In defense of Amazon's Mechanical Turk
« previous post | next post »
I can find no better description of Amazon's Mechanical Turk than in the "description" tag at the site itself:
The online market place for work. We give businesses and developers access to an on-demand scalable workforce. Workers can work at home and make money by choosing from thousands of tasks and jobs.
This is followed by a "keywords" meta tag:
make money, make money at home, make money from home, make money on the internet, make extra money, make money …
This makes the site sound a bit like the next stop on Dave Chapelle's tour of his imagined Internet as physical place, and indeed it does have its seamy side. But I come to defend Mechanical Turk as a useful tool for linguistic research — a quick and inexpensive way to gather data and conduct simple experiments.
This post is long, so here's some help with navigation:
1. An experiment
My fellow Language Logger Dan Jurafsky was the first to tell me about the service. He emphasized that it worked best for quick, simple tasks. Recently, I had just the thing: I wanted to learn more about the pragmatic effects of attaching an intensive like absolutely, totally, or damn to positive and negative adjectives of various strengths. It is clear that superb and horrible are emotively positive and negative, respectively. What about totally superb and totally horrible? We have a lot of evidence from online product reviews about what the intensive signals, but the reactions to this evidence are sometimes skeptical. People worry about the specialized form of the reviews, the reliability of the meta-data, and so forth. Fair enough. This looks like a job for the Mechanical Turk.
Step 1: Data prep I extracted from the UMass Amherst Linguistics Sentiment Corpora all the words with particular distributions across the five-star rating categories. Intensives appear mainly in the one-star and five-star reviews, distributed equally in those extreme categories. Emotively positive adjectives typically correlate with the rating categories, rising steadily in frequency from one to five stars. Emotively negative adjectives like horrible correlate inversely with the rating categories, falling off steadily from one to five stars. And words like but, quite, and somewhat are largely confined to the middle of the rating scale.
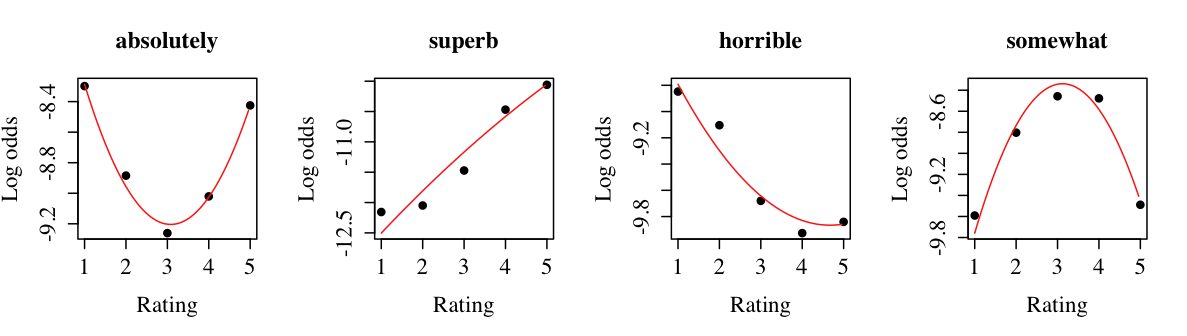
Step 2: Data format I combined a subset of the intensives with a subset of the positive and negative adjectives to form phrases like totally superb and totally horrible. I put these in a list with the unmodified adjectives, threw in some fillers like possibly superb and quite, shuffled them up, and put them in a file, one phrase per line:
phrase wow mostly fairly superb absolutely helpful ...
The first row gives the name of the column. (There can be multiple, comma-separated columns, each with its own name.) I had 43 phases in all.
Step 3: HIT design I used the Mechanical Turk Web interface to create my basic Human Intelligence Task (HIT) design.* Here's what it looked like:
Assessing emotivity
Please read the following word or phrase and assess its emotivity on the scale provided:
${phrase}
+3 Highly emotively positive +2 Emotively positive +1 Somewhat emotively positive 0 Not emotive -1 Somewhat emotively negative -2 Emotively negative -3 Highly emotively negative
The ${phrase} piece is a placeholder for the phrases in my list. When I clicked "Publish", Mechanical Turk created 43 HITS of this form, one for each value of ${phrase} drawn from my input data file.
I requested 50 assignments for each of my 43 HITs, for a total of 2150 jobs. I was paying $0.01 for each HIT, and Amazon tacks on a surcharge, so the total cost for this was $32.25 ($21.50 + surcharge). I paid this amount to Amazon (it's just like buying a book from them). When I published my HITs, the $32.25 disappeared from my account. Amazon pays the workers.
Step 4: Wait a few hours I sat back and waited for my results. The first time I requested a batch of HITs like this, I thought I would have all the results in a week or so. That time, I had them in two hours. (It was a Friday afternoon.) I had to wait about five hours for all of the above to come in. When I have asked workers to do more intricate things like provide text, the results have come at a slower pace, but they've always finished in a few days.
* The command-line tools work well, but the styling options seem to be more limited than those provided by the Web interface, which is also easier to deal with.
2. Results
The results suggest that, true to their label, intensives intensify. Here's an example involving the strongly positive modifier awesome:
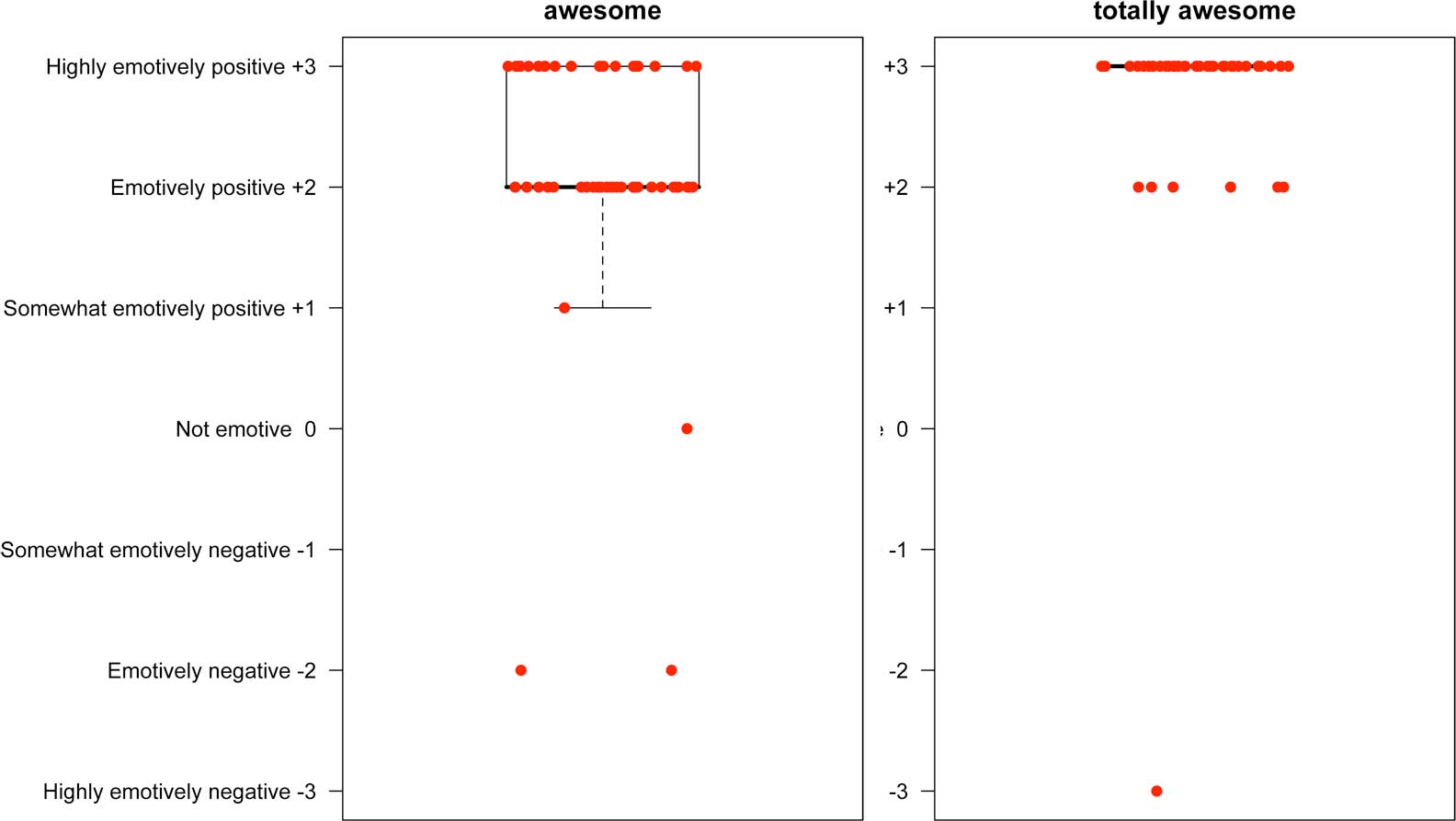
This is a box-and-whisker plot, but with the individual data points displayed (jittered left and right so that they don't sit atop each other). The thick black lines are the median values. The box picks out the core of the response data. For the intensive versions, the box has collapsed and the median line is almost hidden; essentially all the responses were at the very top of the positivity scale.
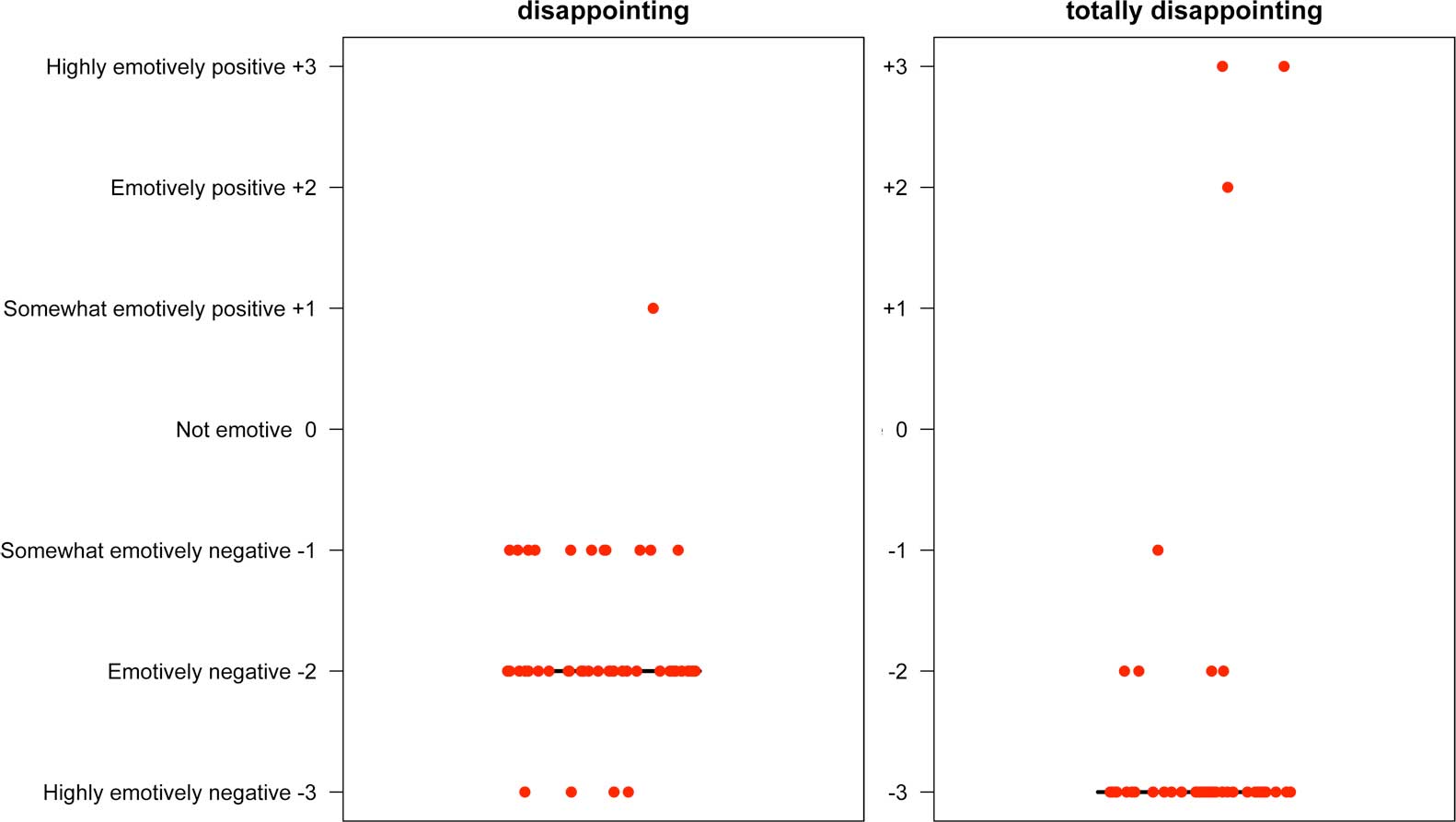
With negative adjectives, the effect is largely the same, but on the negative end of the scale. Here is a look at disappointing, which has less variation than awesome when unmodified but which an intensive can push all the way to the extremes.
For adjectives like superb and horrible, already extreme in their own right, the picture is slightly different, but still very much in line with the notion that intensives push scalar predicates further along their scale:
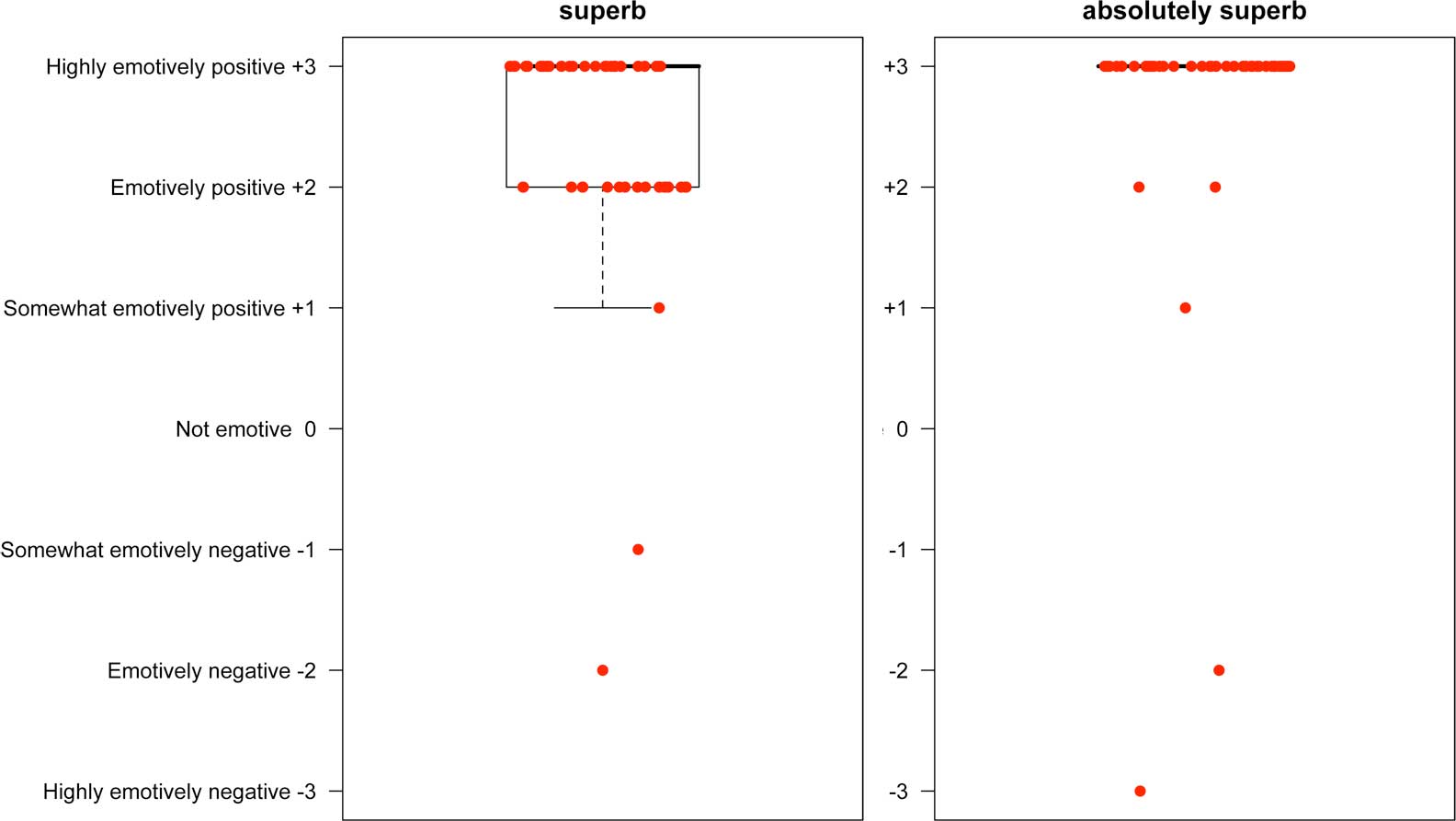
Here, the median values of both are at the highest point on the scale. But the intensified version is less likely to stray below this point.
All these results are completely in line with the U-shape for intensives seen above: sometimes it combines with positive adjectives, sometimes with negative ones. In both cases, it pushes the sentiment out to the extremes.
3. Assessment of Mechanical Turk
One might say that this is not an especially surprising result. I agree. If the results had been too surprising, I'd have lost faith in Mechanical Turk. The role these results play in my research is to fill a small empirical hole. It's important to have it filled, and it would have been difficult and/or costly to fill it with a normal experimental set-up at my university.
I've found the Mechanical Turk workers to be conscientious on the whole. I've gotten a few messages from them. One was having trouble with the buttons (I promptly blamed Amazon), another had misentered his intended choice, and a third had a question about what I was after.
Overall, the workers are incentivized to do well. It is possible for requesters to approve/disapprove their work, and one can limit one's HITs to workers at or above certain approval thresholds. Thus, doing well leads to higher approval ratings, which opens up more and better jobs to them.
As a result of this, workers are highly likely to try to model the requester's expectations. If you display an image, they are likely to try to describe the whole image if given the chance, because they are likely to assume that you are doing image annotation. If your instructions reveal that you are after a particular effect, they are likely to strive for it. Similar factors threaten regular psycholinguistic experiments too.
If you look back over the above plots, you see outliers. It happens that some of these are the same people over and over again; each data point has a worker ID attached to it, so it is easy to identify these outliers. These might be non-native speakers, trouble-makers, people with unreliable browsers, etc. They can be dealt with separately. Again, one has to make similar moves in the lab, e.g., for people who claim native competence in language X and then turn out to be struggling with their first classes in X, for people who go on auto-pilot two-thirds of the way through the experiment, etc.
So my considered view is that Mechanical Turk is a useful tool for language researchers, and that it can only become more useful if we exchange notes on our experiences with it.
Lukas Neville said,
March 15, 2009 @ 10:48 am
I've seen MTurk used for research by people in industry or 'independent scholars', but this is the first time I've read about a university-affiliated researcher using it.
Can you say a word or two about your IRB or REB's response to the project? How do you deal with the usual informed-consent requirements?
Aviatrix said,
March 15, 2009 @ 11:29 am
Is there any problem with the sampling when it's taken from the set of people who register to do odd jobs over the internet? I imagine it's more diverse than the set of white college-aged males who could afford to go to university that was used for years in studies. I would be afraid of having the sample skewed heavily towards youth and non-native English speakers.
Chris Potts said,
March 15, 2009 @ 12:37 pm
Lukas Neville wrote:
I've not confronted this yet, though it has been on my mind. So far, I've paid for the experiments with my own money, and I've not published using them (until this posting, anyway). Here's a link to a thoughtful discussion:
Mechanical Turk, Human Subjects, and IRB's
I expect my IRB also to be interested in whether the wages are fair. And, if they consider the workers to be real workers — subcontractors of some kind — then they will be concerned about who they work for and which countries they are in. It could be rather an ordeal. When I get further along with this process, I'll write about it on Language Log.
Bobbie said,
March 15, 2009 @ 12:59 pm
Why is is called Mechanical TURK? Is that an acronym?
Spectre-7 said,
March 15, 2009 @ 1:06 pm
It's a reference to The Turk, a hoax of the 18th century that was claimed to be a chess playing machine, but was later revealed to be operated by a small human chess player hidden inside.
Nick Lamb said,
March 15, 2009 @ 1:48 pm
It seems like a rule of thumb is – would readers of my research be angry if in fact these answers weren't actually obtained by asking a number of different humans? If so, then you are probably doing research on human subjects and need ethical oversight. If not, you probably aren't and there's no need to worry. For example to do some homework years ago I called local shopkeepers by telephone and asked them for their opening times. But if I'd lied, and actually the results were obtained by cycling around the town and writing down opening times from shop window signs, it would hardly have mattered. I wasn't doing research on shopkeepers, but on shops.
In the case of linguistics research, imagine if you published this sort of result, and then it was found that all your HITs were resolved by an AI running in a Cambridge laboratory. Well, some people would laugh but others would be angry. So it matters that your subjects are particular individual people, and therefore there's some call for oversight. I'd say the arms length and somewhat anonymous nature of MTurk means the oversight needed is quite minimal (compared with research on your own students or medical patients) but there should be something in place.
Chris, in terms of the "Are the wages fair?" question you should make sure before you find yourself asked this question that you're familiar with Amazon's research on what Turkers are like. It turns out that a lot of people don't really see what they're doing as employment – more like somewhere between donating blood (my country doesn't pay people for blood but you get free biscuits and small prizes) and solving a newspaper crossword. I think an ethics group will look more kindly on use of MTurk if they consider this.
Chris Potts said,
March 15, 2009 @ 3:11 pm
Nick Lamb!
Many thanks for these comments. I didn't know about Amazon's research on who's undertaking these tasks. That would indeed be valuable when describing the work to an IRB.
This kind of extreme situation is also useful to have in mind, as a reminder that we know relatively little about what's happening out there. (In a similar vein, I have wondered about student conspiracies when offering my students extra credit in exchange for participating in experiments in my department.)
No robots here!
The faces of Mechanical Turk
Rick Curtis said,
March 15, 2009 @ 10:15 pm
You may want to read the posts about Mechanical Turk by Panos Ipeirotis blog:
http://behind-the-enemy-lines.blogspot.com/search/label/mechanical%20turk
Plenty of useful information
David M. Chess said,
March 16, 2009 @ 8:29 am
Interesting post! Thanks for writing it up.
But… "incentivized"?
Harry Campbell said,
March 16, 2009 @ 11:16 am
But… "incentivized"?
Oh dear.
It should of course be "incentivised".
Natalie Klein said,
March 30, 2009 @ 6:44 pm
Thanks for posting this. I'd love to see threads in the future that explore the ethics of Mech Turk as well as the potential benefits. I'm considering using Mech Turk to tap into language populations that aren't well represented near our lab, but this does bring up issues of fair payment, especially if I don't limit the study to US IP addresses.
Does anyone know a good place to find help on setting up different types of studies? I know there are ways to try to counterbalance, etc, using Turk, but I haven't quite figured it out.