Lyrical Narcissism?
« previous post | next post »
I've generally been skeptical of claims about counts of first-person singular pronouns as an index of self-involvement, mainly on empirical grounds. In particular, the pundits who beat this drum mostly make assertions without any counts, much less comparisons of counts. For some of the Language Log coverage, with links to articles by George F. Will, Stanley Fish, and Peggy Noonan (among others), see "Fact-checking George F. Will" (6/7/2009); "Obama's Imperial 'I': spreading the meme" (6/8/2009); "Inaugural pronouns" (6/8/2009); "Another pack member heard from" (6/9/2009); "I again" (7/13/2009); "'I' is a camera" (7/18/2009).
And there are problems with the theory as well, as Jamie Pennebaker explains here.
But look at this impressive graph, from C. Nathan DeWall, Richard S. Pond, Jr., W. Keith Campbell, and Jean M. Twenge, "Tuning in to psychological change: Linguistic markers of psychological traits and emotions over time in popular U.S. song lyrics", Psychology of Aesthetics, Creativity, and the Arts, 3/21/2011:
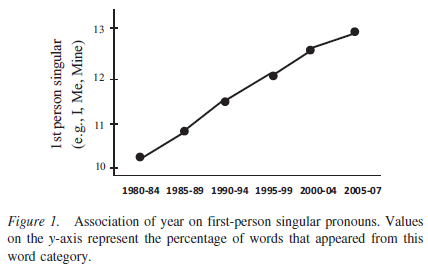
Here we've got numbers galore — from the lyrics of Billboard's 10 top songs from each of 28 years, 88,621 total words — and comparison of numbers across time. There still might be some questions about the explanation, but at least we have a strong effect to explain, right?
DeWall et al. certainly want us to draw the obvious conclusion, as they explain in their abstract:
Linguistic analyses of the most popular songs from 1980–2007 demonstrated changes in word use that mirror psychological change. Over time, use of words related to self-focus and antisocial behavior increased, whereas words related to other-focus, social interactions, and positive emotion decreased. These findings offer novel evidence regarding the need to investigate how changes in the tangible artifacts of the sociocultural environment can provide a window into understanding cultural changes in psychological processes.
The trouble is, they also give the associated table of yearly numbers:
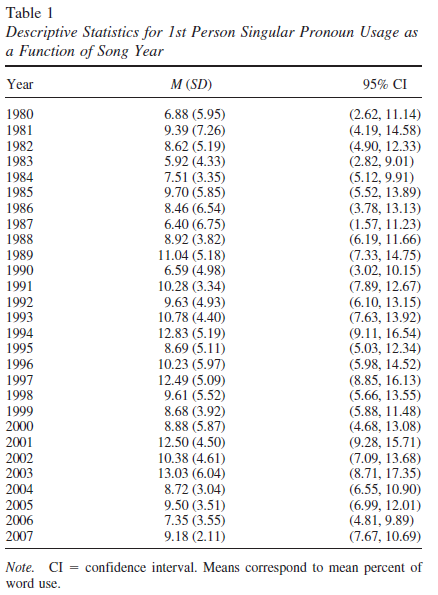
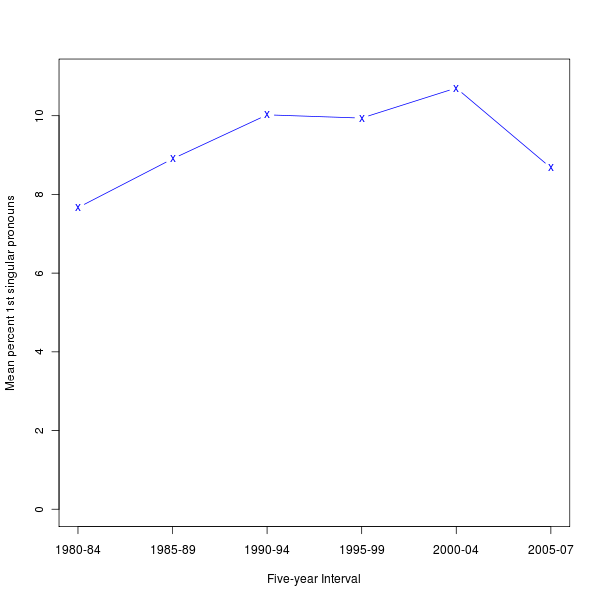
And eyeballing the numbers in that table, it's hard to see how they connect to the graph in their Figure 1. A plot of the yearly numbers agrees:

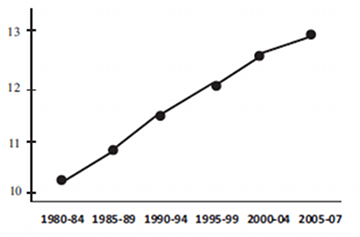
And calculating and plotting the mean values for the time-periods in their Figure 1 confirms it:

If you prefer graphs where percentage axes start from 0, see here and here. Here's an adjacent comparison to the DeWall et al. graph, with similar sizes and aspect ratios:
{kind=link}
{kind=link}
 |
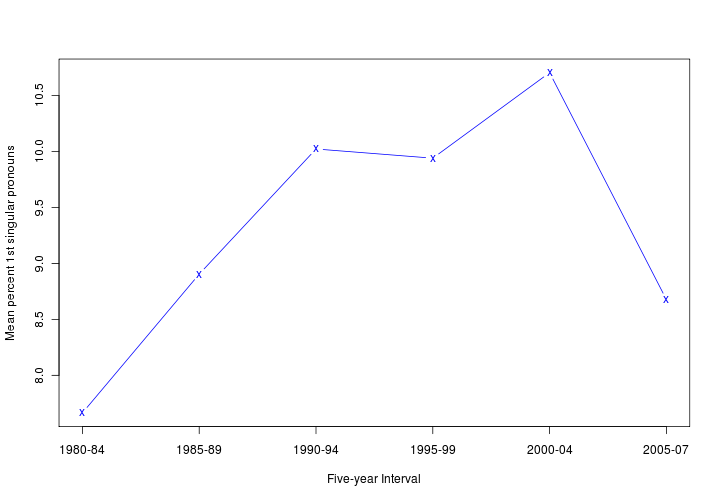 |
What gives?
Frankly, I'm not completely sure. It seems that their Figure 1 in fact plots numbers that are not derived directly from their Table 1, but rather from a regression analysis somewhat vaguely described as follows:
To provide a conservative test of our hypothesis, multiple regression analyses were conducted for each dependent variable, predicting word use from song year. Dummy variables for genre type (i.e., country, hip hop/r&b, pop, and rock) and changes in methodology (i.e., changes in ranking formula to account for digital downloads and streamed media) were entered as covariates.
The results for first-personal pronouns:

In other words, they apparently fitted a line (probably to the logit transform of the yearly first-person-singular-pronoun proportions), and plotted the fitted time-period proportions rather than the actual proportions. If that's true, then it seems to me that their Figure 1 is superfluous at best and misleading at worst.
Still, it looks like there's some change over time in the actual proportions, even if it's noisy and non-monotonic. What caused this? Is it showing us something about the overall expression of self-involvement in American culture over time?
We should start by getting specific about where they got their data:
To explore changes in word use in popular songs over time, we obtained song lyrics for the 10 most popular U.S. songs (according to the Billboard Hot 100 year-end chart) for each year between 1980 through 2007. We chose this time period because prior work has shown significant cultural changes over time in motivation, personality, and emotion (e.g., Twenge, 1997; Twenge & Campbell, 2001, 2008; Twenge & Foster, 2010). The top 10 songs were chosen because of the preponderance of Top 10 lists that identify popular cultural products (e.g., foods, presents), including songs.
The first thing that occurred to me was that (noisy and non-monotonic) trends might (partly or mainly) reflect some changes in the relative popularity of musical genres and even individual artists. DeWall et al. consider and reject this alternative, as follows:

The results for the genre variable (which they give as correlations rather than as logistic-regression coefficients):
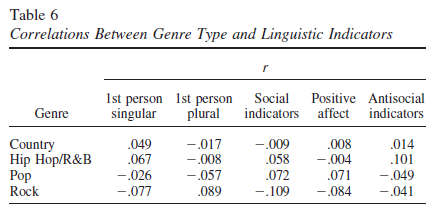
This is not at all convincing, in my opinion. All four categories are highly diverse, in ways that change significantly over the time the time period of their study. The category of "Hip Hop/R&B", as the slash suggests, is especially diverse, and also has changed especially strongly over the period from 1980 to 2007. At one end, this category includes Michael Jackson, Diana Ross, Lionel Richie, Kool & the Gang, Prince, and Tina Turner (representing the Hip Hop/R&B genre in the top 10 of the Billboard Hot 100 for 1980-1984), and 50 Cent, R. Kelly, Sean Paul, Jay-Z, Chingy, Ludacris, Usher, and P. Diddy (representing the same genre in the top 10 of the Billboard Hot 100 for 2000-2004). A variable that doesn't distinguish between these two lists is hardly controlling effectively for genre differences.
The idea of data-mining song lyrics for indications of cultural trends is a plausible and interesting one, in my opinion. But this particular study uses misleading graphics to exaggerate its findings, and does a remarkably tone-deaf job of controlling for genre changes.
Update — Cosma Shalizi writes:
Inspired by your post on DeWall et al., I typed in the confidence intervals as well as the means, and added (1) a horizontal line at the grand mean, (2) a smoothing spline (blue), and (3) a smoothing spline with points inversely weighted by standard deviation (purple). Code and graph attached.
They probably cite Colin Martindale approvingly, don't they?
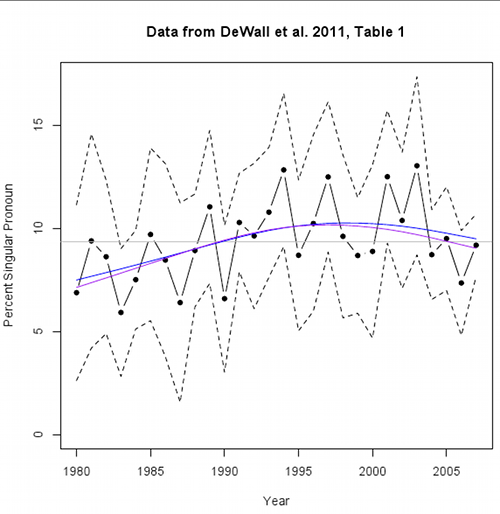
Cosma's R code is here. For those who aren't familiar with Colin Martindale, who died in 2008, here's Dennis Dutton's review of The Clockwork Muse, and Cosma's less positive evaluation.
D said,
April 9, 2011 @ 6:25 am
So basically they have (maybe) shown an increasing popularity of first person narratives. It takes a pretty heavy infatuation with your own pre-existing ideas to draw the conclusions they did from that.
Also, the "I" in these songs isn't necessarily the song author. Did they make any attempt to distinguish between artists singing about themselves and from the point of view of another character?
a George said,
April 9, 2011 @ 7:04 am
"Never look a gift horse in the mouth"; an opposite would be that you appreciate more what you have paid for. In this case, the publisher has seen to it that you appreciate the paper, because it costs to download! Thank you myl, for providing a Consumer's Report on the content so that we may avoid this until it becomes free! Sadly, many sociologists are so awed at having a corpus at hand that they dash off wildly in all directions and draw many conclusions that are entirely out of context. Another good example is the use of patent statistics to prove the development of inventiveness over time. To sociologists this means getting all that lovely well-documented material under their belt. Professionals in the field raped by the sociologists run out of head muscles for shaking the head. However, there is always the hope that nobody tries to base politics on the sociologists' conclusions.
Bruce Rusk said,
April 9, 2011 @ 7:37 am
So many confounding variables. Does this corpus represents the same thing in different periods? The market for music has changed greatly over the past few decades, and which demographic groups this music's popularity reflects may have changed. Might the sentences in popular songs have grown shorter, so that while the percentage of tokens that are first-person singular pronouns increases the percentage of sentences containing them does not?
Dierk said,
April 9, 2011 @ 8:34 am
"tis sixty years since …'
A professor of mine used this line from Sir Walter Scott's Waverley to define the time that has to pass before we start analysing what happened then [put another way: It takes 60 years until it's history.] because we do not have the necessary distance to the subject before. While I tend to agree that the time frame from the mid-50s to the mid-70s exhibits a lot of social and especial [pop] cultural change, it is far from clear if the 30 years since 1980 haven't seen the same.
Clearly their personal experiences lead them to define 1950-1980 as structurally different from 1980-2010 without any good evidence for that.
BTW, what exactly does it prove – assuming their numbers do actually pan out as they like to – apart from the fact that first person pronouns are used?
Steve Kass said,
April 9, 2011 @ 9:08 am
Mark,
I didn’t read the full paper, so I’m making some assumptions from what you give here. But I don’t think this is a good start at analyzing what might be interesting data to analyze.
The raw data for the left column on Table 1 was, I assume, percentages (of I/me/my words in the full lyrics), one percentage per song, for the top ten songs per year, according to Billboard. The authors give no justification for using only these ten songs to analyze “word use in popular song lyrics.” They say “The top 10 songs were chosen because of the preponderance of Top 10 lists that identify popular cultural products (e.g., foods, presents), including songs.” (When N=10, less statistical analysis is often more.)
That has to be among the top 10 worst reasons for selecting data to analyze.
Data should be as representative of what you’re studying as possible. We have corpora, don’t we? Or they should clarify that their research concerns word usage specifically in songs that enjoy extraordinary success. (“What kind of lyrics are associated with being a megahit?”)
Using the mean instead of the median seems wrong. A single song with a huge number of I-Me-My in some year shouldn’t lead us to think that word use in popular song lyrics in that year is more me-ey to a greater degree than when there’s one song with a big-but-not-huge number in that year (other songs that year being equally me-ey). With N=10, the median is extremely sensitive to changes in a single outlier.
The standard deviations of the data, whatever it is, are high (not surprisingly), and if you were to graph Table 1’s data to show the bounds of the middle 50 percent of the data, it would be telling (perhaps that there is not much going on here). It’s hard to imagine that there is much statistical significance to the vague 1980-2000 trend in medians, if it’s considered up to 2007 and the large standard deviations are accounted for.
As far as I can tell, the column labeled “95% CI” is not 95% anything, nor is it a confidence interval. It looks like the interval that would contain 50% of the data from a normal distribution with the same mean and standard deviation as the experimental data. I’m not sure why we care about that.
Another argument against using the mean and SD is that the data isn't normally distributed (almost surely not). The large standard deviations are a hint, the actual data is bounded below at zero, which is only 2-3 SDs below the mean in most years, and the nature of song lyrics – not a continuous spectrum of sentiments or genres – suggest non-normal data.
A scatterplot would have been more interesting to look at, and especially if more songs were analyzed. A very interesting premise, I think, but very poorly executed.
Sili said,
April 9, 2011 @ 9:13 am
What's up with their graph? Has it been drawn by hand?
The line goes from the bottom of the first point to the middle of the second, then middle to top, (not quite) top to top, (not quite) top to middle, and (not quite) top to bottom. What a mess.
[(myl) I wondered about this point myself. ]
copperykeen said,
April 9, 2011 @ 9:56 am
Deliberate reference on the vertical axis to the George Harrison Beatles song?
Spell Me Jeff said,
April 9, 2011 @ 10:03 am
Do I understand the logic correctly?
Imagine that the top ten songs of every year over the last 30 years are in fact variations of the same song, whose only lyrics are "I love you, and you love me" repeated over and over. Now imagine that the number of times this simple verse is repeated increases over time. It follows that the usage of the words "I" and "me" likewise increases. It would follow, then, that during this time frame
Yet I flatly reject the notion that "I love you, and you love me" reflects self-focus and antisocial behavior.
[(myl) In fairness, their evidence for the "antisocial behavior" part comes from time-functions of other measures (1st-person-plural pronouns, "positive emotion" words, "social indicators", "positive affect indicators", "antisocial indicators" — all from the LIWC program.).
And simple repetition within a song shouldn't matter, since their starting point is song-wise proportions.]
Spell Me Jeff said,
April 9, 2011 @ 10:06 am
@copperykeen
I was thinking that also. The irony being that George's song is written from a POV that rejects self-focus. Where in this study is any sense of context?
David L said,
April 9, 2011 @ 10:09 am
"I'd like to teach the world to sing…"
Another one of those awful self-focused, antisocial songs.
Mr Fnortner said,
April 9, 2011 @ 10:11 am
It would be interesting to see whether a similar analysis of 2nd person and 3rd person pronouns gives a similar trend. Is pronoun use in general increasing (not acknowledging that 1st person pronoun use is increasing).
Felix said,
April 9, 2011 @ 10:52 am
Even if the graph and methodology were right on, their assumption that the lyric content changes reflect changes in thinking seems straight up dumb. Another theory though, if there is a change in 1st person pronouns, is that the racial integration of the previously homogenous pop charts has broadened allowable themes in pop songs.
Hasn't a lot of work been done on culture, ethnicity, race, and communication? To speak in broad generalities, white culture views "bragging" as negative, while certain kinds of positive or competitive self-descriptions are not viewed with the same negative connotation within mainstream black culture. So contemporary hip hop allows for more, "I'm good at x" or "I've got y" because it's just more culturally acceptable to say these things within some cultures than others?
[(myl) Without engaging any broader cultural issues, it's fair to say that there are some influences of battle rap in some lyrics — though that seems to be thought of as "old school" these days.. But there've been plenty of boastful white guys in the history of American music — it's not clear to me that there's a qualitative difference between battle-rap boasting and (say) Bob Wills' "I'm a ding dong daddy from Dumas, baby", which Louis Armstrong famously refused to sing, reverting to scat and claiming that "the music fell off the stand".
The strong tradition of over-the-top self-promoting blowhards in white American culture is epitomized by the verbal battle between Bob and the Child of Calamity — both white — in Mark Twain's Life on the Mississippi. Bob starts off with
"Whoo-oop! I'm the old original iron-jawed, brass-mounted, copper-bellied corpse-maker from the wilds of Arkansaw!–Look at me! I'm the man they call Sudden Death and General Desolation! Sired by a hurricane, dam'd by an earthquake, half-brother to the cholera, nearly related to the small-pox on the mother's side! Look at me! I take
nineteen alligators and a bar'l of whiskey for breakfast when I'm in robust health, and a bushel of rattlesnakes and a dead body when I'm ailing! I split the everlasting rocks with my glance, and I squench the thunder when I speak! Whoo-oop! Stand back and give me room according to my strength! Blood's my natural drink, and the wails of the dying is music to my ear! Cast your eye on me, gentlemen!–and lay low and holdyour breath, for I'm bout to turn myself loose!"
The Child responds:
"'Whoo-oop! bow your neck and spread, for the kingdom of sorrow's a-coming! Hold me down to the earth, for I feel my powers a-working! whoo-oop! I'm a child of sin, don't let me get a start! Smoked glass, here, for all! Don't attempt to look at me with the naked eye, gentlemen! When I'm playful I use the meridians of longitude and parallels of latitude for a seine, and drag the Atlantic Ocean for whales! I scratch my head with the lightning, and purr myself to sleep with the thunder! When I'm cold, I bile the Gulf of Mexico and bathe in it; when I'm hot I fan myself with an equinoctial storm; when I'm thirsty I reach up and suck a cloud dry like a sponge; when I range the earth hungry, famine follows in my tracks! Whoo-oop! Bow your neck and spread! I put my hand on the sun's face and make it night in the earth; I bite a piece out of the moon and hurry the seasons; I shake myself and crumble the mountains! Contemplate me through leather–don't use the naked eye! I'm the man with a petrified heart and biler-iron bowels! The massacre of isolated communities is the pastime of my idle moments, the destruction of nationalities the serious business of my life! The boundless vastness of the great American desert is my enclosed property,and I bury my dead on my own premises!"
They go on at some length, until a quiet "little black-whiskered chap" gets tired of their noise and whups both of them. ]
Felix said,
April 9, 2011 @ 10:53 am
That is such a good point! This study seems meaningless without that analysis.
Felix said,
April 9, 2011 @ 12:08 pm
Great story!
And of course I agree boasting is all over the place. Just thinking about the basic premise that there is something inherently negative about talking about oneself (an idea that is not universal).
kuri said,
April 9, 2011 @ 12:39 pm
Hmm. I wonder why it is that R&B and hip-hop are a single category. And I wonder why Michael Jackson, Diana Ross, and Lionel Richie are in that category along with 50 Cent, R. Kelly, Sean Paul, etc., instead of the "pop" category. I can't imagine what the deciding factor could have been.
Felix said,
April 9, 2011 @ 12:48 pm
OK, wait a sec. I didn't say white people don't boast, nor do I believe that to be the case. I did say that speaking generally, boasting has a less negative connotation in black cultural groups than in white ones. I believe this idea is supported by various researchers and I think it's worth exploring because there's a value in noticing that there are different sets of values in human culture and recognizing that one set of values is not necessarily more right than any other. If this generalization can be made accurately, I can't prove that it is reflected in song writing patterns across various racial groups, but I can guess that it might be – when looking at overall trends rather than individual anecdotes.
I can't speak with any authority about whether a) there are actual changes in how many "I statements" are made in pop music now vs. 20 years ago or b) why that might be the case, but I was hazarding a guess based on my belief that the pop charts have become more racially integrated in that time, that if there is a difference it may relate to that changing demographic. I am not a linguist, a communication specialist, a musicologist, a statistician, or any other kind of expert on any of these topics. Just a curious person.
Harold said,
April 9, 2011 @ 1:38 pm
Pop psychologists tell us that "I statements" are less threatening than you statements (such as "you ought"), because a person is speaking from his or her own experience.
ShadowFox said,
April 9, 2011 @ 2:44 pm
There is something funny about the original graph. The underlying graphic might have come from a spreadsheet (no way to tell which) or a statistical package, but the overlaying connecting lines most certainly did not. They look sloppy and unprofessional–as if someone tried to add them to the graph in MS Word graphics to make the trend appear more obvious. This makes me wonder how they were manipulating the time series. Certainly, Excel and any other package has a simple feature to add lines to any time-series graph. It is all too common for non-proficient researchers to throw the numbers into a statistical engine and produce meaningless regressions without having a clue about what it is they've just analyzed. I am not stating, as a fact, that this is such a case. But it looks awfully suspicious.
Content Analysis of Pop Lyrics for Cultural Narcissism « Permutations said,
April 9, 2011 @ 4:27 pm
[…] Analysis of Pop Lyrics for Cultural Narcissism Mark Liberman, over at Language Log, is discussing a content analysis of pop lyrics. Are trends in cultural narcissism picked up by the changing frequency of first-person pronouns? It […]
Michael M Bishop said,
April 9, 2011 @ 4:35 pm
I tried to do a similar analysis using google ngrams… written up here: http://permut.wordpress.com/2011/04/09/content-analysis-of-pop-lyrics-for-cultural-narcissism/
Harold said,
April 9, 2011 @ 4:44 pm
I think it would be more meaningful if such an analysis took into account other factors, such as whether is a single singer, or ensemble, and the manner of organization of same. And if it were also correlated with other societal factors, as Alan Lomax did in his Cantometrics research.
http://research.culturalequity.org/psr-history.jsp
[(myl) Indeed. In a related point, Michael Ramscar observed in email that
]
Harold said,
April 9, 2011 @ 4:47 pm
"I am a poor wayfaring stranger" — "If I had wings like Nora's dove" American folk lyrics have always been rather individualistic, no? Does that constitute "narcissism", necessarily?
kenny said,
April 9, 2011 @ 5:46 pm
I wonder if there's also a trend away from storytelling, third-person songs. If that should be the case, then we would also see an increase in the number of second-person pronouns (which some overeager interpreter could just as easily say indicates that Americans are experiencing an upward trend in how much they care about others).
Rubrick said,
April 9, 2011 @ 5:46 pm
As expected, year was positively associated with first-person singular pronoun use…
I hereby propose two changes to the way research is conducted and peer-reviewed:
1) Any paper which contains that horrible phrase "as expected" should be rejected out of hand. It seems intended to convey "We were right! Aren't we such clever hypothesis-formers!", which is bad enough. To me it says "We were determined to find a particular result, and by gum, we found a way to make it happen!"
2) Data analysis should be performed by a neutral third party, with the data being blinded. "Here are counts for some variable y with respect to some variable x. Perform the appropriate regression analyses, etc., and generate graphs that most clearly represent whatever acutal trends may be present in this purely abstract data."
Fat chance on 2), of course; what's in it for the analyst? Is it fee-for-service, like a DNA lab? Why would a researcher pay someone else to do the analysis when they can do it themselves and greatly improve the chances that the results will reflect their clever hypothesis?
Turning my cynical eye elsewhere: I'm intrigued by this list of "words related to self-focus and antisocial behavior" which forms the basis of the whole result. Does the paper include the actual list, and citations for the studies which show that they do correlate with actual anti-sociality? Were these studies conducted with song lyrics as the corpus? If not, is there at least good reason (read: evidence) to suppose that song lyrics obey similar principles to whatever corpus was used?
It irks me that so many researchers in the socio/psych world don't seem to grasp the fundamental fact that doing real science is hard.
Or perhaps the authors of this paper do understand that they're not doing real science, given the incredibly wishy-washy abstract. "These findings offer novel evidence regarding the need to investigate how changes in the tangible artifacts of the sociocultural environment can provide a window into understanding cultural changes in psychological processes."? Pleh.
Julie said,
April 9, 2011 @ 6:38 pm
I did a rough visual count of this post and the comments, and counted 29 uses of the words "I" or "me" (not counting quotes and mentions). Of those, about 25 are used to express doubt or humility. "It seems to me that…." "I'm no expert…."
So what was that about narcissism?
[(myl) Yes; see James Pennebaker's discussion of this issue here.]
Ryan said,
April 9, 2011 @ 7:28 pm
The problem with using covariates in data analysis is that you need the variable of interest to be the same across groups. That is, say you are studying differences between incarcerated offenders and college students, but, unsurprisingly, the college students, on the whole, are smarter, which could cause any differences you observe in your study instead of what you're actually interested in studying (e.g., levels of antisocial behavior). Unfortunately, what a large part of the scientific field would do in this case is enter intelligence in as a covariate and claim that intelligence is now statistically controlled for. Due to the between groups differences in intelligence, however, this doesn't work: you risk removing variance not only due to intelligence but also antisocial behavior. This is because intelligence and antisocial behavior are probably linked–you didn't get that difference by chance, there are systematic reasons why intelligence and antisocial behavior would covary within both groups.
This means that if there are systematic reasons why first-person pronouns would vary across genre (seems plausible), it shouldn't have been used as a covariate. Instead, analyses should have been carried out separately within each genre. While any quantitative psychologist worth their tenure would be able to tell you this, it hasn't caught on everywhere yet and especially not in social psychology. On the other hand, the correlations of genre with 1st person pronoun posted here all look small. Of course, if, as was mentioned, the genre categories used are highly heterogeneous, then you would expect the correlations to be small and you haven't really controlled much.
I heard Jean Twenge speak at a conference recently. She's made quite a name for herself doing these kinds of studies that are high on appeal but low on rigor. Perhaps unsurprisingly, then, she actually spoke about a forthcoming project testing these same hypotheses using Google's ngram project. In defense of psychology, I would say that her work is not at all representative of research in the field.
GeorgeW said,
April 9, 2011 @ 7:51 pm
Felix: Differences in boasting by Whites and African Americans has been examined by researchers. Fought ("Language and Ethnicity"), as an example, discusses this. With respect to African Americans, she says," . . . boasting which is distinguished by its exaggerated quality is generally seen as just for fun, and not objectionable." She cites examples of Muhammad Ali who was famous for his exaggerated boasts.
She also talks about topics about which boasting is not considered appropriate by African-Americans such speaking about one's possessions or financial success, "although in the subculture of rap artists this rule is clearly suspended."
Harold said,
April 9, 2011 @ 8:46 pm
Phrases like "I'm no expert" communicate a non-hostile, non-aggressive intent, necessary when communicating with strangers rather than intimates. Another feature of modern music widely heard today is the Spracht -stimme or almost spoken (or shouted) vocal style, indicating suspicion, since it takes trust and relaxation to open up and be tuneful or lyrical. Thus, American musical style continues to express displacement and alienation as it did in 1910, when Puccini in his opera, the Girl of the Golden West, had the folksinger Jake Wallace sing to the gold miners about how much he missed his mother and his dog.
maidhc said,
April 10, 2011 @ 1:49 am
So "The Man Who Shot Liberty Valance", "Secret Agent Man", "Stagolee" and "Bad Bad Leroy Brown" are not evidence of anti-social attitudes, but "If I Had a Hammer" is?
brian said,
April 10, 2011 @ 10:07 am
Further to what Mr Fortner said, shouldn't the variable of interest have been the difference between the proportions of I and we pronouns in each song, not just the proportions themselves?
[(myl) They did that:
]
And @myl, re: the Mark Twain quote: those two guys sound pretty tough, but they've neither of them got nothing on Chuck Norris…
Mr Fnortner said,
April 10, 2011 @ 10:42 am
Something that should help would be context. If disinterested coders would evaluate the intent of the 1st person pronouns in the clauses they occur in, as to positive, neutral, or negative (based on decent criteria), their researchers would be better able to do the analysis they want to do. There is a substantial difference between intents in the following lyrics, for example:
I can only give you love that lasts forever….
If I had a hammer I'd hammer in the morning….
But I shot a man in Reno, Just to watch him die….
Harold said,
April 10, 2011 @ 1:12 pm
"My name is Captain Kid, damn your eyes, damn your eyes,
My name is Captain Kid, damn your eyes,
My name is Captain Kid and most dastardly I did,
And God's laws I did forbid,
Damn your eyes."
Don't believe the hype!
Harold said,
April 10, 2011 @ 1:33 pm
See also "Sam Hall"
http://www.mudcat.org/thread.cfm?threadid=76056
Actually, rap expresses aggression but in a playful way. The fact is that it comes out of an underworld subculture where it's purpose was to diffuse aggression (i.e., maintain social concord), so scholars tell us.
See wikipedia: The Dozens
http://en.wikipedia.org/wiki/The_Dozens
The Dozens is an African-American tradition but there are analogous boasting games in underworld subcultures all over the European world (and probably Asia). One thinks of various insulting toasting and roasting games in bars and other male locales of masculine entertainment.
a George said,
April 10, 2011 @ 4:02 pm
Context is everything, not only in popular music. If you really want to assign correct categories to the various uses of the first person singular, you need to go about it very carefully. Why do you want assign unambiguous categories? Because that is the pre-requisite for any statistical treatment. Think of the mess if red balls were sometimes indistinguishable from white balls.
As an example, take the analysis of the meaning of the word "here" by Alan F. Moore, in: 'Where is Here? An Issue of Deictic Projection in Recorded Song', Journal of the Royal Musical Association, 135: 1, 145 — 182 (2010)
"This article develops a theoretic base for the hermeneutics of spatialization in recorded popular song, drawing from work in ecological perception, cognitive linguistics, proxemics and some music semiotics. It uses this base in order specifically to observe a range of uses of the deictic expression ‘here’ in the lyrics of popular songs, and from this observation to construct a typology. It draws from a very wide range of Anglophone genres, stretching across most of the previous century and beyond, exploring the varying extents to which the music that encompasses such lyrics helps to fix a type of location indexed by ‘here’. Such an exercise forms part of a larger programme to establish a grounding that permits a reasoned response to Ricoeur’s call to interpret the text by means of disclosing a ‘possible way of looking at things’."
Any old "here" simply won't do!
KevinM said,
April 11, 2011 @ 3:31 pm
Did the program pick up Cielito Lindo ("Ay, ay, ay, ay")?
Would it pick up politicians' synonym for the first-person singular (such as "we" and "Bob Dole")?
Measuring trends in narcissism using song lyrics, again « Permutations said,
April 26, 2011 @ 12:00 pm
[…] discussed. The short story is that there are problems with the data analysis, demonstrated by Mark Liberman's post. I showed that books don't show the same pattern published in the original […]
Another Antisocial, Sapphic Love Song | Bark said,
May 6, 2011 @ 6:10 am
[…] things to say about this research, and Mark Liberman at the Language Log does a great job at shooting it down. While I'm no academic, I would like to step in and defend pop music's first person […]
Lyrics, Dude… Part 1 | The Trait-State Continuum said,
July 31, 2012 @ 12:17 pm
[…] 1. The tables and figures don’t match. This issue is well described here: http://languagelog.ldc.upenn.edu/nll/?p=3080 […]