verb moves left to the complementizer position), while Romance comes out firmly VO (pronouns move to the position of the tensed main or auxiliary verb). As Koeneman will no doubt emphasize, these are such firm results that it is just bizarre to ignore them in a study of word order – and very likely harmful to the integrity of the analysis.
Here's another reason why I think we should worry about this. If the article has so many dubious and incorrect classifications among the Indo-European languages, which is by far the best studied and best understood group, is it likely that things will get any better when we turn our attention to language families like Uto-Aztecan, which have been studied in far less depth, by far fewer researchers?
Olaf Koeneman said,
April 21, 2011 @ 1:52 pm
The general atmosphere (here and elsewhere) is that, although not all the linguistic details may be entirely correct, this does not harm the general claim of the article. The point is: that depends on what you take the general claim of the article to be. If the general claim is "language development is lineage-specific", then I have little to object at this point. If the general claim is "This shows that Chomsky and his followers and claims about universal grammar are wrong"., I object strongly. The reason is that the first claim is not at all incompatible with what generative linguists claim. This point has been made above, but I feel has to be repeated.
The problem is the enormous space between the following two quotes from the beginning of the article:
1. "Generative linguists following Chomsky have claimed that linguistic diversity must be constrained by innate parameters that are set as a child learns a language."
2. "[…] contrary to the generative account of parameter setting, we show that the evolution of only a few word-order features of languages are strongly correlated."
Quote 2 is basically Dunn et al's operationalization of quote 1, but this operationalization is wrong. Generative linguists do not claim that the parameters that Dunn et al use (lexical head parameters) should show strong correlations. The reason is that generative linguists know that languages like Dutch and German exist (to keep the same examples for consistency's sake). In these languages, the VP is head-final (they are OV languages), whereas the NP and AP are head-initial. Many more examples can be given. Now, universal grammar contains statements that constrain the possibilities of a grammar synchronically (i.e. at a moment in time). These constraints are of the type "your language should do A" or "your language cannot do A". But crucially, universal grammar does not contain a statement of the type "your language should not have different head parameter settings for different lexical heads". It doesn't, because that would be wrong empirically and we have known it for decades. Now, if universal grammar does not contain that kind of statement, it certainly does not contain a statement of the type "your language should in the future become A" or "your language cannot in the future become A". Concretely, there is no constraint of the type "the lexical head parameters should over time (dis)harmonize". Universal grammar constrains the possibilities of a grammar at a moment in time. It does not steer language in its development. Universal grammar is a rule book, not a long-term plan.
Why is this important? Dunn et al find that languages evolve differently in different language families. That may be true or false, but since generative linguists do not expect anything in this area, it does not get them overly excited. What does get them overly excited is being told, without proper argumentation, that they do expect something and that the thing they expect is now falsified.
J.W. Brewer said,
April 21, 2011 @ 4:08 pm
I was also a bit confused by the claim that German is an OV language. Admittedly my German has almost three decades of rust on it, but I think of simple expressions like "ich lieb' dich nicht, du liebst mich nicht, aha" as unmarked in a way that Olaf K.'s English example most certainly was not. But then I see that wikipedia claims that "German and Dutch are considered SVO in conventional typology and SOV in generative grammar." (I'm sure there's an elaborate generativist just-so story about why you shouldn't believe what you see – I don't need to know the details for present purposes.) However, the correctness of the generativist analysis here doesn't really matter, assuming the accuracy of Olaf K's more recent point that while generativists believe German to be OV they do not believe anything about how head-final VP's should or should not co-occur with head-final NP's or AP's that is undermined by German being OV. Of course, if different methodological schools are going to classify the same language differently for reasons of their own, esp. with such a well-studied language as German, that just heightens the problem of the non-existence of a really good and uncontroversially accurate dataset covering a representative sample of the world's languages that grand typological theories could then be tested against.
Olaf Koeneman said,
April 21, 2011 @ 4:51 pm
>>I'm sure there's an elaborate generativist just-so story about why you shouldn't believe what you see – I don't need to know the details for present purposes
I am going to give them anyways, JB Brewer, if you don't mind :) If not for your then for other people's benefit. And it's not so elaborate. Let's use English words.
(1) John calls Mary
VO-analysis: Nothing happens
OV-analysis: finite verb moves to the left
(2) John must Mary call
VO-analysis: infinitive moves to the right
OV-analysis: finite verb moves to the left
(3) John has Mary called
VO-analysis: participle moves to the right
OV-analysis: finite verb moves to the left
(4) John called Mary up
VO-analysis: particle 'up' moves to the right
OV-analysis: finite verb moves to the left
(5) Today calls John Mary up
VO-analysis: finite verb moves to the left
OV-analysis: finite verb moves to the left
(6) …that John the book reads
VO-analysis: finite verb moves to the right
OV-analysis: nothing happens
(7)…that John the book read must
VO-analysis: both the finite verb and participle move to the left
OV-analysis: nothing happens
etcetera…
Summary:
-OV analysis: The embedded clause (in (6) and (7)) gives you the basic order and there is a rule in main clauses that moves the finite verb to the left (in (1) to (5)).
-VO analysis: The SVO main clause gives you the basic order, but there is a rule in embedded clauses that moves infinitives to the right (2), there is a rule that moves participles to the right (3), there is a rule that moves particles to the right (4), there is a rule that sometimes moves the verb to the left in main clauses (5), and finally there is a rule that moves finite verbs to the left in embedded clauses (6).
Question: which is the simpler grammar?
It seems that Dutch and German children have less trouble getting the basic order than a few linguists: as soon as they can form two-word sentences, they come out in an OV order, in contrast to English children.
Reference: Jan Koster (1974)
Link: http://www.dbnl.org/tekst/kost006dutc01_01/kost006dutc01_01_0001.php
Alan said,
April 21, 2011 @ 9:19 pm
Tunji C. said:
"@Alan, @Bloom
"I think both of your comments amount to a guess that if you fix the problems with the data, the empirical findings will remain the same. In linguistics, that would justify a "revise and resubmit" recommendation to a journal editor, not publication – especially since you don't actually know what the results would look like if you did the work correctly."
Yes. But this gets at a major methodological division between statistical methods and deterministic methods, and I think this accounts for a lot of the disconnect between mainstream linguistics (especially syntax) and the sort of studies we have exemplified here.
Practically speaking, I think it's safe to say that in large scale statistical studies (of whatever kind) we expect some problems in the data. To suggest (and I think this is what you suggest) that we can not begin to perform such studies without pristine (and, for that matter, theoretically agreeable) data is not realistic.
Ultimately, we will see whether these results are reproducible, especially with better data. I see no reason to come down on the authors for breaking new ground here.
Alan said,
April 21, 2011 @ 9:33 pm
Tunji C. said:
"You write that "the important criticism has been on individual data points used in the analysis", but that disregards all the criticism of the article's supposed implications for competing research programs in linguistics. As I read the paper, that was its claimed point – the punchline – so if that's not right at all a big chunk of the paper goes away. I consider that very important too."
I assume you've all seen Dwyer's criticisms from a very different theoretical perspective?
http://listserv.linguistlist.org/cgi-bin/wa?A1=ind1104B&L=LINGTYP
As I alluded to before, I don't think that these uber-theoretical claims are generally very important. The empirical results are what matter. Yes, perhaps they overstated the theoretical import of their results (though that's certainly debatable), but as I tried to suggest before those claims are not very important. Unfortunately they raise a lot of hackles and the ensuing debate tends to eclipse whatever scientific merit the study does (or doesn't) have.
Olaf Koeneman said,
April 22, 2011 @ 8:27 am
So the generativists conclude that the Dunn et al paper does not affect their work, Dryer concludes that it does not affect his work. Now, granting for the moment that Dunn et al's claim that it does affect all this work is not very important, and granting that all the linguistic misanalyses are not very important, and granting that what they find is nevertheless still meaningful in a significant way (quite some "granting", if you ask me but okay), then I am left with two questions:
1. What is so interesting about the claim that languages change lineage-specifically?
2. Why are changes in the lexical head parameters over time qualified as evolution? What is evolving exactly? When English changed from being an OV language to being a VO language, in what respect did it "evolve"? What is the difference between "mere change" and "evolution"?
To be sure, these questions are not intended as rhetorical. I would really like to be informed on these points.
Language Is General? – Interesting Science said,
April 22, 2011 @ 2:59 pm
[…] This, they say, is inconsistent with the currently dominant linguistic theory of "language universals" fixed by the structure of the human brain/mind. One of the authors has written an excellent explanation here and languagelog has a nice discussion here. […]
David Bloom said,
April 22, 2011 @ 10:37 pm
@Tunji C.
Ah, the little buggers *move*, do they? And so researchers can ignore where they are in favor of this specialized knowledge of where they used to be, whenever it was that they were there.
Seriously, I don't believe they do move. If you tell me that in that case I have to give you a description of German without any movement rules before you'll take me seriously, that's totally fair. But the person testing a theory on a wide cross-linguistic basis has to take the data as they are, not as the theory say they are supposed to be, or it just isn't a valid test.
@Olaf Koeneman
The claim that the change occurs in lineages is not especially interesting. What is interesting is the demonstration that it is *only* within lineages and not across them (pace Dwyer as mentioned above)–that the weak Greenberg universals simply disappear in favor of much stronger correlations in some families and zero correlations in others, that it is not in effect a universal phenomenon at all. (I do not actually think the data directly damage the generative theory of UG, though if there was a really good competing theory it would likely support that.)
As to the difference between change and evolution, it would depend on how "evolution" is being used, wouldn't it? It should not be used to suggest the attainment of some final optimal stage, or to suggest that some languages are more highly evolved and therefore better. Dunn et al. seem to point with their little arrow diagrams at some "optimalization" processes, but of course each such optimalization would lead to something else going awry and needing to be improved in its turn, and languages will continue to change. If it is used to suggest the existence of processes of change beyond the control of any individual speaker and driven by chance mutations, then it is sort of interesting, if not exactly novel.
As to two-word utterances in German and Dutch: If I am right, the Vorfeld-Satzfeld distinction, in which the Vorfeld is whatever the speaker decides to put up front, whether a subject, object, or adverbial, and the Satzfeld is always dominated by a verb, is the absolute driving engine of German sentence structure. In a two-word sentence in which one word is the object, it has to come first, it's not until you have a third element that you even have a choice.
Tunji C. said,
April 22, 2011 @ 11:15 pm
"Ah, the little buggers *move*, do they? And so researchers can ignore where they are in favor of this specialized knowledge of where they used to be, whenever it was that they were there."
No, that's not exactly right. Rather, once it is established that the position in which the verb or the direct object gets pronounced is located outside the verb phrase in certain sentence-types, we can no longer use the relative ordering of the verb and its direct object as evidence for verb-object order within the verb phrase. So if that's what we are interested in, we must either examine sentence-types in which the verb and the direct object do remain within the verb-phrase, or (if necessary, and if possible) look for more indirect evidence concerning their ordering. The position of separable prefixes (Koeneman's examples 4 & 5) is evidence of that type in Dutch and German.
But the comments section of a blog is not the optimal medium for a syntax lesson. Two of Mark's colleagues at Penn have an online syntax textbook that includes a chapter on verb-second: chapter 14 of http://www.ling.upenn.edu/~beatrice/syntax-textbook. It's a good place to start for more information. The textbook also contains a few relevent remarks about Romance clitic pronouns.
Olaf Koeneman said,
April 23, 2011 @ 3:23 am
@David Bloom:
>>"As to two-word utterances in German and Dutch: If I am right, the Vorfeld-Satzfeld distinction, in which the Vorfeld is whatever the speaker decides to put up front, whether a subject, object, or adverbial, and the Satzfeld is always dominated by a verb, is the absolute driving engine of German sentence structure. In a two-word sentence in which one word is the object, it has to come first, it's not until you have a third element that you even have a choice."
Well, you do have a choice if German is generally VO. That's basically what it means to say a language is VO: take a verb and object and put them in that order! Your analysis only makes sense if you assume that the child using these two-word sentences puts the object and verb in the "Vorfeld" at this stage. This is not how to analyze these cases, though. When a Dutch or German kid uses a particle verb (like "opbellen" which is 'to call up') the order is O-particle-V, not O-V-particle. And when the kid starts putting in a subject, producing a three-word sentence, the order is SOV. It is only after this stage that the kid starts putting the verb in a position more to the left.
>>""Ah, the little buggers *move*, do they?"
I tried to contrast an OV and a VO analysis of German above, showing that a VO analysis with movement is much more complicated (or, extremely less likely as a correct description) than an OV analysis with movement. An analysis without movement would miss the same points as the VO analysis.
>>"But the person testing a theory on a wide cross-linguistic basis has to take the data as they are, not as the theory say they are supposed to be, or it just isn't a valid test."
If that person is a linguist interested in head parameters (like Dunn et al), that person can only hope that the constituents in the "most neutral sentence type" (a declararative main clause) are positioned in such a way that they wear the head parameter settings on their sleeve. Well, too bad. They don't. The finite verb precedes the object in main clauses but – like infinitives and participles – always follows the object elsewhere. The position of the finite verb in declarative main clauses is the exception to the rule, the rule being OV. Ignoring this for the sake of "we have to take the data as they are" must be driven by methodological ease because it is surely not driven by linguistic considerations. In addition, I don't think that many scientific fields would have progressed as much as they did by hanging on to this methodological "we have to take the facts as they are" kind of strategy. It's a first stab, at most. From where I stand, the earth looks flat. Well, too bad. It isn't.
Olaf Koeneman said,
April 23, 2011 @ 3:39 am
>>"But the comments section of a blog is not the optimal medium for a syntax lesson."
I tend to agree with you on this, but experience tells me that non-generative readers easily get the feeling that generative linguists have a completely abstract, hard to get, theory that satisfies their theoretical needs but is far removed from the data. ("How on earth can you say that German is OV! Ich liebe dich!") I want to drive the point home that (i) the theory is not at all so abstract as people think (ii) is based on very basic data (iii) saying that German is VO is in fact further removed from the data.
In fact, you could hate Chomsky, you could detest generative syntax, and still completely agree with the basics of this analysis and the conclusion that German is OV. There are thousands of linguists in this position and there is nothing incoherent about it.
[(myl) FWIW, I agree completely.]
David Bloom said,
April 23, 2011 @ 10:19 am
@Olaf Koeneman
Personally I don't think German and Dutch are VO *or* OV, but as it were weakly polysynthetic, with the O incorporated inside the verb when it is not in the separate Vorfeld-word–I think the OV-VO typology just fails, whereas with the less conservative Germanic languages the situation is syntacticalized and the typology works.
Having said that, the O-particle-V order in kids' sentences does not look like something I would have expected. How is the V marked? Does it have a person-tense suffix (Zug ab fahrt! I hope not) or is it a pidginy infinitive (Zug abfahren!), or what?
Olaf Koeneman said,
April 23, 2011 @ 10:56 am
@David Bloom:
That will entail quite some incorporating, given the size objects can take and given that indirect objects will have to behave like direct objects (two arguments incorporating?) and given that intervening adverbs will have to join the incorporation circus. This entails that German is hyper-polysynthetic. It can do what any well known polysynthetic language can only dream of. I am sorry but there is no evidence that any of this happens.
Another thing to take into consideration: the verb can precede both object AND subject in main clauses. An OVS order is certainly not wearing the setting for the OV/VO parameter on its sleeve, as the subject intervenes. If we conclude from this that the object and the verb occur in a marked position, we admit that the verb can be in a marked position in a main clause. From there, it is only a small step to saying that the finite verb in a main clause always is, also in SVO orders. The only difference is that the subject rather than the object precedes the verb.
Anyway, if there is an alternative analysis of Dutch and German to the one I am defending here, please say why it is better. OV and a displacement rule to the left in main clauses gets you the whole paradigm. That is not trivial, that is a result. So even if I cannot convince you of the fact that German and Dutch are OV, I am not going to change my mind on this before I see something better.
>>"How is the V marked? Does it have a person-tense suffix (Zug ab fahrt! I hope not) or is it a pidginy infinitive (Zug abfahren!), or what?"
They do both, although infinitives are the majority. They really treat German/Dutch as an SOV language without the movements, which is of course exactly what you would expect on an OV analysis. On the other hand, if you say that German is SVO, it means that the German child first learns all the exceptions before it learns the basic word order. That's ludicrous. It also shows you, by the way, that in order to find the basic word order, it makes more sense to answer the question "What are we going to do tomorrow?" with an object and a verb. An English person will say "Drink beer!". A Dutch person will say "Bier drinken!". As far as I can tell, this test sort of works. It is in any event much better than getting the basic order from the most unmarked sentence type (declarative main clause).
David Bloom said,
April 23, 2011 @ 6:08 pm
@Olaf Koeneman
I hope to have something ready to share within months rather than years, but I don't now. It was stupid of me to talk about it, sorry. And thanks for bringing such gusto to a discussion with an obvious outsider, this has been very enjoyable as well as instructive for me.
Olaf Koeneman said,
April 23, 2011 @ 6:31 pm
Well to be honest, you really don't know who are the outsiders and who are the insiders :) What you want to do is state your case to the insiders and be informative to the outsiders. Being argumentative on the one hand, and not sound patronizing on the other. It's difficult, I'm doing my best. And enjoying it a lot so far :)
Tunji C. said,
April 23, 2011 @ 8:44 pm
@Olaf Koeneman
Thank you for your excellent contributions. If only the journalists covering this paper had spoken with you!
Olaf Koeneman said,
April 24, 2011 @ 4:15 am
And thank you, Tunji C.! You inspired me to participate.
Simon Greenhill said,
April 24, 2011 @ 6:39 pm
Ugh, what a horrible mess of strident, ill-informed comments.
re: our characterisation of Chomsky's principles and parameters –
It is informative that none of the commentators here can agree on what Chomsky or his followers said about word order. So, what use is the theory?
re: Pavel Iosad's comment "can the results be affected by the selection of source material?"
This is a really interesting question. For the record – in the analyses we did we used all the of the data we had available – so there was no deliberate "hiding" of this variation.
Now, the method we use is based on the _rates_ of transitions between the states across the branches of the trees. So, we should get a similar result even if we haven't sampled a handful of languages/dialects that show the SAME pattern (i.e. we sample one language that had, say, prepositions and VO order, and the unsampled languages also had prepositions and VO).
We should also get a similar result if the unsampled languages/dialects show the same pattern that we detected (i.e. the sample languages show a correlation between adposition and OV order, AND the unsampled languages show the correlation too).
However, the critical part is whether this variation that we haven't sampled is _different_ to the broader pattern that we detected (i.e. a correlation exists in the sampled languages but not in the unsampled languages, or vice-versa). AND that there's enough of this contradictory pattern to refute the pattern in the rest of the data. This is possible, but I don't know how probable it is – perhaps Michael can shed some light here? – it strikes me as being quite unlikely that the sampling has missed so much contradictory variation, sufficient to over-ride what we detected. Maybe I'm wrong – but we'll have to get more data to find out.
re: Olaf Koeneman: " And to make it worse, Dutch, Flemish, Standard German, Pennsylvania Dutch and Luxembourgish are all taken to be VO languages, just like English, showing that Dunn et al. make the classical Greenbergian mistake: "Only look at main clauses""
…from our supplement:
… and:
re: Stevan Harnad:
Thank you for posting your proclamation all over the internet. My turn.
1) Evolution is a historical science by definition.
2) Sure.
3) UG would have these parameters covary perfectly. They don't.
4) Hence, the Harnard refutation of Dunn et al is not, as claimed, a refutation of Dunn et al.
re: YM:
A good question. The method we used allows a very small probability of changes
between those states occurring and being rapidly reversed. This is a very small
and improbable change, but it could happen (particularly if the data are evolving
rapidly and there's lots of time for evolution to occur).
For a bit more information about the reconstruction process see my paper here, or the Mark Pagel's 1999 paper on "Inferring the historical patterns of biological evolution" in Nature.
re: "is the rest of the data this bad too?"
The sources of the data were from the WALS database supplemented with primary grammars etc. All this information is in the supplement. Keep in mind the distinction of _dominant_ word order that we're making, following Dryer. If you still have issues with this, then a) contact the WALS people with a correction, and b) send us an email so we can rerun the analyses.
Finally – thank you to MYL for his comment:
I never thought this paper would be the end of the debate. We did the best we could with the data that were available, with the methods that were available, and with the theoretical constructs that we had available. This is not the end of the story, but hopefully a step towards a better understanding of language evolution.
FYI, the editor of the journal Linguistic Typology has dedicated the next issue to discussion of our paper. If you'd like to contribute to this debate in a more academic setting rather than slagging us off on a blog, then please do so.
Simon
Tunji C. said,
April 24, 2011 @ 9:18 pm
@Simon Greenhill
"It is informative that none of the commentators here can agree on what Chomsky or his followers said about word order. So, what use is the theory?"
Thank you for returning to the discussion, but do you really mean this strange comment the way it came out? If a bunch of Language Log commentators disagree about another linguist's views, those views are useless? I think there has been much more disagreement on this page about what *your* paper says about word order than about any Chomskyan ideas on the topic. Shall we reach the same rhetorical conclusion concerning your paper?
In the comments near the bottom of your posting, you advise us to "keep in mind" the fact that your classification scheme followed Dryer and WALS in using dominant word order as the criterion, not underlying word order (as discussed here by Koeneman for Dutch and German). Fair enough, if that's what you wanted to study.
But your paper describes its conclusions concerning dominant word order as running "contrary to the generative account of parameter setting". Now whether or not we can agree about what "Chomsky or his" (ahem) COLLEAGUES think about word order in general, I have never heard of a generative parameter-setting theory of "dominant word order".
Strikingly, your paper has not even one reference to any such proposal either. So since you're here, could you help by citing the particular parameter-setting proposals concerning dominant word order that you had in mind when you wrote your paper? Then we can intelligently discuss whether your results actually contradict those proposals, and whether or not such a contradiction would actually have wider implications for the study of language.
But if there are no such papers, you need to explain the logic by which we could possibly imagine interpreting your results as "contrary to the generative account of parameter setting" – or, for that matter, contrary to generative *anything*.
Olaf Koeneman said,
April 26, 2011 @ 3:41 am
>>"I have never heard of a generative parameter-setting theory of "dominant word order"."
Me neither, so a reference to some generative work that takes SVO main clause order in Dutch/German to reflect the head-parameter setting for the OV/VO parameter would be useful. I don't think those claims exist, and even if we are able to find a reference, it will be the odd exception. Since in generative theorizing this main clause SVO order does not say anything about the OV/VO head-parameter, the critique in the paper pertaining to this notion aims at theories that do make this claim, but that wouldn't be generative theories.
I also strongly object to the idea that "basic word order" is in this respect a theoretical claim. That suggests that taking German and Dutch to be VO languages is an empirical claim. However, the idea that the typological order is the dominant order is just as theoretical. There is no a priori reason why that would be better. And as I have elaborately tried to show above, the claim that German and Dutch are VO languages is empirically further removed from the data.
Simon Greenhill said,
April 26, 2011 @ 9:40 am
We cited Chomsky as saying that generative grammar should capture Greenbergian universals by parameter setting. Mark Baker in his book Atoms of Language went on to try and instantiate a theory of parameters drawing on this typological work. It is true that on generative theories superficial word order need not (and sometimes cannot) align with underlying word order, but the whole point of parameter theory was to capture as much of the superficial but systematic diversity as possible.
Olaf Koeneman said,
April 26, 2011 @ 9:56 am
>>"We cited Chomsky as saying that generative grammar should capture Greenbergian universals by parameter setting."
…where 'parameter setting' is a superset of 'head parameter setting'. Given the discussion above, the relevance of this difference should be obvious: Main clause SVO orders in Dutch and German do involve a parameter setting (+ verb second) but not a head parameter setting (+VO). Comparing SVO in, say, Maori with SVO in German and Dutch is comparing two completely distinct parameters, a head parameter with a non-head parameter.
Tunji C. said,
April 26, 2011 @ 9:00 pm
@Simon Greenhill
So in fact you really had no actual proposals in mind concerning "dominant word order" when you and your colleagues described your findings (concerning dominant word order) as "contrary to the generative account of parameter setting". Curious.
Even more curious (and instructive) is the set of three citations from the generative literature that you did see fit to include – as the sole citations of the supposedly opposing view in the pre-eminent science journal Nature. In your reply, you mention two of them:
1. You write "We cited Chomsky as saying that generative grammar should capture Greenbergian universals by parameter setting." This citation does not come from a technical paper – but from an INTERVIEW that he gave to two philosophers. In this interview, he devotes exactly four sentences to the topic of Greenberg universals. First, he notes that Greenberg's generalizations are less abstract than those he has just finished discussing (such as Kayne's Antisymmetry theory). Next, he notes that it would be nice to explain them ("These universals are probably descriptive generalizations that should be derived from principles of UG."). Finally, he notes that there are major research projects underway on the topic, but gives no examples.
2. You write "Mark Baker in his book Atoms of Language went on to try and instantiate a theory of parameters drawing on this typological work". This too is not a technical work. It is a POPULAR SCIENCE BOOK. I consider it a fine introduction for novices, but it doesn't "instantiate a theory of parameters" any more than Watson's Double Helix "instantiates" a theory of biochemistry. To the extent that it discusses Greenbergian word-order universals at all (which is very little – you can search the book on Amazon), the discussion mostly concerns the correlation between verb-object and adposition-object order that Jerry Friedman correctly describes as "spectacularly confirmed" in one of his comments above. The main topics of the book are quite different.
3. Finally, your paper does cite one technical work in generative grammar, Chomsky's 1981 book "Lectures on Government and Binding". However in all its 371 dense pages, that book appears to mention the general topic of word-order in exactly one paragraph, within which exactly ONE SENTENCE mentions word order universals: on p. 95, where Chomsky remarks: "Universals of the sort explored by Joseph Greenberg and others have obvious relevance to determining just which properties of the lexicon have to be specified in this manner in particular grammars – or to put it in other terms, just how much must be learned as grammar develops in the course of language acquisition". This book too can be searched on Google (your citation offers no page reference).
So there you have it. Four sentences from an interview, a few paragraphs of a popular-science book, and exactly one sentence from a technical publication, all expressing keen interest in Greenberg's generalizations and a desire to explain them, none of them discussing "dominant word order", and none of them presenting any particular proposal.
That appears to be the totality of "the generative account of parameter setting" allegedly falsified by your paper.
Now one of the commenters here expressed the view that "über-theoretical claims" like these were not the important part of your paper. I would be happy if every reader shared that opinion. But readers like the reporter for the Economist (and many others) learly came away from your paper with quite a different impression concerning the paper's take-away message. Quoting the Economist, if your paper "is correct, that leaves Dr Chomsky's ideas in tatters, and raises questions about the very existence of a language organ." I think this discussion has shown that something quite different is in tatters here – for which the appropriate remedy is, I think, a full published retraction of your "über-theoretical" conclusions. (You can fix the bit about Greek post-positions while you're at it.)
Simon Greenhill said,
April 27, 2011 @ 5:41 am
Tunji,
Are you SERIOUSLY suggesting we retract the paper for a few lines in the introduction, that have been run with in the popular press? Really??
Simon
Olaf Koeneman said,
April 27, 2011 @ 6:23 am
This is the conclusion of the paper:
"Here we have examined the paradigm example (word-order universals) of the
Greenbergian approach, taken also by the Chomskyan approach as
‘‘descriptive generalizations that should be derived from principles of
UG [Universal Grammar]’’.1,27 What the current analyses unexpectedly
reveal is that systematic linkages of traits are likely to be the rare excep-
tion rather than the rule. Linguistic diversity does not seem to be tightly
constrained by universal cognitive factors specialized for language29.
Instead, it is the product of cultural evolution, canalized by the systems
that have evolved during diversification, so that future states lie in an
evolutionary landscape with channels and basins of attraction that are
specific to linguistic lineages."
And you blame the popular press for concluding that the article is meant as an attack on Chomskyan linguistics…?!
Simon Greenhill said,
April 27, 2011 @ 6:44 am
As for Ancient Greek – We have this as postpositional, and all analyses had this coded as postpositional. See the supplement pg 12, where we reference Luraghi, Silvia, Anna Pompei and Stavros Skopeteas. 2005. Ancient Greek. München: Lincom
I believe you're getting this error from an older version of the website. There was an old version of the figure on the website for about an hour (this one), that had the preposition/postposition labels around the wrong way.
Simon Greenhill said,
April 27, 2011 @ 6:51 am
@Olaf – dear god, that was a partially parenthetical remark. You're pretty eager to shout "slander" aren't you?
Simon Greenhill said,
April 27, 2011 @ 6:55 am
& since we're all going in circles, my final word on the matter is put up or shut up. The ball is in your court – go and find some example of something, anything, that would be predicted to be a universal according to generative linguistics, and test for its existence in as many languages as we have. Go on, I'll wait.
Olaf Koeneman said,
April 27, 2011 @ 7:18 am
The Dunn et al paper claims to falsify a particular generative claim. The generativists defend themselves by pointing out that this claim does not exist in the first place. And then you say that the ball is in OUR court? I am sorry, but I don't follow this logic. Of course you can start a broader discussion (What IS universal?), but that does not qualify as an answer to our defense of course.
(About the "partially parenthetical remark": there is no way of knowing such things if they are not indicated.)
Tunji C. said,
April 27, 2011 @ 8:20 am
@Simon Greenhill
"Generative linguistics" is not a theory or something that makes predictions (any more than "chemistry" makes predictions). That's a category error. "Generative linguistics" is a loose term for an approach to studying language, a loose set of problems that certain linguists find interesting, and a community of researchers. There is no such thing as "something, anything, that would be predicted to be a universal according to generative linguistics" – and its not the job of generative linguists to supply you with such a thing.
However, there are plenty of properties that *particular linguists* have conjectured are universals, including those discussed by Chomsky in the interview that you cite, those discussed for a lay audience in Baker's book that you cite, many sections of Chomsky's Lectures on Government and Binding that you cite, and others that descend from Greenberg's Universals.
These should all in principle be testable against large numbers of languages, and to the extent that they make predictions about clusters of properties that should vary together, it should in principle be possible to test for lineage-dependent distinctions in strength of correlation. Some examples that touch on word order were already supplied in earlier comments: Greenberg's Universal 20, the Final over Final Constraint, probably others as well. Others can be found in the domain of anaphora, where it has been claimed by some researchers that the ability of particular pronominal elements to corefer with phrases in other particular positions covaries with the lexical resources for anaphora independently present in the language.
But:
1. These are particular proposals advanced by particular researchers, and studied by other particular researchers. They may or may not have logical links to other distinct proposals, but very few of them form part of a seamless web called "generative grammar" – such that if you disprove a proposal, you've done something that could be called "disproving generative grammar". You have simply done what everyone in a serious field is supposed to do: tested a hypothesis interesting enough to make it worth testing, and attempted to falsify it.
2. One practical lesson of research in generative grammar is that simply determining the facts in any single human language is hard and time consuming, requiring perseverance, intelligence and luck, like many hard problems in serious fields. Every language that has been examined in any depth, for any length of time, by capable linguists, has turned out to have "secrets", often secrets quite relevant to important and obvious questions – which have to be uncovered before the language can even be classified as, say, head-initial vs. head-final in the verb phrase. Koeneman's discussion of verb-second is one good example – and that kind of thing is the rule, not the exception. The number of languages that have been studied in this depth by even one scholar is small, and the number of languages that have been properly studied by significant communities of scholars is vanishingly small.
The WALS survey is a convenient first approximation at the facts of the world's languages (and continuing kudos to the team that put it together). But the database on which it draws is of wildly varying quality, and its classifications suffer from the compilers' failure to take into account the kinds of basic results and issues from generative research that Koeneman and others (including MYL) have discussed here. So at the very least, you should always be spot-checking the languages that make surprising results surprising – get syntacticians to look at the sources underlying the WALS data for crucial languages, don't trust the claims until you've checked their quality.
More generally, there is no reason not to ask the kinds of questions you asked about claimed universal correlations – in fact, the questions sound appropriate and interesting, and the results should be of interest to everyone in the field. But de-couple it from your war on generative linguistics. You do not have so many languages in your study, I'll warrant, that consistent misclassifications can be guaranteed to come out in the statistical wash. You need linguists who know what they are doing to ask pointed questions about particular languages in your studies. And you evidently need generative linguists to steer to you actual, as opposed to fictitious, universal claims that need testing. Why not actually communicate productively with some?
That's the conciliatory news. But as things stand at the moment, you have written and published in Nature an article that states false conclusions about a supposedly opposing theory that does not exist. You support your claim with exactly three citations, every one of which is irrelevant – two of which are not even part of the scientific literature. This error should be corrected for its own sake, simply because it is a gross error with the capacity to mislead. The error is in particular need of public correction – sooner rather than later – because it has been picked up by the press (whether your fault or not) as the "main event".
Call it a retraction, a clarification, an apology or anything you want. What matters is that it gets published and publicized. If you and your colleagues are responsible scholars, you need to do this (in my opinion). The ball is in YOUR court, and no one else's.
End of story, have the last word.
Tunji C. said,
April 27, 2011 @ 8:22 am
@Simon Greenhill
"Generative linguistics" is not a theory or something that makes predictions (any more than "chemistry" makes predictions). That's a category error. "Generative linguistics" is a loose term for an approach to studying language, a loose set of problems that certain linguists find interesting, and a community of researchers. There is no such thing as "something, anything, that would be predicted to be a universal according to generative linguistics" – and its not the job of generative linguists to supply you with such a thing.
However, there are plenty of properties that *particular linguists* have conjectured are universals, including those discussed by Chomsky in the interview that you cite, those discussed for a lay audience in Baker's book that you cite, many sections of Chomsky's Lectures on Government and Binding that you cite, and others that descend from Greenberg's Universals.
These should all in principle be testable against large numbers of languages, and to the extent that they make predictions about clusters of properties that should vary together, it should in principle be possible to test for lineage-dependent distinctions in strength of correlation. Some examples that touch on word order were already supplied in earlier comments: Greenberg's Universal 20, the Final over Final Constraint, probably others as well. Others can be found in the domain of anaphora, where it has been claimed by some researchers that the ability of particular pronominal elements to corefer with phrases in other particular positions covaries with the lexical resources for anaphora independently present in the language.
But:
1. These are particular proposals advanced by particular researchers, and studied by other particular researchers. They may or may not have logical links to other distinct proposals, but very few of them form part of a seamless web called "generative grammar" – such that if you disprove a proposal, you've done something that could be called "disproving generative grammar". You have simply done what everyone in a serious field is supposed to do: tested a hypothesis interesting enough to make it worth testing, and attempted to falsify it.
2. One practical lesson of research in generative grammar is that simply determining the facts in any single human language is hard and time consuming, requiring perseverance, intelligence and luck, like many hard problems in serious fields. Every language that has been examined in any depth, for any length of time, by capable linguists, has turned out to have "secrets", often secrets quite relevant to important and obvious questions – which have to be uncovered before the language can even be classified as, say, head-initial vs. head-final in the verb phrase. Koeneman's discussion of verb-second is one good example – and that kind of thing is the rule, not the exception. The number of languages that have been studied in this depth by even one scholar is small, and the number of languages that have been properly studied by significant communities of scholars is vanishingly small.
The WALS survey is a convenient first approximation at the facts of the world's languages (and continuing kudos to the team that put it together). But the database on which it draws is of wildly varying quality, and its classifications suffer from the compilers' failure to take into account the kinds of basic results and issues from generative research that Koeneman and others (including MYL) have discussed here. So at the very least, you should always be spot-checking the languages that make surprising results surprising – get syntacticians to look at the sources underlying the WALS data for crucial languages, don't trust the claims until you've checked their quality.
More generally, there is no reason not to ask the kinds of questions you asked about claimed universal correlations – in fact, the questions sound appropriate and interesting, and the results should be of interest to everyone in the field. But de-couple it from your war on generative linguistics. You do not have so many languages in your study, I'll warrant, that consistent misclassifications can be guaranteed to come out in the statistical wash. You need linguists who know what they are doing to ask pointed questions about particular languages in your studies. And you evidently need generative linguists to steer to you actual, as opposed to fictitious, universal claims that need testing. Why not actually communicate productively with some?
That's the conciliatory news. But as things stand at the moment, you have written and published in Nature an article that states false conclusions about a supposedly opposing theory that does not exist. You support your claim with exactly three citations, every one of which is irrelevant – two of which are not even part of the scientific literature. This error should be corrected for its own sake, simply because it is a gross error with the capacity to mislead. The error is in particular need of public correction – sooner rather than later – because it has been picked up by the press (whether your fault or not) as the "main event".
Call it a retraction, a clarification, an apology or anything you want. What matters is that it gets published and publicized. If you and your colleagues are responsible scholars, you need to do this (in my opinion). The ball is in YOUR court, and no one else's.
End of story (as far as I'm concerned).
Universal Grammar is wrong? « teflgeek said,
May 20, 2011 @ 7:41 am
[…] you'd like to know more about this, then Mark Liberman has posted a detailed review of the paper on the Language Log Blog, which has drawn some in depth discussion involving one of […]