Speech and silence
« previous post | next post »
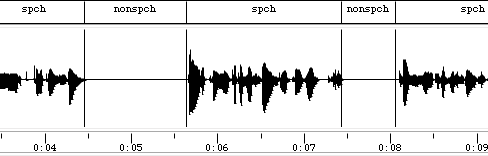 I recently became interested in patterns of speech and silence. People divide their discourse into phrases for many reasons: syntax, meaning, rhetoric; thinking about what to say next; running out of breath. But for current purposes, we're ignoring the content of what's said, and we're also ignoring the process of saying it. We're even ignoring the language being spoken. All we're looking at is the partition of the stream of talk into speech segments and silence segments.
I recently became interested in patterns of speech and silence. People divide their discourse into phrases for many reasons: syntax, meaning, rhetoric; thinking about what to say next; running out of breath. But for current purposes, we're ignoring the content of what's said, and we're also ignoring the process of saying it. We're even ignoring the language being spoken. All we're looking at is the partition of the stream of talk into speech segments and silence segments.
Why?
Well, suppose the following things were true:
- Accurate automatic speech/silence partition of audio recordings is possible.
- The distributions of the resulting segment durations, and of sequences of these segment durations, are lawful and are well characterized by simple models with few parameters.
- Factors such as fluency, speaking style, physiological state, etc., affect the rhythms of speech and silence in ways that affect these parameters.
- As a result, automatically-determined parameter estimates can be used to quantify useful estimates of these factors — at least under controlled conditions, and perhaps in combination with other sorts of measures.
In fact, I believe that all four of those things are indeed true. This morning, I'll provide some evidence bearing on points (1) and (2). [If you're not interested in speech production or speech technology, and tolerant of modest doses of exploratory data analysis, you might want to turn to some of our other fine posts…]
"Speech activity detection" is by no means a new idea, but as in other areas of speech technology, the performance of speech activity detectors (SADs) has gradually improved. Neville Ryant has recently built a series of speech activity detectors that work very well indeed — his most recent effort seems to be a significant advance on the state of the art, in terms of noise immunity and robustness across recording conditions. (In due course, he'll describe it in a conference publication and release an implementation as open-source software.)
But for clean speech, more conventional approaches work quite well. For this morning's little experiment, I've used a system that Neville built a few months ago, which has been widely used for internal tasks at the Linguistic Data Consortium. This system uses a "hidden markov model" for broad phonetic classes, based on a conventional set of acoustic features calculated 100 times a second; the results are merged into speech and nonspeech (here = silence) regions, subject to constraints on minimum region lengths. It was trained on a published corpus of English conversational speech for which hand segmentation is available.
I've configured it for minimum (speech and nonspeech) segment durations of 100 msec, and applied it to a variety of collections of recorded speech, with excellent results. Here's a few seconds from the start of one such collection:

This happens to come from the start of the dedication and introduction to the Librivox reading of Amor de Perdição (1862) by Camilo Castelo Branco, which I've been looking at as part of an effort to learn something about the phonetics and phonology of Portuguese. If you want to know what it sounds like, a phrase-by-phrase presentation of the Dedicatória is here.
Today, we only care about the durations of the speech and silence segments in the Introduction and the first 12 chapters (all that's now available) — a total of about 3.25 hours of audio, comprising 5614 speech segments and (because I left out the leading and trailing silences in each recording) 5601 silence segments.
Here's a histogram of the durations of the speech segments:

And a histogram of the durations of the silence segments:

How should we characterize these distributions? For distributions of durations, the obvious place to start is the gamma distribution, characterized by a shape parameter k and a scale parameter θ:

Given a sample of numbers that might have come from a gamma distribution, we can estimate the shape parameter and scale parameters, and plot the resulting approximation to the empirical distribution. Here's how it works (quite well) for the speech segments in this case:

And for the silence segments:

To the extent that there are problems with fit, it's because we're actually looking at a mixture of different cases. Given a minimum segment duration of 0.1 seconds, some of the silent segments are actually within-phrase stop gaps and so forth, while the others are silent pauses between phrases — and similarly, some of the speech segments are cut up by such boundaries. We can see the signature of this in a histogram of silence-segment durations at a finer time scale:

The default settings for the SAD that I used require a minimum duration of 300 msec for nonspeech segments and 500 msec for speech segments — this gives good results when the goal is to divide the input into convenient breath-group-like phrases, e.g. for subsequent transcription. I set the thresholds lower because I wanted to see the shorter-duration end of the distributions as well.
For this data, the approximate dividing-point between the within-phrase and between-phrase silences is about 180 msec — but a better approach would be to divide silent-segment candidates into two categories based on a richer set of properties than mere duration.
Anyhow, I believe that I've supported the plausibility of points (1) and (2) above — leaving for another day the distribution of segment sequences, as well as the issues raised in points (3) and (4).
mgh said,
January 12, 2013 @ 8:00 pm
A sort of null hypothesis is that the duration of a speech segment simply reflects the punctuation in the text (periods, dashes, commas, parentheses). Can you look at what fraction of pauses reflect features of the text rather than of the speaker?
[(myl) The correspondence of phrasing in speech to punctuation in writing is in general not very good — there are many phrases not bounded by punctuation, and a fair fraction of marks of punctuation don't correspond to spoken phrase boundaries. (See e.g. Geoff Nunberg's The Linguistics of Punctuation.) And a similar shape (though generally not quite as good a gamma-distribution fit) is found in extemporized speech, e.g. here the speech-segment durations in about 3.3 hours of Khan Academy videos:
]
GWS said,
January 13, 2013 @ 5:34 am
Murke's Collected Silences. Worth a read.
GeorgeW said,
January 13, 2013 @ 8:51 am
mgh: Don't periods and commas reflect pauses pauses in speech?
[(myl) There are lots of pauses not marked by periods and commas, and plenty of periods and (especially) commas that don't correspond to pauses.
From the Portuguese novel-reading featured in this post, here's the first sentence of the text with pauses indicated with slashes:
Domingos José Correia Botelho / de Mesquita e Meneses, / fidalgo de linhagem e um dos mais antigos solarengos de Vila-Real de Trás-os-Montes, / era / em 1779, / juiz de fora de Cascais, / e nesse mesmo ano casara com uma dama do paço, / D. Rita Teresa Margarida Preciosa / da Veiga Caldeirão Castelo Branco, / filha dum capitão de cavalos, neta de outro / Antônio de Azevedo Castelo Branco Pereira da Silva, / tem notável por sua jerarquia, / como por um, / naquele tempo, precioso livro / acerca da Arte de Guerra. /
This sentence has 14 internal phrasal pauses, 9 of which correspond to commas; it has 10 internal commas, 9 of which are marked with silent pauses.]
Myl: Could pauses also be used to distinguish language, dialect, speaker?
[(myl) I'd be surprised if there were stable connections to language or dialect, except insofar as there are associated cultural/stylistic differences. And individual speakers will vary a lot depending on circumstances, but in a well-defined context, there would probably be stable differences among speakers.
But all that is just a guess, and could turn out to be wrong.]
Rod Johnson said,
January 13, 2013 @ 9:56 am
Too bad this corpus is read texts and not spontaneous speech (I guess my own bias is showing there–I'd be interested in seeing how this connects to various prosodic accounts of phonology). I think it would be interesting to look for prosodic units, as delimited by pauses. I would think these pauses if they were there, would be quite short–sub 0.2 sec. It would also be interesting to try to build a hierarchical model, with longer pauses delimiting larger units, which would contain shorter pauses delimiting lower-level units, and so forth.
John Roth said,
January 13, 2013 @ 9:57 am
mgh: it used to be true that punctuation represented directions to someone reading aloud for pauses and intonation, and it still is for scriptwriting. However, today it's far more grammatical. For example, the apostrophe that's used for genitives has no reflection in speech; the same is true of the period in abbreviations.
Michael W said,
January 13, 2013 @ 3:19 pm
Speaking of automated detection of silence, I'm curious about how noise gating might affect language processing or comprehension. I was listening to a podcast recently that was recorded with very noticeable noise that dropped out when the speaker was talking, and it was harder to listen to. I probably wasn't conscious of it between some phrases (or the delay was set high enough) but it seems such a distraction might prove a significant hindrance to understanding.
mgh said,
January 13, 2013 @ 7:24 pm
Thanks for the responses. I should say that I like the idea that pauses can be used to quantify some feature of the speaker (mood, fluency, age, whatever).
But if 9 out of 14 pauses in the first sentence correspond to punctuation, then the prediction is that most speakers will share them, while the remaining 5 pauses will be speaker-dependent (and thus more interesting).
It might be worth testing that prediction by having many speakers record the same text. Are such recordings already available? If not, maybe it would be worth asking LL readers to contribute them.
[(myl) Among other sources for multiple text performances, the Librivox site offers several different readings for its more popular offerings.]
Kenny Easwaran said,
January 14, 2013 @ 11:08 am
That's interesting – this helps point out that there don't appear to be any languages in which silence is phonemic. It seems like it theoretically could be, but I suppose that without some sort of constant-time constraint on phonemes, it would tend to very quickly disappear in fluent speech.
Lane said,
January 16, 2013 @ 4:46 pm
I know this is problaby useless information in this context, but just in case it matters, on this page,
http://languagelog.ldc.upenn.edu/myl/ADP00a.html
line 39, the text reads "aos 26 de Septembro de 1861", but she reads "aos vinte e quatro [24] de Septembro de 1861".
Dar said,
January 20, 2013 @ 11:23 am
The distributions, temporal behavior, and interpretation of speech/silence sequences will also be highly correlated with the style of speech – read text, prepared monologue, and various flavors of dialog and conversations.