The birth and death of typos
« previous post | next post »
Alexander M. Petersen, Joel Tenenbaum, Shlomo Havlin, and H. Eugene Stanley, "Statistical Laws Governing Fluctuations in Word Use from Word Birth to Word Death" (appearing in Scientific Reports, 3/15/2012):
We analyze the dynamic properties of 10^7 words recorded in English, Spanish and Hebrew over the period 1800–2008 in order to gain insight into the coevolution of language and culture. We report language independent patterns useful as benchmarks for theoretical models of language evolution. A significantly decreasing (increasing) trend in the birth (death) rate of words indicates a recent shift in the selection laws governing word use. For new words, we observe a peak in the growth-rate fluctuations around 40 years after introduction, consistent with the typical entry time into standard dictionaries and the human generational timescale. Pronounced changes in the dynamics of language during periods of war shows that word correlations, occurring across time and between words, are largely influenced by coevolutionary social, technological, and political factors. We quantify cultural memory by analyzing the long-term correlations in the use of individual words using detrended fluctuation analysis.
Here's the most striking result:
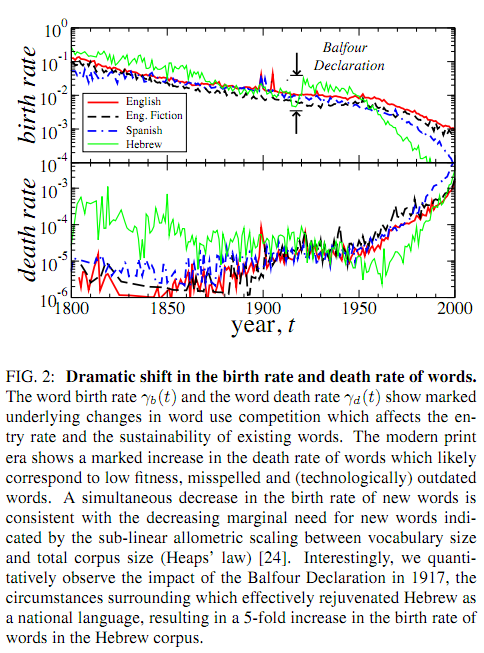
My first thought was that the decreasing "birth rate" of words was a trivial consequence of the necessarily downward-accelerated shape of type-token curves (like those exhibited here and here). When you first start scanning a stream of words (or insects, or random space-separated character strings, or pretty much anything else where individuals are instances of types), every individual that you see is a member of a new type ("species" or "word" or whatever). As the number of word tokens that you've seen goes up, the probability that the next token will be an instance of a new type obviously goes down; and this pattern will continue until you've seen every possible type (if that ever happens).
But the authors of this paper are much too smart to make this elementary mistake. Their definition of "word birth" and "word death":

–

There may still be a bit of a problem here, in that during the early years of collection, when no words have yet been (seen to be) born, the rate of apparent word birth will presumably be artificially inflated. How big this effect is, and how long it lasts, will depend on the details of the collection and perhaps on other details of their data processing. There's potentially a similar problem at the end of the time-series.
Since the data is available from the Google ngrams site, it's possible to replicate their work and examine this sort of thing in detail. One could also look at the results of various simulated random processes, to help clarify which aspects of their time-series reflect the nature of the underlying process, and which might be artefacts of their processing method.
One critical consideration, however, is that this paper is not really about words at all — it's about contiguous letter-strings in optical-character-reader output for scanned printed books. Different inflected forms of a word are different "words"; different word spellings are different "words"; word-fragments split typographically across lines are different "words"; typos are different "words"; OCR errors are different words". For expositional clarity, let's call the strings in the Google 1-gram corpus "g-words".
Given this, their results are surely impacted by the fact that the English "long s" lasts into the first few decades of their test period; the fact that English spelling was not fully codified until after the start of their test period; and the fact that printing technology, paper preservation, and other factors mean that the quality of Google's OCR for more recent works will be in general better. (And maybe editing and printing is really better now that it was in, say, 1900 — though I'm not convinced in advance that this is true…)
The authors recognize these issues to some extent in the paper:
The γb(t) and γd(t) time series plotted in Fig. 2 for the 200-year period 1800–2000 show trends that intensifies after the 1950s. The modern era of publishing, which is characterized by more strict editing procedures at publishing houses, computerized word editing and automatic spell-checking technology, shows a drastic increase in the death rate of words. Using visual inspection we verify most changes to the vocabulary in the last 10–20 years are due to the extinction of misspelled words and nonsensical print errors, and to the decreased birth rate of new misspelled variations and genuinely new words.
In other words, essentially all of the "drastic increase in the death rate of words" is in fact due to changes in the rate of mistakes at various stages of the data production process — spelling, editing, type-setting, and optical character recognition — that leads from the history of language to the lists of strings in the Google unigram corpus. And some portion — maybe most — of the "dramatic" decrease in the birth rate of g-words is also really a dramatic decrease in such book production and data processing errors, which have nothing to do with the life or death of "words" in the linguistic sense at all.
Chris Shea in the Wall Street Journal has a reasonable take on this, I think — duly impressed by the potential value of newly accessible linguistic data, and duly skeptical of the value and interpretation of specific observed patterns ("The New Science of the Birth and Death of Words: Have physicists discovered the evolutionary laws of language in Google's library?", WSJ 3/16/2012). He was most impressed by a "tipping point" observation:
The authors even identified a universal "tipping point" in the life cycle of new words: Roughly 30 to 50 years after their birth, they either enter the long-term lexicon or tumble off a cliff into disuse. The authors suggest that this may be because that stretch of decades marks the point when dictionary makers approve or disapprove new candidates for inclusion. Or perhaps it's generational turnover: Children accept or reject their parents' coinages.
Or perhaps the referents and sources of topical g-words — presidents, kings, battles, laws, authors, inventions, slogans — fade in and out of cultural focus. I'd be very surprised to learn that dictionaries have anything to do with this phenomenon; and slightly less surprised to learn that generational rebellion plays a significant role. Luckily, it's an empirical question — given a systematic survey of what kinds of g-words have tipped which way when, we can evaluate which processes are responsible for how much of the effect (and how strong the effect is to start with).
And even better, we've all got access to the data that allows this kind of follow-up to be done!
Mr Punch said,
March 18, 2012 @ 10:09 am
It's interesting that besides the Balfour Declaration, the foundation and growth of the State of Israel appears to have had a significant impact on Hebrew. I'm surprised to see a clear decline in "births" and rise in "deaths," as compared to earlier decades and to other languages.
Sil said,
March 18, 2012 @ 10:59 am
@Mr Punch
I'll preface this by saying I have no real knowledge of Israeli history, but it seems like there's a relatively simple explanation for the birth and death rate change after the foundation of the state of Israel. If Hebrew-speakers had previously lived in places with other predominant languages, they would likely have adopted bits and pieces of those other languages, which may have showed up as new words in the data here. When Israel became an accepted country with Hebrew as its official language, there may have been a reduction in the use of (or introduction of) such borrowed words.
BZ said,
March 19, 2012 @ 12:18 pm
@Sil,
I would think the effect should be the opposite. Since until the founding of the state of Israel Hebrew was mostly spoken in rituals with set expressions and not much variability, there should have been very low birth and death rate of words, while as a living language constantly spoken by a large population, plus a large inadequacy of existing vocabulary to refer to modern concepts, there should be huge initial turnover, probably continuing to this day as borrowings from German (and/or Yiddish), English, Russian, and Arabic fight with each other to be accepted into common use.
Zackary Sholem Berger said,
March 19, 2012 @ 12:59 pm
Attributing a spike in the Hebrew-word birth rate (if that's what it really is*) to the Balfour declaration of 1917 is cutting things too fine. There was quite a bit going on in the Jewish world at the time, including migration of Yiddish speakers and Hebrew writers between Europe, the US, and Palestine, *and* (probably more/as important) the increasingly vibrant Hebrew-language press in Europe and Palestine.
*Google still has problems distinguishing between Hebrew and Yiddish, so confusing the two might just give an indication of increased activity in the "Hebrew-letter" press…
Joel said,
March 25, 2012 @ 9:40 pm
Remember that these are relative frequencies and taken from books. Borrowing and invention of words is still very common in Modern Hebrew. However the rate of g-word birth and death in Hebrew would have been influenced by the genres in print. A lot of the works prior to the state were literary or poetic, when not rabbinic. As far as Hebrew is concerned, being a "new language", the genre make-up of the corpus should be investigated.
In addition, orthographic conventions in Hebrew — particularly regarding the use of matres lectionis — have been institutionally modified over the period.
Mark, you suggest that "during the early years of collection, when no words have yet been (seen to be) born, the rate of apparent word birth will presumably be artificially inflated." However, the authors deliberately determine birth by considering data from 1700, but report from 1800. Of course, the quantity and variety of books available in 1700-1800 would presumably be smaller and markedly different to those in 1800-1900.
Finally, I am a little curious whether there are any reviewers at Scientific Reports with a background in linguistics, especially when the article is published as a Statistics / Applied Physics / Evolution paper.
Logbook said,
March 28, 2012 @ 12:25 pm
[…] → Some physicists analyzed 10,000,000 words from 200 years and now understand linguistic evolution. According to my linguist colleagues, this happens every few years. The answer is always the same: when you reduce things enough, you can make all kinds of claims. The Language Log has more. […]