Justin Bieber Brings Natural Language Processing to the Masses
« previous post | next post »
Forget Watson. Forget Siri. Forget even Twitterology in the New York Times (though make sure to read Ben Zimmer's article first). You know natural language processing has really hit the big time when it's featured in a story in Entertainment Weekly.
Melissa Maerz's "Scandals: Measuring the Impact on a Career" (in today's hardcopy edition of EW), describes how natural-language-processing [sic] technology "analyzes words used on Twitter and Facebook", allowing entertainment industry types to track opinions in the fan base. Apparently there was a serious outcry among "real Beliebers" recently when sweet, innocent Justin was accused of less-than-innocent activities in the restroom of a concert venue, purportedly leading to a bouncing baby mini-Justin. Bieber's handlers took advantage of automated sentiment analysis to keep tabs on the reaction, and they were no doubt relieved when reactions trended upward in volume and positive toward their celebrity, i.e. the outcry was against the accuser, not against Bieber. The article quotes a "top celebrity crisis management consultant" as commenting, "People are so engaged with social media that you just can't ignore it anymore".
This observation will be no surprise to the people who attended last week's Sentiment Analysis Symposium in San Francisco, an industry-oriented event organized by text analytics maven Seth Grimes. The event featured a practical sentiment analysis tutorial by Language Log contributor Chris Potts, a set of industry and academic research talks, and, as the main feature, a day of presentations, panels, and business card dissemination by vendors, clients, researchers, and others working in this space.
Now, on the one hand, as a natural language processing guy, I'm excited by this surge in attention to NLP thanks to sentiment analysis, and more generally by the growing public awareness that human language technology is out there in the real world helping people do things they care about, up to and including helping save lives. On the other hand, as I pointed out in my own talk at the Sentiment Analysis Symposium, some of what's going on in sentiment analysis, coupled with this surge in interest, makes me a little wary of history repeating itself. Yes, you can put together a system for sentiment analysis by engineering in a bunch of human knowledge and heuristics (awesome is positive, sucks is negative; more positive words means more positive sentiment), which seems to be a popular approach right now. But it's awfully hard to engineer in enough knowledge to handle all the variability and context dependence you see even in relatively formal human language use, much less in social media. (Unpredictable is bad in car steering, but good in movie plots. There's a big difference between saying something is shit and saying it's the shit. And, as I learned at the symposium, even the gushily positive breakthrough is negative in some contexts, like discussions of toilet paper. I'm debating whether that last one is something to add to my cocktail party chit-chat arsenal, or whether it's better kept to myself.)
Those of us who have been in the field for a while have seen this story before. Import human knowledge by hand or from resources like dictionaries; program up rules and heuristics; run on some data; make big claims. It doesn't end well. In the leading textbook on artificial intelligence, authors Stuart Russell and Peter Norvig describe the 1980s' rise of an AI industry built on knowledge engineering approaches, and then note the ensuing "'AI Winter', in which many companies fell by the wayside as they failed to deliver on extravagant promises."
Ok, yes, running on huge amounts of data is a difference from 30 years ago, because it gives you an opportunity to get a sense of trends amidst the noise, even if your system is imperfect. Indiana's Johan Bollen articulated this well when asked about unexpected variability of word meanings in a recent NPR interview. But knowledge-based approaches are nonetheless rife with gaps in their knowledge, the inability for experts to anticipate the unexpected, and opportunities for systematic errors, like registering kind and just as positive words (leading to just the kind of error I alluded to with unpredictable and breakthrough), interpreting opinions about Steve Jobs as pertaining to the economy (an aberration Noah Smith noticed when predicting consumer confidence from tweets), or confusing Berkshire Hathaway's popularity with actress Anne Hathaway's (hat tip to Jason Baldridge for pointing out that example). Terry Winograd, author of SHRDLU, one of the earliest and most famous "language understanding" systems, ultimately sided with critics of old school knowledge based approaches; in this 1991 article he gave this compelling illustration of "gaps of anticipation":
The power plant will no longer fail because a reactor-operator falls asleep, but because a knowledge engineer didn't think of putting in a rule specifying how to handle a particular failure when the emergency system is undergoing its periodic test, and the backup system is out of order. No amount of refinement and articulation can guarantee the absence of such breakdowns. The hope that a system based on patchwork rationalism will respond appropriately in such cases is just that: a hope, and one that can engender dangerous illusions of safety and security.
If you're planning to bet on Berkshire Hathaway stock around Oscars time, take note.
My worry is compounded by the fact that social media sentiment analyses are being presented without the basic caveats you invoke in related polling scenarios. When you analyze social media you have not only a surfeit of conventional accuracy concerns like sampling error and selection bias (how well does the population of people whose posts you're analyzing represent the population you're trying to describe?), but also the problem of "automation bias" — in this case trusting that the automatic text analysis is correct. Yet the very same news organization that reports traditional opinion poll results with error bars and a careful note about the sample size will present Twitter sentiment analysis numbers as raw percentages, without the slightest hint of qualification.
What's the alternative? Twenty years ago the NLP community managed to break past the failures of the knowledge engineering era by making a major methodological shift from knowledge engineering to machine learning and statistical approaches. Instead of building expert knowledge into systems manually, we discovered the power of having human experts annotate or label language data, allowing a supervised learning system to train on examples of the inputs it will see, paired with the answers we want it to produce. (We call such algorithms "supervised" because the training examples include the answers we're looking for.) Today's state of the art NLP still incorporates manually constructed knowledge prudently where it helps, but it is fundamentally an enterprise driven by labeled training data. As Pang and Lee discuss in their widely read survey of the field, sentiment analysis is no exception, and it has correspondingly seen "a large shift in direction towards data-driven approaches", including a "very active line of work" applying supervised text categorization algorithms.
Nonetheless, I've argued recently that NLP's first statistical revolution is now being followed by a second technological revolution, one driven in large part by the needs of large scale social media analysis. The problem is that, faced with an ocean of wildly diverse language, there's no way to annotate enough training data so that supervised machine learning systems work well on whatever you throw at them. As a result, we are seeing the rise of semi-supervised methods. These let you bootstrap your learning using smaller quantities of high quality annotated training examples (that's the "supervised"), together with lots of unannotated examples of the inputs your system will see (that's the "semi").
Here's a quick graph based on the Association for Computational Linguistics (ACL) Anthology, showing the recent and marked rise of research papers containing "semi-supervised".
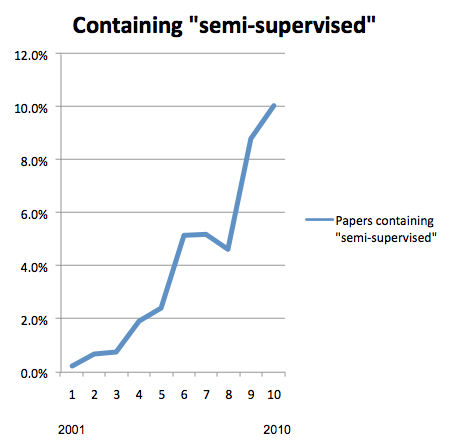
Looking at where we've been, and at the state of things now, I think the way forward is pretty clear: thanks to the flood of social media data, successful language technology is neither going to go all the way back to the good old fashioned knowledge engineering of the 1980s, nor are we going to be able to rely as heavily on annotated data and supervised machine learning as we have since the early 1990s. Natural language processing has finally hit the real world, and the real world changes. So does the language we use to talk about it. To keep up with it, we're going to need to exploit the knowledge resources that help, to generate high quality human annotation in manageable quantities, and to recognize that the Internet's most plentiful natural resource — unlabeled, naturally occurring human language — constitutes not only the problem we're trying to solve but also the data we need to be learning from in order to solve it.
As for sentiment analysis, by all means, let's continue to be excited about bringing NLP to the masses, and let's get them excited about it, too. But at the same time, let's avoid extravagant claims about computers understanding the meaning of text or the intent behind it. At this stage of the game, machine analysis should be a tool to support human insight, and its proper use should involve a clear recognition of its limitations.
Finally, what of Justin? It looks like he may be out of the hot seat; his accuser has reportedly dropped the paternity suit. Oh, and people just love his new hairstyle. Whew. That's one fewer crisis for us to worry about.
Full disclosure: Although I've tried to avoid inappropriate bias in my talk and in writing here about this topic, readers should be aware that my non-academic activities include advising and serving as lead scientist for Converseon, a social media agency.
John Lawler said,
November 19, 2011 @ 1:29 pm
For those interested, try this class: http://www.nlp-class.org/
Andy Averill said,
November 19, 2011 @ 3:55 pm
I would assume the vast majority of people who tweet about Justin Bieber are Beliebers to begin with. Is it that surprising that they believe him rather than his accuser? Most likely the people who think he's lying aren't going to bother tweeting at all. So I'm not convinced we learned anything from that experiment.
And the idea of buying or selling a stock on the basis of what social media indicate about the mood on Wall Street (as discussed in the interview you linked to) runs up against the efficient market hypothesis. By the time any great number of investors start expressing positive or negative feelings about a stock, it's generally too late to make money from that information.
Coby Lubliner said,
November 19, 2011 @ 9:32 pm
I don't get the [sic] on the perfectly logically hyphenated "natural-language-processing technology" paired with "old school knowledge based approaches," whose parseability rivals that of UK headlines.
[Sorry if this distracted from the point of the posting. The sic is there because "natural language processing" is the name of a field of study. Including the hyphens struck me as analogous to adding a hyphen in "quantum computing" or "information retrieval'. Hyphenating it isn't wrong, it's just non-standard. Though, on reflection, I can see how this is perfectly logical for someone to do if they're new to the terminology: compositionally "natural-language-processing technology" provides a nice, compositional interpretation as "technology that processes natural language". -PSR]
Glen Gordon said,
November 19, 2011 @ 11:28 pm
Programmers are trying desperately to put the cart before the horse since they haven't created sufficient enough AI to finally be able to *evolve* (not program directly but evolve indirectly through AI) a competent language processor that finally *understands* complex language *in context*. There's definitely a lot of hype but little theory on *how* this can be accomplished from what I've read. It seems that a lot of people in computer science are somehow hoping that random evolution is going to provide the answer at the end of the day but it strikes me as lazy daydreaming.
Ray Dillinger said,
November 23, 2011 @ 12:29 am
I worked on "Linguistic AI" systems professionally for several years. On the strength of logs and regression testing, a week's work can get you to 90% accuracy or better within a particular range of subject matter. Ninety out of every hundred of the things people say on any particular topic are things that you'll have logged other people saying within about a week's worth of working on logfiles.
Once somebody has put in that week of human work with a good pattern matcher and logs and regression testing, I have no real problem trusting their characterization of "positive" and "negative" for that topic, applied to an arbitrary larger volume of data, to be accurate to within 10%. But people don't want to put in a week's worth of human time to answer a research question.
The methodology we've got now fails miserably at several things. It fails to read complex sentence structures with multiple relative clauses. We use such sentences in intelligent discussion or persuasive argument, but not so much when we're just expressing which side of a controversy we're on. It fails to correctly resolve any kind of meta-reference to the speech itself. And it fails on pronouns (particularly cataphora) referring to any linguistic entity other than a simple noun.