Automatic classification of g-dropping
« previous post | next post »
Over at headsup: the blog, fev recently pondered variation in transcription practice ("Annals of g-droppin'", 6/6/2011). He starts by noting that the same paper edited the same quote, in the same AP story, to have -in' in some but not all gerund-participles in one version, but -ing throughout in another version. And his main concern is with the socio-political subtext of the choice to use eye-dialect in some cases and not in others:
It's worth puttin' the question to the AP (and/or your own political writers). What exactly are you trying to show about Palin's speech, and how consistent can you credibly claim to be about it — either within a single sentence of hers or among candidates who may have those or other speech features despite their necktie-wearin' formality?
We've had quite a few posts on this dimension of linguistic variation and its socio-cultural associations. A sample:
"The internet pilgrim's guide to g-dropping", 5/10/2004
"Empathetic -in'", 10/18/2008
"Palin's tactical g-lessness", 10/18/2008
"Pickin' up on those features also", 22/29/2008
"Pawlenty's linguistic 'southern strategy'?", 3/17/2011
"Symbols and signals in g-dropping", 3/23/2011
I need to confess, though, that the evidence in some of these posts is barely a step up from anecdotal. Thus in my post "Empathetic -in'", I wrote:
Other things equal, the rate of "g-dropping" goes up with lower social class; goes up with greater informality; and goes up with more positive affect (e.g. joking vs. arguing). Without using a loaded word like "slumming", and indeed without raising the question of consciousness at all, we should note that every one of us is making many choices about self-presentation every time we open our mouth, and in particular we add a brush-stroke to our self-portrait every time we choose a pronounciation for the English gerund-participle suffix -ing.
In the first 40 minutes of the first presidential debate, Senator Obama used 84 gerund-participles, and dropped 8 g's. A g-dropping rate of about 10% is not at all out of line for someone in his position — in comparison, in the same period of the same debate, Senator McCain dropped 10 g's in 66 opportunities. (In both cases, I've left out all instances of the sequence "going to", which is especially interesting but also behaves in a special way.)
N of 84 or 66 is not too bad — but my next sentence was
The key thing, though, is not the percentage but the positioning.
And as we start to divide up the instances according to various aspects of the context, the numbers get small in a hurry.
So I'm happy to say that Jiahong Yuan and I have demonstrated, at least in principle, the feasibility of automating the classification of gerund-participle pronunciations. Our poster from a recent speech production workshop is here: "Automatic Detection of 'g-dropping' in American English Using Forced Alignment".
We started with 200 +ing words randomly selected from the Buckeye Corpus, 100 that were phonetically labelled with [ ih n ] and 100 that were labelled with [ ih ng ]. Since those labels were imposed by a human listener, and human phonetic judgments are by no means intersubjectively uniform, we had 8 other native English speakers (with at least some phonetic training) perform a forced-choice binary judgment on each of the tokens.
We then asked a speech-recognition system to make the same binary forced-choice judgment on the same tokens. Overall, the human listeners (including the Buckeye transcript) agreed with one another, on average, about 86% of the time; the automatic procedure agreed with the human listeners, on average, about 85% of the time. (A detailed matrix of pair-wise agreement is here.)
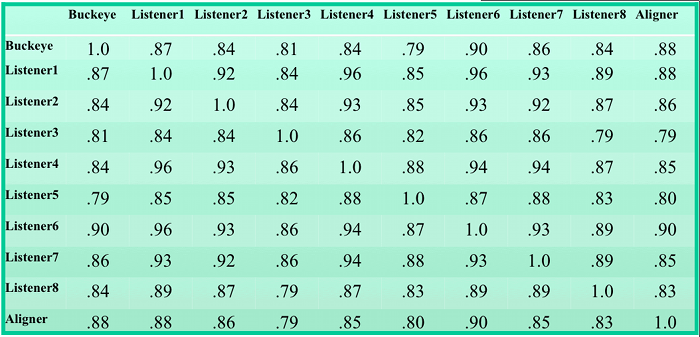{kind=link}
We can no doubt improve this by doing some categorization-specific discriminative training — both for the humans and for the machine — but it's already good enough to go forward with. Specifically, we'll be able to automatically classify g-dropping behavior in arbitrarily large collections of transcribed political speeches and debates.
Chris said,
June 12, 2011 @ 9:44 am
Did I hear you say you're going to build us a free online tool that will ingest a sound file and produce an analysis of g-dropping? Gee, thanks!
[(myl) Some day. There's already an online tool for doing forced alignment. It would be easy enough to add the g-dropping tool, and the t/d deletion tool, etc. — once those are robust enough to rely on.]
Sili said,
June 12, 2011 @ 10:43 am
Oh dear. Chomsky is soooo gonna hate you know.
Congrats! That's awesome.
What's next? A disfluency counter?
dw said,
June 12, 2011 @ 12:37 pm
I find it interesting that, in your presentation, you say that the Mandarin speakers performed poorly, and mention that Mandarin does not have a tense-lax vowel distinction.
Did you note this because some Southern and Southern-influenced speakers have the FLEECE vowel, rather than the KIT vowel, before /ŋ/ in words like "king"?
[(myl) It's complicated.]
Ran Ari-Gur said,
June 12, 2011 @ 1:16 pm
Re: "The distance between the two models reaches its peak at the middle state, and it is larger on the left side (the vowel side) than the right (the nasal coda side)": So — to a first approximation — does this mean that the actual greatest difference between /ɪŋ/ and /ɪn/ is at the transition from the vowel to the coda? Or that the most informative difference is at that point, because the points on either side are somewhat redundant to it? Or something else entirely?
(Sorry if this is a totally stupid question. I Googled and Wikipedia'd enough to hopefully get a vague, tenuous sort of idea of everything in the poster, but obviously I'm not in its target audience!)
dw said,
June 12, 2011 @ 1:32 pm
@Ran Ari-Gur:
I would have guessed that the most common North American realization of in' would be a syllabic nasal [n̥], because most speakers have the weak-vowel merger.
Ellen K. said,
June 12, 2011 @ 2:32 pm
I was really wondering about "We've has quite a few posts" (beginning of second paragraph) till I realized D and S are next to each other on the keyboard. Okay, now it makes sense. :)
Mark F. said,
June 12, 2011 @ 3:07 pm
dw – You definitely do get the syllabic [n] in words like puttin' or cuttin'. But I think there's an actual vowel in, say, walkin' or singin'. I think it has to do with the point of articulation of the previous consonant, or something, but it seems like a majority of words do have a vowel in the realization of in'.
Of course, this is my subjective judgment so make of it what you will.
James Kabala said,
June 12, 2011 @ 5:23 pm
If I were a newspaper stylebook editor, I would hand down as a solemn decree: "G-dropping and similar vernacular pronunciations are to be ignored in transcriptions. Standard spelling is to be used in all such cases. Apostrophes in place of dropped sounds are not to be used. The only exception is if the quotation is not of a spoken remark but of a written statement in which (for whatever reason) the original writer himself/herself dropped letters and used an apostrophe."
Any other rule makes the apostrophe a weapon to be used against disfavored persons or groups while identical pronunciations used by favored persons or groups are ignored. You don't have to be a Sarah Palin fan (I am not one) to recognize that the media has chosen to portray her as a constant g-dropper and other politicians as not g-droppers even when they are.
will said,
June 12, 2011 @ 8:40 pm
But Sarah Palin drops her g's on purpose (or at least deliberately adopts a lower register where that's likely to happen). So does Obama, on occasion. I think it's fair game for the media to note the g-dropping when speakers are deliberately being informal, though they shouldn't "play gotcha" when it's just a natural feature of their normal speech
Keith M Ellis said,
June 12, 2011 @ 8:41 pm
This brings to mind a mini-controversy I was involved with (well, initiated) over at [authorially redacted]. Someone had posted a link to a video of an eccentric woman who hosted a public-access television show. It was an interesting link because she was truly eccentric, espousing a wide variety of extremely quirky ideas in a very animated and memorable fashion.
And someone decided to make a transcript of the video.
And the eccentric woman in the video was african-american who spoke mostly in her native dialect.
The transcriber faithfully—one might say obsessively—transcribed her usage and dialect very close to phonetic exactness.
In my opinion, this was entirely unnecessary and unrelated to what made her and her video interesting. Or, at least, it should have been unrelated to what made them interesting.
It should be noted that [authorially redacted] is generally progressive and (at least it fancies itself) tolerant. When I objected to the the choice of phonetic translation, and suggested as gently as possible that the choice revealed at the very least a possible latent prejudice, great hulking mountains of offense were taken. I know that no one likes to be accused, even gently, of any sort of bigotry. But, still, it seemed to me like something that ought to be both called out and examined.
And the general matter is quite interesting, isn't it? Usually, reporters and editors do not preserve common usage errors and deviations from the prestige dialect. It's very interesting and revealing when they choose to do so. No doubt, they'd aver that this is on the basis of "newsworthiness" and that they attempt to be as neutral as possible. But, of course, it is these media gatekeepers who determine far more than they want to admit what is and isn't "newsworthy" and they are as much creating an awareness of a public figure's non-standard usage by presenting it as-is as they are in giving the public information that the public wants.
D.O. said,
June 12, 2011 @ 9:47 pm
@James Kabala. Expanding somewhat on will's comment, there is no way you can put g back into "So how's that hopey, changey thing workin' out for ya?" It would be an abomination (though, as a matter of fact, this particular abomination is quite widespread).
GeorgeW said,
June 13, 2011 @ 6:22 am
@James Kabala: I agree.
@will:
GeorgeW said,
June 13, 2011 @ 6:27 am
Whoops, a premature Enter:
@James Kabala: I agree.
@will: The judgement that Palin, Obama or whoever is "deliberately" dropping their g's is subjective and, I think, inappropriate for a news report (unless the report is an analysis g-dropping more generally).
Trimegistus said,
June 13, 2011 @ 7:04 am
I'm with the mystic master of Kabala, above: just don't use it. It's like trying to write fiction in dialect. Unless you're a literary genius like Mark Twain, the result just makes it harder for the reader. Since few reporters are literary geniuses, they should stick to conventional spelling.
Ellen K. said,
June 13, 2011 @ 9:20 am
@D.O.
I disagree. I think writing ""So how's that hopey, changey thing working out for ya?" would be just fine. And certainly not an abomination. Even writing "you" instead of "ya", though I dislike it, would not be an abomination.
One could, I suppose, debate whether "ya" and "you" are the same word. I think, though, it's agreed that "workin'" and "working" are the same word, and I can't see how using standard spelling is an abomination, even where it's okay to use the non-standard spelling.
James Kabala said,
June 13, 2011 @ 9:27 am
Keith M. Ellis: The same was true of (for example) of the narratives of former slaves transcribed by the WPA in the 1930s. The interviewers meant well but apparently believed that perfect phonetic accuracy was required.
Will and D.O.: Yes, there are definitely are some borderline cases (the one cited by D.O. is one), but as a general principle GeorgeW (not THE George W, I assume) is correct. The question of deliberate g-dropping is in the eye of the beholder (and if Obama also does it deliberately, I bet it's a rare newspaper report that transcribes it that way).
[(myl) In the case of every American politician that whose speeches and interviews I've looked at, there's variation in g-dropping that correlates with audience and with content in the sort of way that I described here. There's ample evidence in 50+ years of sociolinguistic research that this is not just a feature of politicians, as discussed here. And as noted in the same post, D.H. Lawrence has Mellors use the opposition of warm vernacular -in' to the -ing of "cold, good English" in the 1928 novel Lady Chatterly's Lover.
Conscious intent is another question, but it's not (in my opinion) a very interesting one.]
Ran Ari-Gur said,
June 13, 2011 @ 12:29 pm
@James Kabala: How about other usages perceived as nonstandard or colloquial, that a person might deploy in speech but avoid in writing? Would you "hand down as a solemn decree" a rule that "have went" be corrected to "have gone", that "there's" be expand to "there is" or "there are" (as appropriate), and so on?
Journalists need to be aware of such issues, and to make sure that they're handling them neutrally (rather than letting their personal prejudices affect their transcriptions), but it seems impossible to craft any "solemn decree" that could remove the need for journalists to exercise good judgment.
Rodger C said,
June 13, 2011 @ 12:47 pm
@Ran Ari-Gur: I think what most people here would like to see is a transcription that's pretty much morphophonemic, as discussed by D. R. Preston in the classic "'Ritin' Fowklower Daun 'Rong." So no changing of verb forms, but also no painful rewriting of vowels as the transcriber hears them in his/her own dialect.
Mary Kuhner said,
June 13, 2011 @ 12:58 pm
I realize the line might be hard to draw, but if I were being quoted I'd like it like this: don't change what words I said, but don't spell them funny even if you think I pronounced them funny. So if I say "the wind done gone" you have to write that, but if I pronounce "nuclear" differently than you do, it still gets the dictionary spelling.
I doubt even Palin or Obama could tell us exactly when they are dropping 'g' for effect and when it just happens; I certainly don't think a reporter should try to read their minds and figure it out. If news consumers really want to know how the speaker sounded, audio is not that hard to find anymore–it's not as if the consumer's only access to the speech is through the written medium.
D.O. said,
June 13, 2011 @ 3:07 pm
@ Ellen K.: Obviously you disagree with me, as well as multitudes of others who spell this phrase regularily. However, I think, this spelling obscures the clear intent of the speaker and implies much more serious tone than intended.
James Kabala said,
June 13, 2011 @ 3:34 pm
Ran Ari-Gur: Rodger C. and Mary Kuhner say what I would have said, although I would add that if phonetic transcription were really done universally and consistently, I could live with it – but do you REALLY want to see a newspaper in which nearly every article features phonetic spellings and dropped gs? I think some people don't realize how common g-dropping actually is.
I actually am a bit surprised that real stylebooks don't (AFAIK) deal with this issue. Maybe it's because until recently politicians and businessmen were treated with deference and portrayed as perfect enunciators even when not, with nonstandard spellings reserved for quotes from entertainers and athletes in sections of the paper where stylebook rules are often looser anyway.
fev said,
June 13, 2011 @ 4:13 pm
@James: Many news stylebooks do deal with dialect issues, though they tend to leave a lot of leeway for individual decisions about relevance. I'll try to round up some of the relevant entries when time permits.
Stylebooks in general deserve more exploration than they've gotten. One really good examination is Cameron, Deborah (1996). Style policy and style politics: A neglected aspect of the language of the news, Media, Culture & Society, 18, 315-333.
And everyone should enjoy the Grauniad's entry under 'swearwords,' even if it no longer has the cartoon: http://www.guardian.co.uk/styleguide/s#id-3036085
Jon said,
June 13, 2011 @ 5:50 pm
There's also the British variation of pronouncing -ing as -ink. It's regarded as lower-class, urban, uneducated, and goes with pronouncing th as f, so the classic example is 'something' pronounced as 'sumfink'.
You also hear some people pronouncing -ing with a clear 'g' at the end, as -ingg. I've always guessed that this was hyper-correction, resulting from -in or -ink pronunciations being criticised with the complaint that "there is a 'g' at the end of '-ing'". But that's just a guess.
Ellen K. said,
June 13, 2011 @ 7:38 pm
Am I understanding right that the term g-drop, while it does refer to the spelling difference, it also refers to an actual change in the nasal consonant that ends the word?
For me, the difference is in the vowel. -ing = [in], -in' = [ɪn]. The -ing ending never has the [ŋ] of king. The "g-dropped" version simply has a different vowel.
And I seem to recall that variation coming up here in discussion in the past.
[(myl) Discussed at tedious length in the linked posts…]
Ellen K. said,
June 13, 2011 @ 7:43 pm
@D.O.
For you, does abomination mean "something not chosen", or "something dispreferred to something else"?
For me, it means something seen as extremely bad, awful.
So, how people typically transcribe "going" in that quote (or are you referring to the shorter phrase within the quote?) is no evidence at all to whether or not they find the alternative an abomination. Maybe your right and everyone or almost everyone agrees on "goin'" in that quote or phrase. That, though, gives you no evidence at all that they thing "going" would be an abomination.
You've no evidence that I disagree with anyone but you when I say that "going" would not be an abomination. Notice, I said nothing at all about which would be better. Only that the version you say is an abomination, I think is acceptable.
D.O. said,
June 14, 2011 @ 12:13 pm
Ellen K, I confess, the word "abomination" was a joke on my part. And I pointed out that many people disagree with me, not with you.
Elise M said,
June 14, 2011 @ 6:09 pm
Transcription is so hard to do impartially. Consider the way that Japanese tv media chooses to caption the dialogue of foreigners in katakana, even when the speakers are entirely fluent in Japanese… you could argue that they simply want to capture the "flavor" of the speakers' pronunciation, but it's hard to say that there are no latent prejudices there..