Dependency Grammar v. Constituency Grammar
« previous post | next post »
Edward Stabler, "Three Mathematical Foundations for Syntax", Annual Review of Linguistics 2019:
Three different foundational ideas can be identified in recent syntactic theory: structure from substitution classes, structure from dependencies among heads, and structure as the result of optimizing preferences. As formulated in this review, it is easy to see that these three ideas are completely independent. Each has a different mathematical foundation, each suggests a different natural connection to meaning, and each implies something different about how language acquisition could work. Since they are all well supported by the evidence, these three ideas are found in various mixtures in the prominent syntactic traditions. From this perspective, if syntax springs fundamentally from a single basic human ability, it is an ability that exploits a coincidence of a number of very different things.
The mathematical distinction between constituency (or "phrase-structure") grammars and dependency grammars is an old one. Most people in the trade view the two systems as notational variants, differing in convenience for certain kinds of operations and connections to other modes of analysis, but basically expressing the same things. That's essentially true, as I'll illustrate below in a simple example. But Stabler is also right to observe that the two formalisms focus attention on two different insights about linguistic structure. (I'll leave the third category, "optimizing preferences", for another occasion…)
This distinction has come up in two different ways for me recently. First, ling001 has gotten to the (just two) lectures on syntax, and because of the recent popularity of dependency grammar, I need to explain the difference to students with diverse backgrounds and interests, some of whom find any discussion of syntactic structure opaque. And second, someone recently asked me about whether anyone had used dependency grammar in analyzing music. (The answer seems to be "mostly not" — though see this paper — but the relevant question really is what the advantages of dependency models in this application might be.)
Let's start with substitution classes as evidence for constituency. As Beatrice Santorini and Tony Kroch put it in Chapter 2 of their 2007 syntax textbook:
The most basic test for syntactic constituenthood is the substitution test. The reasoning behind the test is simple. A constituent is any syntactic unit, regardless of length or syntactic category. A single word is the smallest possible constituent belonging to a particular syntactic category. So if a single word can substitute for a string of several words, that's evidence that the word and the string are constituents of the same category.
In the simple phrase very large boxes, this perspective leads us to conclude that the adverb very forms a constituent with the adjective large, which in turn forms a constituent with the noun boxes. Among the arguments for this analysis are the fact that we can substitute arbitrary unmodified adjectives for very large (e.g. small, red, etc.), or other adverbially-modified adjectives (like really tiny), but not plain adverbs (so that very boxes, extremely boxes, etc., are ungrammatical).
In contrast, in the phrase three large boxes, the number three forms a constituent with the adjective-noun combination large boxes, so that we can substitute plain nouns for large boxes (e.g. three bags) or more complex nominals (e.g. three absurdly small green bicycles); and we can substitute other numbers for three (nine, five hundred, etc.).
Ignoring details about node names, this suggests a distinction between left-branching and a right-branching binary trees like these:
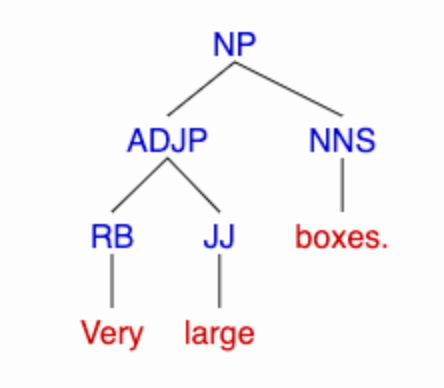
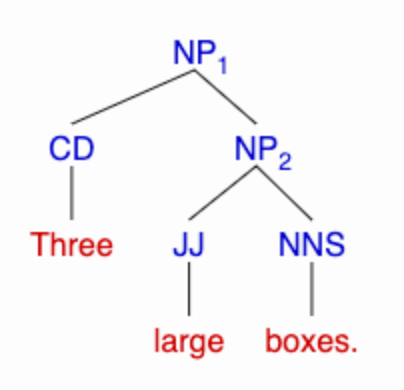
(Those particular part-of-speech and node labels come from the Penn Treebank project.)
In the notation of labelled brackets, we can represent the distinction this way:
[NP [ADJP [RB Very] [JJ large]] [NNS boxes.]]
[NP [CD Three] [NP [JJ large] [NNS boxes.]]]
Alternatively, we might base our analysis of the same two phrases on what Stabler calls "dependencies among heads", in this case two instances of modifier-head relations. Thus in "very large boxes", very is an adverb modifying the adjective large, which in turn modifies the plural noun boxes, while in "three large boxes", the number three modifies the plural noun boxes, which is also modified by the adjective large.
Again passing over details about the names of lexical and relational categories, this gives us two different sets of binary word-to-word "dependencies", which express essentially the same distinction as the tree structures did:
 |
 |
The corresponding data structures tell us, for each word, what its dependency relation is to which other word (identifying word positions with sequence numbers starting from 0):
Very ADV advmod large 0 1
large ADJ amod boxes 1 2
Three NUM nummod boxes 0 2
large ADJ amod boxes 1 2
(Those part-of-speech and dependency names come from the Universal Dependencies project, and the diagrams come from the displaCy visualizer, with the head of each arrow placed on the dependent word, and the root of the arrow on its head.)
In a dependency analysis, each word is given a specific relation to another single word, its "head" — except that just one word in each sentence depends on a sort of virtual word, the "root". (In those examples, the dependent of the root is boxes, though that's not shown in the diagram.) In the simplest case, we assume that none of the dependency lines cross.
With appropriate conventions for translating relation and node names, the resulting dependency structures are isomorphic to tree structures. Details on both sides can make translation complicated — see e.g. Fei Xia and Martha Palmer, "Converting dependency structures to phrase structures", 2001, or Richard Johansson and Pierre Nugues, "Extended constituent-to-dependency conversion for English", 2007.
We can (and do) talk about dependencies and heads in tree structures, or about phrasal structures in dependency representations. But the various versions of the two formalisms lend themselves variously to various applications — more on this later.
AntC said,
October 10, 2020 @ 3:12 pm
someone recently asked me about whether anyone had used dependency grammar in analyzing music.
The fad for using grammatical methods to analyse music, I think dates back to this series of lectures, when Chomsky was all the rage.
Bernstein was a great conductor and composer (and accompanist). A musical theorist not so much. His approach didn't convince me at the time. It hasn't aged well.
{myl) Shenkerian analysis goes back to 1900 or so, and strongly influenced Lerdahl & Jackendoff.]
AntC said,
October 10, 2020 @ 7:25 pm
(Thanks Mark. wp says "an abstract, complex, and difficult method, not always clearly expressed by [the originator] himself and not always clearly understood." Oh, it's talking about Shenker, not Chomsky.)
A better tool for musical analysis might be Model-theoretic syntax. (Pretext to mention how much I miss Geoff's posts.)
Different styles of music have constraints on which progressions of chords are allowed. They have constraints on how you can subdivide the rhythms within the bar/measure. And on how much you can snip up the melodies(s) to make variations. There'd be an interesting comparison between the melodic homogeneity in (say) The Art of Fugue vs Pictures at an Exhibition vs Franck's Symphony in D vs Coltrane's Giant Steps.
The reason I think Bernstein's idea just doesn't work is that language is a tool to express meaning/grammar is a device to map linguistic structure to structure of some external world. Whereas abstract music is the meaning. ('Abstract' leaving aside Programme Music, soundtracks, etc.)
Scott P. said,
October 11, 2020 @ 1:12 am
Wouldn't the language equivalent to abstract music be nonsense verse?
poet Dylan Thomas
Dylan Thomas
#34 on top 500 poets
Dylan Thomas
Poems
Quotes
Comments
Stats
E-Books
Biography
Videos
Search in the poems of Dylan Thomas:
How Soon The Servant Sun
Poem by Dylan Thomas
Autoplay next video
How soon the servant sun,
(Sir morrow mark),
Can time unriddle, and the cupboard stone,
(Fog has a bone
He'll trumpet into meat),
Unshelve that all my gristles have a gown
And the naked egg stand straight,
Michael Watts said,
October 11, 2020 @ 10:34 am
I don't doubt that this can be true, but it isn't true in the simple, obvious way you'd hope for. Using the examples of "very large boxes" and "three large boxes", the dependency diagram for "very large boxes" shows the corresponding tree structure very directly. "Very" depends on "large", and "very large" forms a taxon. "Large" depends on "boxes", so "very large boxes", which includes the dependents of "large", forms another taxon.
But in "three large boxes", the dependency diagram is not so helpful. It shows that "three" and "large" are perfectly symmetric, both depending on "boxes". (And I agree, as to the dependency relations!) This leaves us no way to claim that "large boxes" should form a taxon excluding "three".
(It's also uninformative as to the ultimate word order of the phrase — "large three boxes" is quite impossible, but the dependency diagram would not seem to rule it out. However, this is also something of a problem, though less so, for the tree structures.)
It looks to me like converting the dependency diagram for "three large boxes" into a tree structure will require us to do something like look at the difference between "nummod" and "amod", which I find distasteful. Am I on the right track?
[(myl) We're assuming that string order of tokens is fixed, so that "large three boxes" is out. There are several other things that I omitted from the discussion: What principles (if any) define the notion "head" in a phrase-structure grammar? And what arity of tree branches are allowed?
Many phrase-structure grammars for English (including the original Penn Treebank) would indeed specify a ternary structure for [three large boxes]. But if only binary trees are allowed, and if the head of a nominal phrase is (what traditional grammars would call) the "head noun", then a right-branching structure is needed.
But you're right that for intertranslatability to rise to the level of isomorphism, we need some additional assumptions. ]
Michael Watts said,
October 11, 2020 @ 11:13 pm
Well, sure, if you're going from the utterance to the structure. But I believe the structure is closer to the internal mental representation, and must be generated before the sentence is. So the problem a person solves whenever they produce a sentence is "given this structure, how do I put it into a linear stream of words?"
And as such, I'd like the structure to carry enough information for that problem to be solvable. (Or, if it doesn't, for the different sentences that the structure appears to allow to be all more or less equally correct.)
Matthew Reeve said,
October 12, 2020 @ 3:12 am
There is a recent debate about the choice between dependency and phrase structure (=constituency grammar) in the online journal Language Under Discussion (https://journals.helsinki.fi/lud/article/view/223). For obvious reasons, I declare an interest!
AntC said,
October 12, 2020 @ 6:32 am
@myl comment a ternary structure for [three large boxes]. But if only binary trees are allowed …
And wp on dependency grammar says "Tesnière, however, argued vehemently against this binary division, preferring instead to position the verb as the root of all clause structure. Tesnière's stance was that the subject-predicate division stems from term logic and has no place in linguistics."
Ternary vs binary ought to be a non-issue. (Or at least it isn't an issue in 'term logic': Tesnière just didn't looked hard enough.) In term logic we represent a predicate of (say) three arguments as a term of one argument that returns a predicate of two arguments. And we can freely reorder those arguments using some tracking mechanism such as variables in lambda calculus — this is Montague grammar. (If you want to be nitpicky, strictly 'predicate' is a term of one argument; a term over more than one argument is a 'relation'; but most formal logicians use 'predicate' to include 'relation', "where the meaning is obvious".)
Surely subject-predicate has a place in at least the morphology of Indo-European languages: the finite verb agrees in person and number with the grammatical subject. Or does Tesnière have in mind semantic roles vis-a-vis the verb like agent vs patient vs instrument etc in 'deep structure' irrespective of realisation as grammatical subject/active vs passive?
Then yeah as @Michael points out, mapping from dependency structures to Phrase Structure needs extra info not in the dependency tree.
Michael Watts said,
October 12, 2020 @ 10:23 am
I'd like to expand on these with the example sentence "I'll meet you tomorrow behind the shed at 5 o'clock."
Without taking any position on the rest of the sentence, it seems obvious to me that there are three constituents, "tomorrow", "behind the shed", and "at 5 o'clock", which are all fully parallel in terms of the sentence structure. They appear in the same way, modifying the verb without needing to be licensed by it; none of them depends on any of the others; and they form an example of free word order (!) in English:
So, in my eyes, the structure associated with this sentence must place all three of them as the equal children of some other node, which immediately rules out a binary tree.
Michael Watts said,
October 12, 2020 @ 10:25 am
Hmm, it looks like I accidentally started a new <blockquote> after my 6 examples instead of finishing them with a proper </blockquote>.
If the comment above could be edited, I would appreciate it.
Daniel Barkalow said,
October 12, 2020 @ 3:55 pm
As I recall, despite the title looking like something Chomsky would come up with and drawing straight lines, Lerdahl and Jackendoff (1983) actually ends up with something much more like a dependency grammar than a constituency grammar. Like, the relationships further up the structure are relationships that the heads of those constituents would have to each other, rather than higher constituents being qualitatively different from any of the individual heads.
Daniel Barkalow said,
October 12, 2020 @ 4:11 pm
@Michael Watts:
My preference for natural language grammar is based on units that are lists alternating between optional nested structure and individual morphemes (with some slightly fancy rules for how to pronounce the thing that allow morphemes to affect word order instead of making sound); I'd parse that as [[I] 'll meet [you] 0 [tomorrow] at [5 o'clock] behind [the shed]], with all the things at the end in the same relationship to the overall structure.
That said, if you rotate this structure 45 degrees clockwise, it's a binary branching tree, where a child of a right branch aggregates its information upward and a child of a left branch summarizes itself, so the difference between binary branching and highly n-ary branching is really your mathematical formalism, not an essential property of your theory.
Michael Watts said,
October 12, 2020 @ 4:25 pm
The linked list is ordered; the tree is not. That allows the linked list to be viewed as a tree, by converting priority within the list into depth within the tree.
But the unordered nature of the tree corresponds perfectly to the completely free word order of these constituents within the sentence. The linked list tends to suggest that word order is constrained.
AntC said,
October 12, 2020 @ 10:36 pm
@Michael's examples exhibit free word order only up to a point (Lord Copper).
* I'll meet you at o'clock the tomorrow behind shed 5.
('… behind shed 5' might be a valid PP, but as a reordering of the example, it's mangled morphemes from different phrases.)
So because word/morpheme order is significant in at least some places in nearly all languages, an adequately descriptive tool must be able to capture that. It also needs a mechanism (node labelling?) to say the constituents/sub-phrases at this level, can be reordered (inter-reordering) even though each sub-phrase in Michael's examples cannot (no intra-reordering), let along mingling/mangling components from different sub-phrases.
AntC said,
October 13, 2020 @ 2:04 am
@Matthew the choice between dependency and phrase structure
I'm working through the paper you link to. Section 1 "the syntax community recognizes no third option" fails to consider Model-Theoretic syntax. See my link to Pullum's article in a comment above. Not sure why the author excludes logicians/algebraists or Computer Scientists from the "syntax community". There's heaps and heaps of other possible models.
It might be that at some very high level of abstraction the nuances between these descriptive or specificatory devices disappear. But at that same stratospheric level, the distinction between dependency grammars vs phrase-structure disappears also — as we're discussing on thread.
Then another dimension along which we might compare models is whether they generate sentences left-to-right or generate some 'deep structure' which is then subject to order-changing transformations — which would be the Syntactic Structures model, or Montague grammar's variables and lambda-binding.