Short-long or long-short?
« previous post | next post »
On Saturday, I was at a workshop on "Brain Rhythms in Speech Perception and Production". One of the participants was Aniruddh Patel, author of Music, Language and the Brain. His presentation was "Rhythms in Speech and Music", and one of the papers that he discussed was John Iversen, Aniruddh Patel, and Kengo Ohgushi, "Perception of rhythmic grouping depends on auditory experience", JASA 123(4): 2263-2271, 2008.
Unfortunately, I had to leave that workshop early, in order to travel to Düsseldorf for the Berlin 6 Open Access conference, where I am now. As I was leaving, Aniruddh gave me a reprint of the Iversen et al. paper, and asked for comments. So I'll keep up my act as "the Madonna of linguists" (even though the reviews to date have been mixed), and offer my comments in the form of a blog post.
To start with, you should read the paper. It should be easy for interested amateurs to follow, and it's definitely worth the effort. I'm going to summarize some aspects of it anyhow, but you should take this as an advertisement for reading the original, not a substitute for it.
This work is in a long and distinguished tradition, which (in a narrow sense) goes back a hundred years to Herbert Woodrow, "A quantitative study of rhythm: The effect of variations in intensity, rate and duration", Archives of Psychology 14:1-166, 1909. The general idea is to model the responses of listeners to artificial stimuli that are differentiated in time, amplitude, duration, pitch, onset, timbre and so on. And until recently, one general conclusion would have been that these responses are essentially universal and innate — not in the sense that there are no individual differences, but in the sense that the distribution of responses would be expected to be the same, whether the subjects were recruited in Paris, in Amsterdam, in Prague, or in San Diego.
But the key finding of Iversen et al. was a large difference between a group of Japanese subjects and a group of American subjects.
Here are a few quoted sections from the paper, explaining what they did and what they found:
Stimuli were 10-second sequences in which tones alternated in either amplitude (loud-soft) or duration (long-short) (henceforth "Amplitude Sequences" and "Duration Sequences" … The basic tone was a 500Hz complex tone (15 ms rise/fall) with a duration of either 150 or 250 ms. The complex tone was a low-pass square wave consisting of the fundamental and first three odd harmonics, and was constructed to match previous work on grouping … The alternating tone was constructed by multiplying either the amplitude or duration of the basic tone by one of several small ratios (amplitude: 1.5 or 2; duration: 1.25, 1.75, or 3). The two tones alternated with a gap of 20 ms between them. To mask possible effects of starting tone order, stimuli were slowly faded in (and out) over 2.5 (double-logarithmic ramp), and each sequence was presented both forwards and reversed, yielding a total of 20 sequences (2 base durations x 2 orders of presentation [forward and reversed] x 5 ratio parameters [2 amplitude ratios + 3 duration ratios], hence four different sequences per ratio).
Here's their figure showing what the stimuli were like:
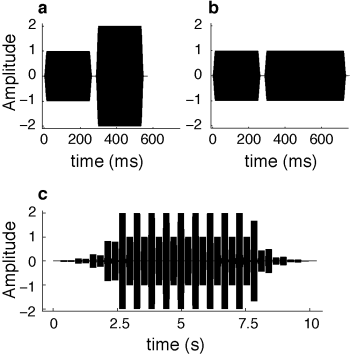
The experiment is described as follows:
Listeners were familiarized with the experiment by hearing one example sequence of the two types (but with different parameters than those used in the experiment). The experimental sequences were then presented in random order, and listeners were asked to indicate their perceived grouping by circling pairs of tones on diagrams schematically depicting the stimuli, in answer booklets with one page per sequence. The starting tone (e.g., long or short) of diagrams in the booklets was counterbalanced to avoid any possible visual bias due to the diagrams. Listeners also rated the certainty of each judgment, ranging from 3 (completely certain) to 1 (guessing)The experiment was conducted in a classroom setting, enabling data to be collected in parallel for multiple participants: 43 native American English speakers) (in San Diego; henceforth referred as “English speakers”) and 46 native speakers of Japanese (in Kyoto; all were speakers of the Kansai dialect of Japanese; three participants were excluded because they had lived abroad for more than 6 months). Participants were college aged (17-25 years). Musical training (years studied) was similar in the two groups (English: 5.0 ± 4.7 years, Japanese: 7.0 ±5.8 years; n.s., p=0.09, unpaired t-test).
The relevant piece of results: the two groups of listeners responded in the same way to the stimuli where amplitude was varied, but in strikingly different ways to the stimuli where duration was varied:
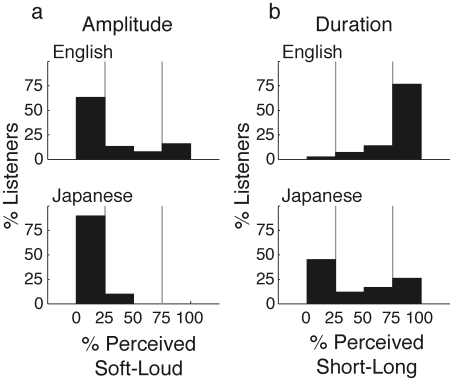
(a) Distribution of Amplitude Sequence grouping preferences of English (top) and Japanese (bottom) listeners. The distribution shows each listener’s percentage of all Amplitude Sequences heard as "soft-loud." For both English and Japanese listeners, the majority preferred a "loud-soft" grouping (63% of English listeners; 90% of Japanese listeners), with most participants choosing this preference consistently for all stimuli. (b) Distribution of Duration grouping preference for English (top) and Japanese (bottom) listeners. The distribution shows each listener’s percentage of all Duration Sequences heard as "short-long." The large majority of English listeners chose a "short-long" grouping (77%). In contrast, nearly half (45%) of the Japanese listeners chose the opposite "long-short" grouping, which English speakers almost never chose. Japanese responses were more varied, and 26% of Japanese listeners chose the "short-long" grouping. Thin vertical lines delineate regions defined as strong preference (0-25% and 75-100% preference).
To start with, let me say that I found this paper interesting and persuasive, even though it's subject to a criticism that I've sometimes raised in other contexts. The problem is that it takes two classrooms of college undergraduates, one in San Diego and one in Kyoto, as representative of "English speakers" and "Japanese speakers" respectively. But the Japanese experiments have been replicated with classes of college students in two other parts of the country, which is a start. Let's just register the caveat that we need to check a more demographically representative cross-section of the populations of English and Japanese speakers before being very confident that we know what the overall response distributions of these groups will be like, and go on.
The authors observe that
We assume that the key factor is the different auditory experience of listeners living in America vs. Japan (rather than, say, a different genetic background).
This assumption is a plausible one, and it's the assumption that I'd make as well. But other might differ, and indeed Tadanobu Tsunoda's writings on "The Japanese Brain" seem to make the opposite assumption with respect to a different set of perceptual biases. And the speculations of Ladd and Dediu about correlations between genetic diversity and linguistic typology are a more mainstream (and more plausible) example of how gene-pool differences might play a role in cases like this one.
Iversen et al. go on to say that
The most obvious source of cultural differences in auditory experience is the dominant language of the culture. Two questions must be addressed: What is it in the experience of English speakers that causes them to prefer short-long grouping of tones? How does the experience of Japanese speakers create many listeners with the opposite long-short preference? Below, we propose the hypothesis that language experience is the source of differences in grouping perception. The theoretical perspective adopted is that statistical learning of the duration patterns of common rhythmic units in speech is responsible for shaping low-level grouping biases.
Their favored speculation — an interesting one — has to do with the consequences of morphological typology. The languages of cultures previously studied in this way (e.g. English and French) tend to have proclitics — little grammatical words like "the" and "ces" and "was" and "sont", which are rather short in duration, and precede the content-words that they phonetically bind to. In contrast, Japanese is full of enclitics — grammatical formatives like "-desu" and "-ga", which follow the words that they join with.
They also mention some other possible sources of differing cultural influences — for example, a possible difference in the relative frequency of musical phrases with upbeats; and some possible statistical properties of syllable structure and duration patterns within content words in the Japanese as opposed to English. These are interesting directions to explore, but what they have to say about them is more of an appeal for research than any sort of conclusion.
My main comment back to Aniruddh is that there are some other speculations that people interested in this difference — especially if it turns out to be culturally general! — might look into, as correlates if not casuative influences. I'll suggest two in particular.
One is the general observation that Japanese has less final lengthening than many other languages do. There's a large literature on this, which is hard to describe both fairly and quickly because the methods and the results are rather varied; but let me summarize my take on it all by saying that I'm fairly sure that there's a substantive difference. This means that English (and French, and German, and Chinese) will (I believe) have a stronger overall statistical association than Japanese does between phonetically longer syllables and group-final position.
(Among many complicating factors, there's apparently a special kind of final lengthening that young women use with close friends in informal settings. I've had Japanese speakers tell me that they were were reading sentences with especially clipped final syllables in order to differentiate themselves from this style.)
This difference in final lengthening apparently appears quite early in child language development, perhaps even during babbling, suggesting that it's salient to listeners from a very early age. According to Hallé, de Boysson-Bardies, and Vihman, "Beginnings of prosodic organization: intonation and duration patterns of disyllables produced by Japanese and French infants", Language and Speech 34 (Pt4):299-318, 1991:
In this study, some prosodic aspects of the disyllabic vocalizations (both babbling and words) produced by four French and four Japanese children of about 18 months of age, are examined. F0 contour and vowel durations in disyllables are found to be clearly language-specific. For French infants, rising F0 contours and final syllable lengthening are the rule, whereas falling F0 contours and absence of final lengthening are the rule for Japanese children. These results are congruent with adult prosody in the two languages. They hold for both babbling and utterances identified as words. The disyllables produced by the Japanese infants reflect adult forms not only in terms of global intonation patterns, but also in terms of tone and duration characteristics at the lexical level.
A second avenue to explore is the effect of poetic meter, in three senses, arranged in order of decreasing interest: 1) as a symptom of basic phonological structure; 2) as a source of experience engaged even by a musical perception task; 3) as a mode of thinking that some students are trained to use in interpreting rhtymic patterns.
In particular, strict binary grouping is imposed in a (widespread but rather artificial) style of reciting Japanese poetry that I've heard. Since I don't know much about either Japanese language or Japanese metrics, I've given some quotes below to describe the landscape here.
From Tomoko Kozasa "Moraic Tetrameter in Japanese Poetry":
…Japanese versification is based on five and seven-mora lines. However, Japanese verse is generally recited with eight beats per line. This is called 'Quadruple Time Style,’ "in which each measure contains four rhythmic units; each rhythmic unit contains two moras of the text or a pause equal to two morae in duration or a one mora text accompanied by one mora pause." (Kawakami 1974: 665)
From Richard Gilbert and Judy Yoneoka, "From 5-7-5 to 8-8-8: An Investigation of Japanese Haiku
Metrics and Implications for English Haiku", 2000:
Every Japanese schoolchild knows traffic-crossing aphorisms such as te o agete oudan houdou watarimashou (raise your hand/to cross at the crosswalk) as well as the rather tongue-in-cheek anti-traffic aka shingo minna de watareba kowakunai (at the red light/all-together, crossing/is fearless!) Such aphorisms, called hyogo in Japanese, are almost invariably based on the traditional haiku pattern of 5-7-5 -on. Japanese children are thus exposed to this pattern from quite a young age. When they get a bit older, they study hyakunin-isshu, a set of 100 classical Japanese waka patterned in 5-7-5-7-7, which form the basis of a card game often played around the New Year at home and in school. A popular TV program starts off each morning by introducing haiku sent in by viewers–but calls these haiku "5-7-5" (rather than haiku), presumably to avoid pedantism and encourage participation. A recent episode of the popular "Chibi marukochan" shows a reticent old man who ends up winning a haiku contest by inadvertently producing "masterpieces" such as dou shiyou nani mo haiku ga ukabanai (What to do? Not one haiku comes to mind.) These few examples show that rhythms based on 5s and 7s come quite naturally to people in Japan.
[…]
Japanese verse theorists of recent years have come to agree that the 17-on haiku is actually based on a 24-beat template which divides into 3 lines of 8 beats each, including 3, 1, and 3 silent beats, respectively.
The authors of the last paper did an experiment to see how Japanese speakers would group the syllables of various traditional verses. This figure shows one example where different alignments are possible:
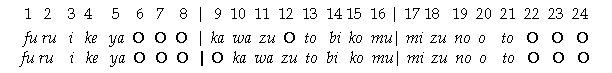
To the extent that Japanese schoolchildren are taught these styles of recitation and analysis based on binary groupings of moras, but apply them in a variable way, this might have an influence on how college students react when asked to group binary acoustic stimuli of the kind used in the Iversen et al. paper. The particular patterns and the particular dimensions of variation are not by any means artifacts — for example, it's because of a basic typological difference between Japanese and English that the position of English stress matters to scansion, in popular music as well as in metered verse, while the position of Japanese accent does not. But it's possible that some of the stimulus-grouping behavior comes partly from a recitation/analysis technique that Japanese students are explicitly taught.
gyokusai said,
November 11, 2008 @ 8:39 am
Hope you enjoy my hometown, and my alma mater!
Cheers,
Jay
Mary said,
November 11, 2008 @ 6:20 pm
Very interesting stuff, but your posting title confuses me. Did you perhaps mean "Soft-loud or long-short", not "Short-long or long-short"?
[(myl) No, in this case I meant what I wrote. Note that the difference between the English and Japanese subject groups was that the English group almost always grouped the alternating-duration stimuli as "short-long", while the Japanese group responded with a more even mixture of "short-long" and "long-short" responses.]
Kevin Iga said,
November 13, 2008 @ 2:42 am
Another issue to consider is that in Japanese, short and long vowels are contrastive and independent of stress. In English, there are short vowels and long vowels, but these usually differ in quality (tense/lax, not to mention "long vowels" that are really diphthongs) and correlate with stress: unstressed syllables tend to be lax, if not schwa. Hence the difficulty among English learners of Japanese in hearing the short-long distinction in pairs like "ojisan" (uncle) and "ojiisan" (grandfather).
I wonder if English speakers are applying some rule to the stimuli to determine length, while Japanese speakers do not expect any rule to determine length, since they expect the distinction to be meaningful.
By the way, one way to test for the effect of genetic vs. language influence is to test Japanese Americans like me. Or better, Japanese Americans who have had very little exposure to Japanese. These should be pretty easy to find in San Diego.