"Clutter" in (writing about) science writing
« previous post | next post »
Paul Jump, "Cut the Clutter", Times Higher Education:
Is there something unforgivably, infuriatingly obfuscatory about the unrestrained use of adjectives and adverbs?
In a word, no. But Mr. Jump is about to tell us, approvingly, about some "science" on the subject:
Zinsser and Twain are quoted by Adam Okulicz-Kozaryn, assistant professor of public policy at Rutgers University Camden, in support of his view that the greater the number of adjectives and adverbs in academic writing, the harder it is to read.
Okulicz-Kozaryn has published a paper in the journal Scientometrics that analyzes adjectival and adverbial density in about 1,000 papers published between 2000 and 2010 from across the disciplines.
Perhaps unsurprisingly, the paper, "Cluttered Writing: Adjectives and Adverbs in academia," finds that social science papers contain the highest density, followed by humanities and history. Natural science and mathematics contain the lowest frequency, followed by medicine and business and economics.
The difference between the social and the natural sciences is about 15 percent. "Is there a reason that a social scientist cannot write as clearly as a natural scientist?" the paper asks.
I'm not going to discuss the neurotic aversion to modification. Instead, I'm going to explore Paul Jump's apparent ignorance of the norms of scientific communication and of standard English prose, and the much more surprising parallel failures of the editors of the Springer journal Scientometrics.
The first three sentences of "Cluttered writing: adjectives and adverbs in academia":
Scientific writing is about communicating ideas. Today, simplicity is more important than ever. Scientist are overwhelmed with new information.
This scientist are indeed overwhelmed, but the first overwhelming thing about Okulicz-Kozaryn's paper is its profusion of grammatical errors, like "Readable scientific writing could reach wider audience and have a bigger impact outside of academia", or "Why measuring readability by counting adjectives and adverbs?" Dr. Okulicz-Kozaryn even manages to introduce a grammatical error into his quotation from William Zinsser:
You will clutter your sentence and annoy the reader if choose a verb that has a specific meaning and then add an adverb that carries the same meaning.
Okulicz-Kozaryn is not a native speaker of English, so I'm not going to blame him, but you'd think that Springer could have hired a competent copy editor, especially given that they want to charge you $39.95 to read this (3-page-long) article.
But I'm even more overwhelmed by papers whose research methods are so badly documented that I can't determine whether my suspicions about elementary experimental artifacts are valid.
There are two good things about how Okulicz-Kozaryn got his adjective and adverb proportions. First, he used a somewhat reproducible source of data, namely JSTOR's Data For Research:
I use data from JSTOR Data For Research (http://dfr.jstor.org/). The sample is about 1,000 articles randomly selected from all articles published in each of seven academic fields between 2000 and 2010. I made the following selection from JSTOR:
1. Content type: Journal (to analyze research, not the other option: Pamphlets)
2. Page count: (5–100) (to avoid short letters, notes, and overly long essays; fewer than five pages may not offer enough to evaluate text, and longer than 100 may have a totally different style than the typical one for a given field)
3. Article type: Research article (other types such as book reviews may contain lengthy quotes, etc)
4. Language: English
5. Year of Publication: (2000–2010) (only recent research; did not select 2011, 2012, since for some fields JSTOR does not offer most recent publications—the number of available articles in most recent years dramatically drops, based on a JSTOR graph available at the selection).
The dataset is only somewhat reproducible, since it represents a random selection made by JSTOR's site, and Okulicz-Kozaryn doesn't give us the selection he got. More important, he doesn't tell us what kind of data he actually got, and how he processed it. The JSTOR DFR service does not provide full text, but rather offers overall word counts along with a choice among bigrams, trigrams, and quadgrams. And many tokens are indicated in these lists only in terms of the number of characters they contain. Thus for one scientific article whose quadgram data I got from this service, the top of the frequency list was:
<quadgram weight="212" > ## ## ## ## </quadgram>
<quadgram weight="38" > ### ### ### ### </quadgram>
<quadgram weight="29" > ### et al # </quadgram>
<quadgram weight="21" > ### ## ## ## </quadgram>
<quadgram weight="20" > ## ## ## ### </quadgram>
<quadgram weight="16" > ### ### ## ## </quadgram>
<quadgram weight="14" > ## ## ### ### </quadgram>
<quadgram weight="13" > ## ### ### ## </quadgram>
<quadgram weight="13" > ### ### ## ### </quadgram>
<quadgram weight="11" > of density dependence in </quadgram>
<quadgram weight="11" > rate of population increase </quadgram>
<quadgram weight="10" > ### ## ### ### </quadgram>
<quadgram weight="10" > density dependence in the </quadgram>
In an article from the humanities, the top of the quadgram list looked like this:
<quadgram weight="8" > ### ### ### ### </quadgram>
<quadgram weight="3" > scraps of ### chilean </quadgram>
<quadgram weight="3" > of ### chilean arpilleras </quadgram>
<quadgram weight="2" > is a tale of </quadgram>
<quadgram weight="2" > of the ### # </quadgram>
<quadgram weight="2" > ### ### and ### </quadgram>
<quadgram weight="2" > it is a tale </quadgram>
<quadgram weight="2" > of ### ### ### </quadgram>
<quadgram weight="1" > food ### lack of </quadgram>
<quadgram weight="1" > # ### distinguishing these </quadgram>
<quadgram weight="1" > hearts and minds of </quadgram>
<quadgram weight="1" > disappeared ### hope for </quadgram>
<quadgram weight="1" > women the usual treatment </quadgram>
I presume that the items indicated with variable-length octothorp sequences are numbers, mathematical symbols, proper names, OCR errors, and other things that JSTOR's algorithms did not recognize as "words". (I couldn't find any documentation on the DFR website about this.)
But Okulicz-Kozaryn doesn't tell us what he did with these all-# tokens. Did he just use JSTOR's word counts, without subtracting the count of #-tokens? If so, then it's not surprising that the proportion of adjectives and adverbs would be lower in disciplines where the #-token count was higher: presumably all part-of-speech categories had smaller proportions in such texts.
Or were the #-words subtracted from the word counts as well as left out of the part-of-speech tagging? If so, then it matters a lot just what those #-tokens were. If the #-tokens included all the tokens that weren't in some list of "words" that JSTOR used, then maybe writing in the natural sciences uses a larger fraction of modifiers that didn't make the list.
A second good thing about Okulicz-Kozaryn's paper is that he used a somewhat reproducible method of analysis:
I identify parts of speech using Penn Tree Bank in Python NLTK module.
Unfortunately, it's not clear which NLTK tagger he actually used — there is no NLTK tagger called "Penn Tree Bank", though there are several available alternatives that use the Penn Tree Bank tagset.
But this uncertainty is a small thing in comparison with a really big problem. Okulicz-Kozaryn doesn't tell us how he actually tagged the n-gram lists. Did he extract individual words and look them up in one of NLTK POS lexicons? Did he ask one of the NLTK taggers to cope with things like
### et al #
or
food ### lack of
Without answers to these questions about what data he actually analyzed and how he analyzed it, Okulicz-Kozaryn's results — presented only as a graph of proportions — are completely meaningless:
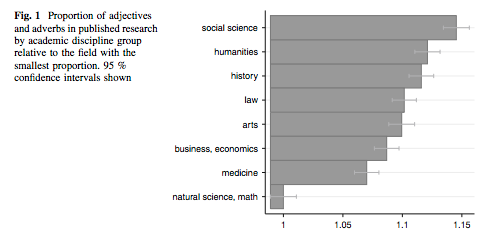
The fact that Okulicz-Kozaryn doesn't tell us anything about these issues leads me to expect the worst.
This all raises an important question about Scientometrics (and its publisher, Springer): Never mind copy editors, do they have any reviewers or content editors? And it also raises a question about Paul Jump (and his publisher, Times Higher Education): Did he actually read this article? If he did, how did he miss (or why did he ignore) its scientific problems and its ironically poor English? If he didn't, why is he telling us about the paper's conclusions as if they were from a credible source?
I can't resist adding Okulicz-Kozaryn's own prescription for improving the scientific literature:
How do we keep up with the literature? We can use computers to extract meaning from texts. Better yet, I propose here, we should be writing research in machine readable format, say, using Extensible Markup Language (XML). I think, it is the only way for scientists to cope with the volume of research in the future.
Words fail me, adjectives and adverbs included.
If you care about the curious phenomenon of modifier phobia, here are some of our many previous posts on the topic:
"Those who take the adjectives from the table", 2/18/2004
"Avoiding rape and adverbs", 2/25/2004
"Modification as social anxiety", 5/16/2004
"The evolution of disornamentation", 2/21/2005
"Adjectives banned in Baltimore", 3/5/2007
"Automated adverb hunting and why you don't need it", 3/5/2007
"Worthless grammar edicts from Harvard", 4/29/2010
"Getting rid of adverbs and other adjuncts, 2/21/2013
In an attempt to reduce the volume of irrelevant comments, let me stipulate:
It might be true that social scientists use 15% more adjectives and adverbs in their papers than physicists do, but we can't tell from Okulicz-Kozaryn's paper whether they do or don't. He provides no evidence, aside from appeals to unscholarly and hypocritical authorities, that small differences in modifier proportions have any effect on readability, whether positive or negative. And the idea that removing one modifier in eight, on average, would be a good way to reduce the volume of scientific publication is so silly that I wondered for a while whether this whole article might be a sly joke.
[Tip of the hat to R. Michael Medley]
Jonathan Mayhew said,
August 30, 2013 @ 8:43 am
The paper doesn't even attempt to demonstrate that a greater number of adverbs and adjectives make papers less readable. That is just his starting assumption.
Jake Nelson said,
August 30, 2013 @ 9:27 am
I'll note regarding the "write in XML" comment (laughable), I do wonder sometimes if an easily-parsable conlang isn't the way to go for technical writing. My pet one would really offend him, though- it treats adjectives as the roots…
Haamu said,
August 30, 2013 @ 9:51 am
I think he's saying that the power needed to get through a given number of scientific papers in time T is proportional to the amplitude of modifiers in the text squared. This is because eliminating modifiers both reduces the volume of text and increases the readability of the text, allowing it to be processed faster.
Therefore, the benefit of social scientists writing like natural scientists would seem to be not 15%, but more like 32%. That's nothing to sniff at!
Further, by my calculations, if writers in all fields could just reduce their use of modifiers by a paltry 2.3% each year, then the reading population could comfortably keep pace with the 4.7% annual increase in scientific publication. Problem solved.
[(myl) Sorry, but no.
Adjectives and adverbs together constitute roughly 10% of text. (There are also plenty of nominal modifiers, prepositional phrases as adverbial adjuncts, etc., but never mind that.) A reduction of 2.3% in modifiers would then only constitute a reduction of .023*.1 = .0023 = 0.23 percent in the overall volume of verbiage.]
M Lee said,
August 30, 2013 @ 10:07 am
"NLTK comes with a number of dictionaries that can be used to identify parts of speech, say adjectives and adverbs."
Natural science and math papers may include more adjectives and adverbs that are not listed in the Natural Language Toolkit's dictionaries.
[(myl) Yes, this is exactly one of the points that I'm worried about. A similar possibility is that JSTOR is using some sort of dictionary to #-ize textual tokens, and that papers in the natural science have more tokens that are missing from this list.]
bks said,
August 30, 2013 @ 10:25 am
Peter Medawar has written in favor of stuffing humanity back into scientific papers. He argues that writers are stripping out the messy truth about scientific discovery and thus failing to inform the reader about how one actually does science (_Induction and Intution in Scientific Thought_(1969)).
With regard to keeping pace it has been suggested (I.I. Rabi?) that mediocre scientists be paid not to publish.
–bks
Bobbie said,
August 30, 2013 @ 11:09 am
Sounds like this is just a few steps away from computer-generated sports articles (which already exist.) http://www.wired.com/gadgetlab/2012/04/can-an-algorithm-write-a-better-news-story-than-a-human-reporter/
Haamu said,
August 30, 2013 @ 11:12 am
My apologies for the attempt at humor. Apparently it fell flat.
[(myl) Apologies in return for not making it clear that I was playing along with the gag…]
J.W. Brewer said,
August 30, 2013 @ 1:14 pm
Prof. O-K may not be an L1 Anglophone, but he did earn his Ph.D. from a U.S. university and was a post-doc at Harvard prior to being hired by Rutgers. I wouldn't hold certain sorts of syntactic errors in speech against him any more than I would hold a foreign accent against him, but it wouldn't seem unfair for U.S. universities who are paying him to expect a certain level of grammaticality in his edited scholarly prose, if necessary by having a native-speaker research assistant or copyeditor clean things up before submission to avoid embarrassment to all concerned.
But what I found most intriguing was the suggestion that on his (highly dubious) metric for comprehensibility, humanities scholarship scored better than the social sciences (although worse than the natural sciences). I suppose I would have expected soft-science scholarly writing to naturally fall halfway in between the humanities and the hard sciences. Although now I notice that he's broken out "economics" from "social sciences," which makes me even more curious . . . But since he himself seems to be in a social-sciences field, he's certainly not being chauvinistic.
There is an interesting question which Prof. O-K's own limited English profiency inadvertently raises – if at least some English-language scholarly articles are increasingly likely to be read by an international academic audience with a high percentage of readers who are not L1 Anglophones, how ought that affect conventional scholarly drafting style (and is the nature of the audience and thus those implications going to differ by discipline)? I can see a possible argument for responding to that sort of change in audience by privileging clarity over elegance of prose style, avoiding excessively idiomatic or colloquial modes of expression, etc., using the same technical terms over and over again rather than rummaging through the thesaurus for obscure synonyms, because exactly the sort of things that might make your prose less boring to a native speaker might make it harder to follow without undue effort for a non-native speaker. Don't get me wrong; I'm certainly not accepting the proposition that trying to arbitrarily reduce the proportion of modifiers is a coherent or sensible way to promote clarity-over-elegance, even if that's the desideratum. But certainly minimum grammaticality (assume your non-native speaker reader has a good ESL grammar text and follows it scrupulously) would seem to be even more important, because a non-native speaker may be less likely to gloss over trivial grammatical errors by being able to guess from context the intended meaning.
Andrew Goldstone said,
August 30, 2013 @ 1:50 pm
My guess is that the 4-grams with # in them are obfuscations to make it hard to reconstruct the full text, which I suppose might be possible otherwise. Have been doing some work with a bunch of JSTOR DfR unigram data, and they don't have any # in them.
[(myl) I don't think this is correct. It's true that the unigram lists (called "word counts") don't have any #-tokens in them — but they are also much shorter than they would be if the bigram, trigram, and quadgram lists were just obfuscated derivatives of the same token sequence.
For example, one Botany example I recently looked at lists only 738 tokens of 357 types in the unigram counts; but it lists 1037 tokens of 731 bigram types, which is not mathematically possible on your theory.
By searching for a few of the ngram strings I was able to ascertain that the paper in question is http://www.jstor.org/stable/4129970, which is also consistent with its numerical ID. By comparing the ngram lists with the text, it seems clear that the #-items are things that their algorithm could not recognize as words — and also that their algorithm is freely munging tables and so on. Thus these table cells
yield (among others) the quadgrams
<quadgram weight="1" > plant hairs short ### </quadgram>
<quadgram weight="1" > whole plant hairs short </quadgram>
The first of those includes the last two words of the first row of the third table cell and the first two words of the second row of the second table cell (which is not at all logically contiguous). The second 4-gram above moves this non-sequence along by one, with the letters '(c.' coded as '###'.
And the five-item sequence
Maxted, Kitiki & Allkin 4392
contributes the four-grams
<quadgram weight="3" > ### kitiki ### allkin </quadgram>
and
<quadgram weight="1" > kitiki ### allkin ### </quadgram>
("Maxted" is one of the authors of the paper.)
Numbers and symbols like '&' reliably come out as #-tokens in the 2-4grams (and are omitted in the "word counts"). And some words (like "Maxted") are treated in the same way — though why "Maxted" is not a word, but "Kitiki" and "Allkin" are words, remains mysterious.
Also, why some #-items are given as ### and others as ## (etc.) is not yet clear to me.
I'm somewhat shocked that (as far as I can tell) JSTOR has nothing to say about how this "data for research" is created. If all of this is documented somewhere, it's darned hard to find. How can they invite people to do research on "data" with such mysterious provenance?]
Yet Another John said,
August 30, 2013 @ 3:59 pm
I'm confused, and possibly missing something (since I don't have access to Okulicz-Kozaryn's article, but:
It seems that the only content of the cited article is a comparison of adjective and adverb proportions in academic papers across various disciplines. Was there any serious attempt to correlate this with some kind of measure of the readability of the article? Or did Okulicz-Kozaryn and Jump simply hang the adjective-count data on the rhetorical peg of "everyone already knows that humanities professors use too much jargon"?
I'm puzzled by the implication that papers in art theory and history, with all of their needless adjectives, are so much harder to read than papers in math or physics. Has Mr. Jump ever actually tried to read an article on particle physics or algebraic K-theory?
[(myl) Oh ye of little faith — You do have access: here.]
Rubrick said,
August 30, 2013 @ 3:59 pm
You shouldn't say that Okulicz-Kozaryn's results are completely meaningless, but rather that the meaninglessness of his results is complete. By converting an adjective to a noun you reduce clutter and improve readability.
David Marjanović said,
August 30, 2013 @ 4:32 pm
:-D :-D :-D :-D :-D :-D :-D
Few scientific journals are copyedited anymore! At the same time, the biggest publishers (of which Springer of course is one) make annual profits of 32 to 42 % of revenue! Reviewers of course exist, but we hardly ever see copyediting as part of their unpaid job; neither do the editors, who are usually not paid either (and when they are, it's a pittance); and I've literally never encountered the term content editor before.
Commercial publishing of scientific journals is a racket.
Andrew Goldstone said,
August 30, 2013 @ 4:44 pm
@myl Thank you for straightening me out! That says something I didn't know about what's being left out of those unigram counts you can get from JSTOR.
Steve Kass said,
August 30, 2013 @ 9:01 pm
@J.W.Brewer: The reason Okulicz-Kozaryn broke out "economics" from "social sciences" is because they're broken out in the DFR data set. Business and Economics is one DFR discipline group and Social Sciences is another.
The DFR discipline groups do overlap. For example, among all English-language research articles of between 5 and 100 pages in journals published between 2000 and 2010, about 11% of the articles in Social Sciences are also in the Business and Economics group, and these same dual-listed articles comprise 29% of the articles in Business and Economics group.
I can't speculate on how or whether this overlap might affect the analysis, but it think it would be impossible to account for using 1000-article samples. JSTOR provides a list of citations for each sample, but there's no way I can think of for Okulicz-Kozaryn to have identified which specific articles in one sample are dual-listed in another group, since he only had citations for fewer than 1% (on average) of the articles in each group.
Jason said,
August 31, 2013 @ 4:35 am
Consider computer science writing, renowned for its clarity and easy comprehensibility. For example, The Java Runtime environment has a rich ontology of objects, infamously containing such things as a
A model of clarity: 19 words, three technical terms, and only one adjective used for the lot.
Yet Another John said,
August 31, 2013 @ 8:55 am
@David Marjanovic:
I won't dispute your larger point about the publishing industry, but it may be just as well that science publishers don't hire copy editors to fiddle with the final versions of the article, especially in mathematics (which is filled with terms of art and is highly sensitive to the precise wording of a statement).
For instance, "iff," which a copy editor might think is a typo and "correct" to "if," actually means "if and only if" in mathspeak — a huge difference!
Or think of complexity theory, where "O(f(n)) = O(g(n))" means something completely different than "O(g(n)) = O(f(n))". This is an extreme example of confusing notation, but the point is that we mathematicians probably don't want people messing around with the syntactic details of our sentences.
Jerry Friedman said,
August 31, 2013 @ 10:22 am
Surely there are people who can and would copyedit and who know what "iff" and other mathematical terms mean or at least how they're spelled. I agree that you wouldn't want the equations copyedited.
Dragos said,
August 31, 2013 @ 11:13 am
@Jason,
Much of the computer science writing is full of modifiers. The technical vocabulary includes terms such as: quick format, free space, incremental backup, asynchronous I/O, empty string, sorted array, linked list, object-oriented programming, derived class, null object, virtual member, deep copy, etc.
[(myl) Not to speak of materials science, e.g. this from the most recent issue of Science:
Existing stretchable, transparent conductors are mostly electronic conductors. They limit the performance of interconnects, sensors, and actuators as components of stretchable electronics and soft machines. We describe a class of devices enabled by ionic conductors that are highly stretchable, fully transparent to light of all colors, and capable of operation at frequencies beyond 10 kilohertz and voltages above 10 kilovolts. We demonstrate a transparent actuator that can generate large strains and a transparent loudspeaker that produces sound over the entire audible range. The electromechanical transduction is achieved without electrochemical reaction. The ionic conductors have higher resistivity than many electronic conductors; however, when large stretchability and high transmittance are required, the ionic conductors have lower sheet resistance than all existing electronic conductors.
I count 26 adjectives and adverbs in 121 words, for or 21.5%, which is hard to beat in normal prose from whatever source. (And if we count "existing" and an adjective, then it's 28/121 = 23.1%.)]
David Morris said,
September 2, 2013 @ 7:28 am
Three general comments about (mainly) adjectives and (to a lesser extent) adverbs:
1) It is possible to write a large number of significant sentences in English without either adjectives or adverbs – 'In the beginning, God created the heavens and the earth', for example. Determiners, nouns/pronouns, verbs and prepositions seem to be more 'central' to English sentences and adjectives and adverbs less so. Possibly the only phrase structure which requires an adjective or adverb is 'S + copula + adj or adv'.
2) When adjectives *are* used, they can be strung together in a way in which other word classes can't. Indeed they have their own internal order – opinion, size, age, shape, colour, origin, material + N (Swan – Practical English Usage, p 11), suggesting that 7 adjectives can be strung together without a problem.
3) When words *have* to be omitted to fit a word limit, the adjectives and adverbs are probably the ones to go. If you submit the sentence 'The quick brown fox jumped over the lazy dog' and the editor tells you that the word limit is six words, then 'quick', 'brown' and 'lazy' are the ones to go. The resulting setence is a lot more boring, but it's a complete sentence.
JBL said,
September 2, 2013 @ 2:57 pm
Since the discussion covers copy-editing in mathematics: among my handful of published papers in mathematics journals are two that I know to have been sent to a professional copy-editor between acceptance and publication. In both cases, the copy-edited version was sent to the authors to double-check for errors.
Christopher Culver said,
September 2, 2013 @ 7:21 pm
Isn't Springer notorious for publishing manuscripts as is, to the point of insisting that monograph authors provide a print-ready manuscript and then it just slaps its title and copyright pages on the book? I've heard similar complaints about Brill.
Some linguistics publishers run all their submissions past a native speaker. I've made quite a career of that. But I'm not entirely comfortable with the fact that I am essentially helping to perpetuate a tax on academics for the misfortune of being born in the wrong country (as many of the articles I correct are perfectly intelligible, orthographically and grammatically correct even, but some journals still want to pay enormous sums at taxpayer expense just for the extra sheen of English or American style).
Circe said,
September 5, 2013 @ 2:18 am
@Christopher Culver:
Graham Cormode once wrote a humorous piece on the "techniques" that can be used by an adversarial referee to shoot down a paper (in the context of computer science). One of these techniques, which he calls the "Natives are Restless" technique, is described as follows:
Checking the facts | Stats Chat said,
September 8, 2013 @ 6:29 pm
[…] Liberman, in two posts at Language Log, tackles the claim Perhaps unsurprisingly, the paper, "Cluttered […]