"Voiceprints" again
« previous post | next post »
"Millions of voiceprints quietly being harvested as latest identification tool", The Guardian (AP), 10/13/2014:
Over the telephone, in jail and online, a new digital bounty is being harvested: the human voice.
Businesses and governments around the world increasingly are turning to voice biometrics, or voiceprints, to pay pensions, collect taxes, track criminals and replace passwords.
The article lists some successful applications:
Barclays plc recently experimented with voiceprinting as an identification for its wealthiest clients. It was so successful that Barclays is rolling it out to the rest of its 12 million retail banking customers.
“The general feeling is that voice biometrics will be the de facto standard in the next two or three years,” said Iain Hanlon, a Barclays executive.
It's interesting — and a little disturbing — that the antique term "voiceprint" is being revived. This term was promoted in the early 1960s by a company aiming to show that appropriately-trained forensic experts could use sound spectrograms (in those days on paper) to identify speakers, just as they used fingerprints to identify the individuals who left them. That theory was profoundly misleading, and was effectively discredited at least from the point of view of the acceptability of such evidence in American courts — see "Authors vs. Speakers: A Tale of Two Subfields", 7/27/2011, for some details.
The Guardian/AP article goes further in promoting this bogus analogy:
Vendors say the timbre of a person’s voice is unique in a way similar to the loops and whorls at the tips of someone’s fingers.
Their technology measures the characteristics of a person’s speech as air is expelled from the lungs, across the vocal folds of the larynx, up the pharynx, over the tongue, and out through the lips, nose and teeth. Typical speaker recognition software compares those characteristics with data held on a server. If two voiceprints are similar enough, the system declares them a match.
But this is not to say that speech biometrics are invalid. As the cited post explains, in 1996 the National Institute of Standards and Technologies (NIST) began holding regular formal evaluations of speaker-recognition technology, with the result that we have credible evidence of major improvements in the underlying technology, and also credible methods for evaluating the actual performance of specific algorithms as applied to specific problems.
The most recent completed NIST "Speaker Recognition Evaluation" was in 2012, and the results are available on line. A good review of the past two decades has just been published — Joaquin Gonzalez-Rodriguez, "Evaluating Automatic Speaker Recognition systems: An overview of the NIST Speaker Recognition Evaluations (1996-2014)", Loquens 1.1 2014:
Automatic Speaker Recognition systems show interesting properties, such as speed of processing or repeatability of results, in contrast to speaker recognition by humans. But they will be usable just if they are reliable. Testability, or the ability to extensively evaluate the goodness of the speaker detector decisions, becomes then critical. In the last 20 years, the US National Institute of Standards and Technology (NIST) has organized, providing the proper speech data and evaluation protocols, a series of text-independent Speaker Recognition Evaluations (SRE). Those evaluations have become not just a periodical benchmark test, but also a meeting point of a collaborative community of scientists that have been deeply involved in the cycle of evaluations, allowing tremendous progress in a specially complex task where the speaker information is spread across different information levels (acoustic, prosodic, linguistic…) and is strongly affected by speaker intrinsic and extrinsic variability factors. In this paper, we outline how the evaluations progressively challenged the technology including new speaking conditions and sources of variability, and how the scientific community gave answers to those demands. Finally, NIST SREs will be shown to be not free of inconveniences, and future challenges to speaker recognition assessment will also be discussed.
Most of the NIST speaker-recognition evaluations have involved so-called "text independent" detection, where the task is to determine whether two samples of uncontrolled content come from the same speaker or not. For the biometric applications discussed in the Guardian/AP article, "text dependent" tasks seem to be more relevant, where the reference and the test utterances are supposed to be repetitions of a known phrase. An excellent recent discussion of this technology has also just been published — Anthony Larcher et al., "Text-dependent speaker verification: Classifiers, databases and RSR2015", Speech Communication 2014:
The RSR2015 database, designed to evaluate text-dependent speaker verification systems under different durations and lexical constraints has been collected and released by the Human Language Technology (HLT) department at Institute for Infocomm Research (I2R) in Singapore. English speakers were recorded with a balanced diversity of accents commonly found in Singapore. More than 151 h of speech data were recorded using mobile devices. The pool of speakers consists of 300 participants (143 female and 157 male speakers) between 17 and 42 years old making the RSR2015 database one of the largest publicly available database targeted for textdependent speaker verification. We provide evaluation protocol for each of the three parts of the database, together with the results of two speaker verification system: the HiLAM system, based on a three layer acoustic architecture, and an i-vector/PLDA system. We thus provide a reference evaluation scheme and a reference performance on RSR2015 database to the research community. The HiLAM outperforms the state-of-the-art i-vector system in most of the scenarios.
Here's a DET ("Detection Error Tradeoff") curve from that paper:
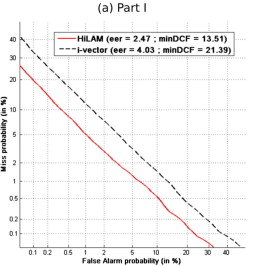
This plot shows what happens when you adjust the algorithm to trade off misses (where the two speakers are the same but the algorithm says they're different) against false alarms (where the two speakers are different but the algorithm says they're the same). The "equal error rate" — the point on the DET curve where the two kinds of error are equally likely — is 2.47% for their best algorithm, which they claim to be better than the state-of-the-art algorithms that are likely to be used in the commercial systems discussed in the article.
Of course, in a real-world speaker verification application, you would probably chose a different operating point, say increasing the miss probability a bit in order to let fewer imposters through. But in any case, a biometric method with this level of performance is clearly useful, though not exactly perfect.
AGNITiO is one of the vendors cited in the Guardian/AP article. There's a page on their site entitled "How accurate is voice biometric technology?", which explains the standard evaluation method clearly, but unfortunately the sentence "The charts below show the probability and accuracy of the AGNITiO voice identification engine, using both a pass phrase (text-dependent) and free-form speech" is followed, alas, by no charts… However, there's another AGNITiO page "Is speaker verification reliable?" which says that
In practice, the conditions surrounding the application, the setting of thresholds and the method of decision employed can impact the error rates in a significant way. It is not the same that voices are captured in an office environment using a land line, than to capture the same voices from a mobile (cellular) phone in situations where there is a lot of background noise such as in a car or in a public place. Therefore, it is risky to give statistics and error rates without knowledge of the concrete application. We can say, however, that for certain real applications the threshold can be set in a way that we have an false acceptance rate below 0.5% with false rejection rates of less than 5%.
Thus they are claiming to do a little bit better than the DET curve from Larcher et al. would allow, though the AGNITiO number seems to be a sort of guess about how things are likely to come out in a typical case, rather than the actual value from an independently-verifiable test. However, AGNITiO is clearly serious about testing its technology, as this presentation from the 2010 SRE workshop makes clear.
ValidSoft, another vendor cited in the article, claims that "ValidSoft’s voice biometric engine has been independently tested and endorsed as one of the leading commercial engines available in the market today", but they don't link to the independent tests or endorsements, and I haven't been able to find any documentation of their system's performance. There's a press release "ValidSoft Voice Biometric Technology Comes of Age" which says that
ValidSoft […] today announced that it has achieved its primary objective for its voice biometric technology of successfully being measured and compared with the world's leading commercial voice biometric providers and non-commercial voice biometrics research groups. As a result, ValidSoft clients are assured that they have access to a fully integrated, multi-layer, multi-factor authentication and transaction verification platform that can seamlessly incorporate world-leading voice biometric technology.
ValidSoft achieved its objective by successfully taking part in the prestigious National Institute of Standards and Technology (NIST) Speaker Recognition Evaluation. This evaluation is the most important and main driver for innovation in the field of voice biometrics, particularly security.
But they don't show us their DET curves, or any other quantitative outcomes, while (as you can see in the DET curve from one of the SRE 2012 conditions) there's a fair amount of spread in system performance:
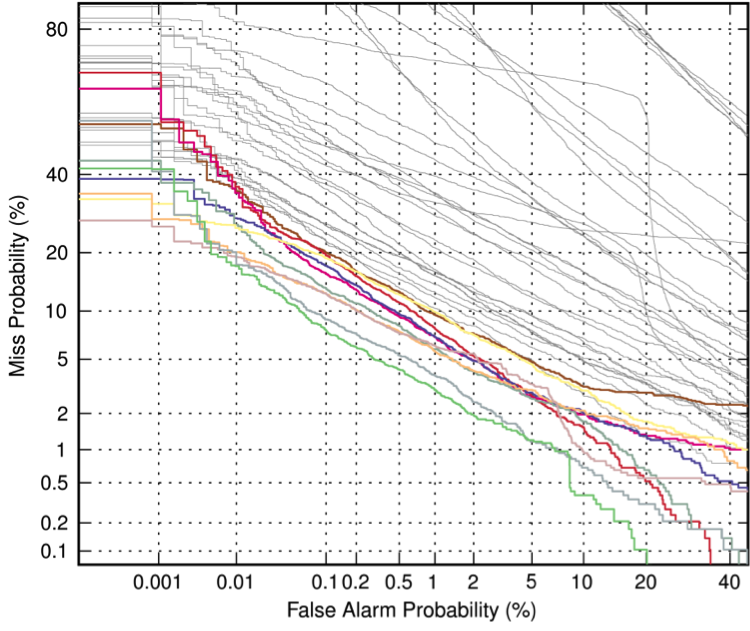
Anyhow, this is a completely different scenario from the "Deception Detection" domain, Here we know what the algorithms are, and there are independent benchmark tests that evaluate the overall performance of the state-of-the-art technology, and compare different systems in that framework. In the case of commercial speech-based deception-detection products, the algorithms are secret, and the performance claims are effectively meaningless (see "Speech-based 'lie detection'? I don't think so", 11/10/2011).
Note that Ulery et al., "Accuracy and reliability of forensic latent fingerprint decisions", PNAS 2011, found a 0.1% false positive rate with a 7.5% miss rate, so that in fact voice biometrics are now roughly as accurate as (latent) fingerprint identification, at least in some version of the speaker-recognition task. Obviously the error rates for comparison of carefully-collected full fingerprint sets should be a great deal lower.
[h/t Simon Musgrave]
Gregory Kusnick said,
October 14, 2014 @ 1:42 pm
Slightly off-topic, but I nominate "miss" and "false alarm" as unhelpful terminological oppositions per this recent post. AGNITiO's "false rejection" and "false acceptance" (or even plain old "false negative" and "false positive") seem more natural and informative in this context.
[(myl) Good point. "Miss" and "false alarm" make sense when you're talking about problem where the concept of "detection" is a good cognitive fit, like looking for mentions of entities of some specific category. But I think it's a bit different from the "sensitivity vs. specificity" case, in that there's not really any context where those terms are natural, and as a result, even biomedical researchers seem to have trouble remembering what they mean or at least which is which. In contrast, because there are familiar contexts where the terms miss and false alarm are intuitive, my experience is that members of the HLT community don't have any trouble remembering what they mean even in contexts like this one, where they're definitely not the terms that best fit the problem.]
trevor thomas said,
October 14, 2014 @ 4:18 pm
thanks for pointing out these summary papers for the text dependent and the remarkable progress that is being reported with the NIST 2012 tests when compared with the 2010 tests, progress which I was not aware of. However it would seem that the Barclays system, from Nuance, is a text independent system (http://www.finextra.com/news/fullstory.aspx?newsitemid=26192) and not a text dependent system, and in addition, according to this article, the caller need only engage in a few seconds of spech with the agent for verification to take place, so I don't believe that their system's DET curve can be anything like as accurate as the one you have presented taken from the NIST 2012 tests, which use between 20s and 160s of speech for the verification material.
[(myl) Certainly if it's a text-independent system based on a couple of seconds of input, it's hard to believe that the error tradeoffs are very good…]
chris said,
October 14, 2014 @ 8:02 pm
Was anyone in the tests deliberately attempting to disguise their voice or imitate someone else's voice? Both seem relevant to any potential security application of this technology. A system that works fine except when someone is trying to fool it is not a secure system.
Also, I assume it would be fairly simple to fool it with a sufficiently high-quality recording of the person whose voice is expected. As a biometric that leaves a lot to be desired.
[(myl) For verification applications, vocal disguise is not relevant since it won't help imitate a target. And the most obvious way to defeat the use of recordings is a challenge-response paradigm ("Repeat this phrase: blah blah blah", where the blah blah blah is generated from a potentially very large set. ]
Jon said,
October 15, 2014 @ 3:37 am
Chris's point about mimicry is important. The system vendors will have to prove that their systems cannot be fooled by a good mimic. Fraudsters will go to great lengths to break security systems, and some people will do it just for fun. To fool the fingerprint recognition systems on some computer keyboards, people have managed to create a rubber replica of a fingerprint based on a latent print.
What seems to be missing from the reports above is "don't know". There should be a confidence level attached to any identification, and below some threshold the system should refuse to identify. If the proportion of don't knows is high when there is a noisy background or a poor line, then the method may be impractical for many applications.
Lane said,
October 15, 2014 @ 5:21 am
Mark, I imagine I'm not the only reader sometimes just barely hanging on in my understanding of a post like this. For readers in a hurry, for generalists trying to scrape up information via Google on this stuff, and for the many of us who don't have the fluency in some of the statistical language, this kind of post (which also addresses a topic of wide interest) could really use an executive summary which you wouldn't mind a journalist virtually copying and pasting, something that sums up in unmistakeable language something like:
– voice-identification technology has indeed gotten a lot better
– but the term "voiceprint" suggests greater accuracy than it should
– voice-recognition systems are all over the map in their actually tested reliability
– private vendors of this stuff often make claims without the evidence a skeptical expert needs to evaluate; handle with caution
Or whatever you want the reader to take away, the reader (like me) who isn't as au fait with a DET curve as he should be.
Zubon said,
October 15, 2014 @ 3:53 pm
In a well designed system, using a recording should not work (or perhaps at most once). If the new audio matches the old audio exactly, the system should reject it as a likely recording. Humans do not repeat themselves that precisely.
The same applies to fingerprints. If you have two sets of fingerprint images that are exactly identical, it is far more likely that you have two copies of the same set of fingerprint images than that you have two sets that were collected separately but came out exactly the same. Even if you collect two sets of fingerprint images back-to-back, the collection process is not precise enough to get identical results.
A system designed to beat audio biometrics would need to introduce enough noise of the right type to register as the same person but not the same voice recording. Entirely possible, especially if you have the specifications of the device you are trying to beat, but a significantly greater problem than just recording a voice.
Chas Belov said,
October 18, 2014 @ 2:43 am
I'm concerned that I might be locked out by a sore throat or a cold. What's the word on those?
Mike Maxwell said,
October 21, 2014 @ 11:12 pm
The comments about mimicry remind me of a trivia question. One of the speaker settings on Waze (a smart-phone-based GPS) is a rather convincing sounding Elvis. Where did that voice come from? Unless Elvis is still with us, and selling his voice, it's either someone who happens to sound like him (and perhaps makes a living as an Elvis impersonator), or it's a recording of someone that has been altered by computer to sound like him.
Anyone know which? And how well would one of these speaker ID systems distinguish between the real and fake Elvis? (I suppose: better than me.)