Another slice of prosodic sausage
« previous post | next post »
Like I said yesterday, the whole stress-timed-vs.-syllable-timed business is "a gigantic tangled intellectual thicket that’s easy to get into and hard to get out of". And one of the comments on my post asked a question that tempts me in further:
So then there’s a psychological perception of syllable-timed language that is not visible in the objective data?
Yes and no.
In the first place, there really are differences in the syllabic rhythms of languages. And in particular, syllables in (say) Spanish really are more nearly equal in duration than they are in (say) English. But the reasons for this are not the reasons that people who use the terminology of "syllable timed" vs. "stress timed" usually have in mind.
And in the second place, there are also psychological differences in the prosodic organization of languages, both in perception and in production, that are connected to the idea of languages being "stress timed" vs. "syllable timed". However, there's more than one dimension involved, and more than two categories, and thereby much confusion arises.
And in the third place, …
No, that's far enough into the thicket for today. But I'll contribute another Breakfast Experiment™ to illustrate my statement that there really is an objective difference in the syllabic durational patterns of different languages, and then I'll try to explain why this doesn't mean what people often think it means.
As a source of data, I took David Puente's ABC Exclusiva podcasts for 4/24/2008 in English and for 4/25/2008 in Spanish. Mr. Puente is bilingual — I gather that Spanish was his first language, but his English sounds pretty much like ordinary American.
I segmented the first 120 syllables of the two podcasts, starting in each case from the point where he identifies himself ("Hello everyone, I'm David Puente"; "Yo soy David Puente").
[Let me start by reposting the warning I gave yesterday:
Note that I’ve avoided two critical questions here: how to divide a phonetic transcription into syllables, and how to align a phonetic transcription with the stream of sound. Depending on the answers, the concept “syllable duration” , applied to the same recording, will yield somewhat different experimental measurements; and therefore numbers and graphs are hard to interpret in the absence of well-defined standards for such annotation, which I haven’t provided. So take my numbers and graphs as an example of how I claim such experiments are going to come out, and feel free to produce your own –though if we wanted to get serious about this, we should publish our annotation manuals, our audio recordings, and our raw segmentations.
So by all means try this at home — but if you want to spend more than a few minutes on it, start by defining your terms and methods, so that you can identify and segment syllables (or speech units of whatever kind) in a consistent and well-defined way.]
Here are the numbers I got.
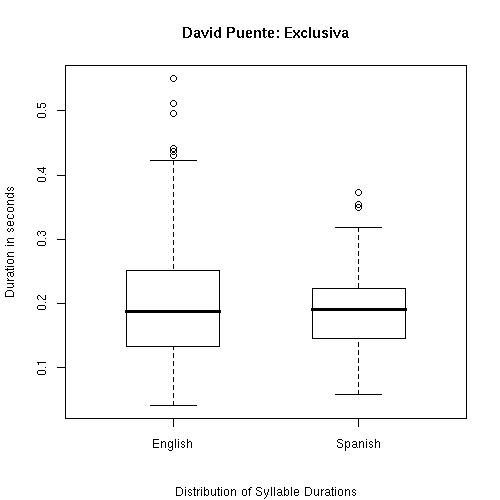
In English, David Puente's average syllable duration was 204 milliseconds, with a standard deviation of 107 msec, or 52% of the mean.
In Spanish, his average syllable duration was 189 msec, with a standard deviation of 59 msec, or 31% of the mean.
So his Spanish is closer to being objectively "syllable timed" than his English, in exactly the way that Rudy Giuliani's English was not closer to being objectively "syllable timed" than Mitt Romney's English.
Some other numbers… In English, the interquartile range of his syllable durations was 117 msec, while in Spanish it was 79 msec. In English, the average absolute value of the difference between adjacent syllable durations was 114 msec, while in Spanish it was 65 msec.
In graphical terms, here's a boxplot:
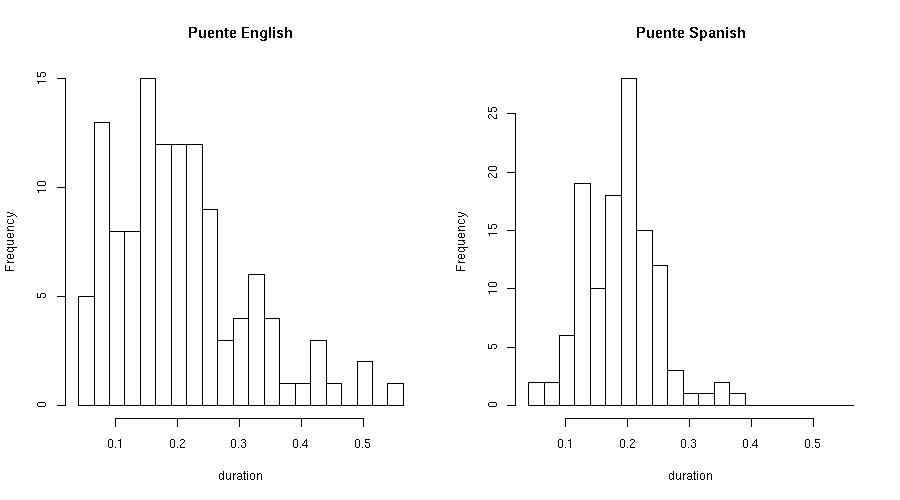
Here are some histograms (click on the image for a larger version):
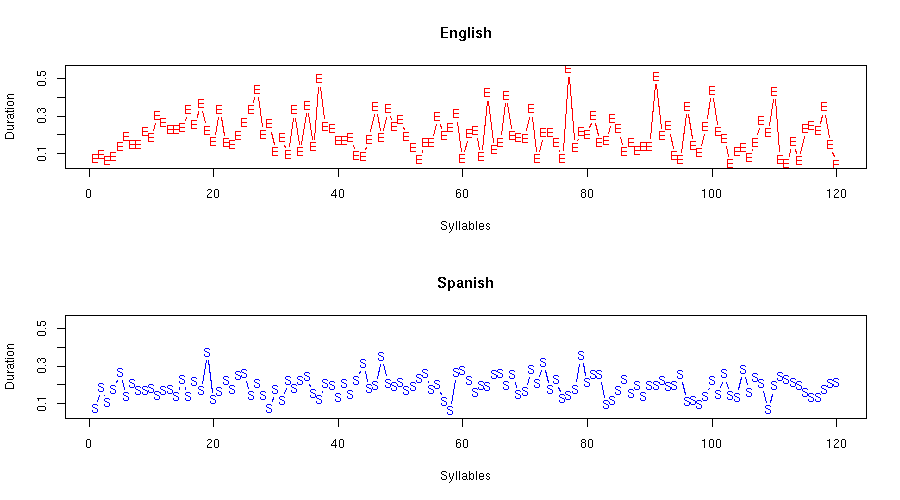
Here's the raw syllable-duration sequence, according to my segmentation:
OK, so what's wrong with the way that people often think about the difference that this little experiment illustrates?
Well, the main reasons for the difference are pretty obvious, and they're mostly differences in the nature of individual syllables, not the way that speakers "beat time" in producing them. English syllables can be as simple as a single vowel, or (in the short passage in today's experiment) as complex as church or priest, while the most complex Spanish syllables are substantially simpler. English unstressed vowels are often reduced in duration relative to stressed syllables, as in the middle syllable of the word tragedy; unstressed vowels are not reduced in the same way in Spanish. There's more, but this is enough to create a difference of the kind under discussion, namely a narrower range of syllable durations in Spanish.
So a difference in speakers' rhythmic intentions isn't needed to explain the basic observation. But absence of evidence isn't evidence of absence. There's a widespread impression that Spanish speakers (unconsciously) try to produce a sequence of equal-duration syllables, while English speakers try to produce a sequence of equal-duration stress groups (or prosodic feet, i.e. inter-stress intervals). We can test this idea directly; and if we do, we'll find that it's wrong. At least, it's wrong if we interpret "equal duration" as having something to do with the objective similarity of intervals of time. But that's an experiment for another day's breakfast.
Gary said,
May 6, 2008 @ 7:37 am
I'm wondering if the psychological perception is based on all syllables, or only, say, stressed ones. It may be that stressed syllables in English are louder and/or longer than the corresponding syllables in Spanish.
felix culpa said,
May 6, 2008 @ 8:18 am
Aside from your analysis, which I admire (while awaiting elaboration), the initial syllable of your post provokes my pedantry. Perhaps you’ve covered the like/as distinction elsewhere, and if so, please direct me. If not, I would welcome elaboration, assuming it’s apt.
Thanks for the morning mental stimulant.
[myl: You're welcome.
As for like as a conjunction, please run to your local bookstore and buy a copy of Merriam-Webster's Concise Dictionary of English Usage, or order it online. Even if you pay the full retail price of $16.95, rather than the discount price of $11.53 at amazon, your pedantry will thank you, since this work will enable you to restrain it from saying foolish things in public.
In the four-page-long MWCDEU entry on the subject of like-the-conjunction, you'll find quotes from Winston Churchill (" We are overrun by them, like the Australians were by rabbits"), Chaucer, and Shakespeare ("and, like an arrow shot from a well-experienc'd archer hits the mark his eye doth level at, so thou ne'er return unless thou say Prince Pericles is dead"). You'll learn that Otto Jespersen said in vol. v of his 1909-1949 grammar of English that "examples abound", and cited cases from Keats, Emily Bronte, Thackeray, George Eliot, Dickens, Kipling, Wells, Shaw, Maugham and others.
You'll read that "[W]e must conclude that Strunk & White's relegation of conjunctive like to misuse by the illiterate is wrong". Maintaining an elevated and polite tone, the editors of MWCDEU don't join Geoff Pullum in applying phrases like "poisonous little collection of bad grammatical advice". But you know what they mean.
And in the remaining pages of the entry, you'll learn something about the historical process by which this particular foolish prejudice was invented and promoted.
When I wrote the first word of this post, I originally used "as", because I know that the poisonous little collection of bad grammatical advice has so effectively misled (a small segment of) the public that some ill-informed people will react as you did. But to my ear, "as I said yesterday" sounds pompous and over-formal in the context of a blog post. So on reflection, I changed it to "like".]
Bill Walderman said,
May 6, 2008 @ 12:55 pm
Prof. Liberman
Could you recommend further reading on syllabic rhythms and prosody? I'm not a linguist, but a long time ago I took some linguistics courses in college, and I'm willing to try to work my way through the technical details.
It has always seemed to me that capturing the rhythm of speech is the most difficult aspect of mastering the pronunciation of a foreign language, and also the key to sounding like a native speaker (well, almost like a native speaker).
[myl: There's a large technical literature on this, some of it excellent, but I can't think of a good overall introduction for the general reader, I'm afraid. Stay tuned, though, and I'll try to cover some of the issues in future posts, including some references to other work.]
felix culpa said,
May 6, 2008 @ 1:13 pm
Delightful and again, thanks.
Many thanks, in fact. Such a generous response.
The issue of pomposity is something I fear as a dangerous loved one. Forced to face it, fearful of doing so. Having performed Polonius in a production infamous and admired in these parts (Toronto/Montreal), the director said “You are Polonius.” Really, he did mean it as a compliment. I think. Many thought him a sadist. An eight-hour production.
I like that you changed it. I do the same thing, and am now at ease.
I also like the bit about those bundled with the illiterate.
And I liked most of all the Shakespeare passage for its effortless fluency. But don’t you think ‘like as’ a sort of different kettle of fish?
Surely it’s essential that it be “Like as the hart panteth” ? Somehow? As a non-linguist I know not. Onward to MWCDEU.
Sili said,
May 6, 2008 @ 5:56 pm
FWIW Graham Pointon had some thoughts on the matter last month. If I read him correctly, he seems to think there's something there, but certainly advocates a spectral approach rather than a clear-cut black/white categorisation.
http://www.linguism.co.uk/language/linguistic-rhythm
Jonathan said,
May 6, 2008 @ 9:01 pm
Thanks. I never expected to get that good an answer.
john riemann soong said,
May 7, 2008 @ 2:12 am
Is it safe to say that prosody was one of the last universal linguistic features to evolve?
[myl: I don't think that *anything* about the evolution of language is really "safe to say" at this point. Darwin thought that language was an overlaid function, evolved on top of vocal displays related to courtship, i.e. love songs. And there are plenty of people up to the present day who think that might be right. If it is, then prosody would have evolved *before* rather than after other familiar features of language.
I do observe that children who speak grammatically perfect and elaborate sentences don't master their native languages' prosody until ages eight to twelve (which what makes child speech so interesting, other than applying Wug tests, and discounting physiological differences).
[myl: I guess that it depends on what you mean by "master". The standard idea in the developmental literature, as far as I know, is that prosodic features appear quite early in development. For example, D. Snow, "Polysyllabic units in the vocalizations of children from 0;6 to 1;11: intonation-groups, tones and rhythms.", J Child Language (2007) interprets a study of 60 English-speaking kids as showing that "even the youngest groups of children [i.e. at 6 months or so] produced relatively robust and adult-like intonation contours when the tone-bearing string was polysyllabic".]
john riemann soong said,
May 7, 2008 @ 2:52 am
"Note that I’ve avoided two critical questions here: how to divide a phonetic transcription into syllables, and how to align a phonetic transcription with the stream of sound. "
Is it something that hasn't really been standardised by the IPA? It seems that [ap:a] and [appa] would be used interchangeably at times, even though technically they're not the same thing.
Regarding the "spectral approach versus black/white categorisation," the idea of discreteness versus smoothness is something that's often piqued me about transcription One of my initial oppositions a few years ago when learning IPA was the way transcription conventions didn't seem to address boundaries (be it phonemic boundaries, syllabic boundaries, boundaries between semivowels and vowels, fringe effects and differences, and so forth. It especially confused me how textbooks and web pages would note one kind of fringe effect but not another [even just for narrow transcription], mostly things like semivowel glides, often which weren't noted anyway. For example, is "sail" narrowly transcribed as [seɪɫ] or [seɪəɫ]. For a while I took a lack of standardised conventions [at least as far as dictionaries, textbooks, etc. used them] on fringe effects to mean that they didn't exist. To some extent I eventually managed to vindicate my initial suspicions.
But it does seem such boundaries can be rather arbitrary (and whether they exist per se in some cases seems questionable). French dictionaries have a habit of saying that the vowel in "vin" is /ɛ̃/ while the vowel in "aime" was just plain /ɛ/. For a few years I thought I was hallucinating, because the nasal sounded more like a nasal /a/. It wasn't till this year actually that I saw a tongue position chart showing that in French, nasal /ɛ/ and oral /ɛ/ have significantly different tongue positions (where the nasal /ɛ/ was much closer to /a/). Even when a narrow transcription doesn't note down a fringe effect that seems to occur
[myl: No, the IPA has not tried to impose standards on the how English (or any other languages) should be divided into syllables — nor even tried to legislate whether the concept "syllable" should be applied at all. Nor does the IPA offer any guidance on how to segment the stream of speech in objective time. And that's as it should be, for reasons that deserve a post of their own.]
Ellen K. said,
May 7, 2008 @ 9:57 am
I wonder how poetry fits into all this, poetry being more rhythmic (well, some poetry) than regular speech.
[myl: For a start, take a look at "An Internet Pilgrim's Guide to Accentual-Syllabic Verse", 7/6/2004. I hope to say more about the phonetics of accentual-syllabic meter in a later post. The short answer, though, is that rhythmicity is not isochrony.]
Christian DiCanio said,
May 8, 2008 @ 1:01 am
One could also make the distinction between patterns that are more stress-timed vs. those that are not. It would seem that you need to do another study to determine if the duration between target stresses in English is more consistent than it is in Spanish. Understandably intonation will make such an analysis more problematic.
Ellen K. said,
May 8, 2008 @ 8:25 am
Not really what I was thinking. More along the ideas of poetry in English being stress timed (and perhaps there are languages where this differs), and how that relates to non-poetry language. The obvious point to me seems to be that, if poetry (or that which is metrical, anyway) is stress timed, and sounds different than ordinary speech, then ordinary speech isn't stress timed. But I also wonder if differences in poetry rhythms in different languages affect people's mental perception of ordinary speech. Are they applying differences in poetry to differences in regular speech?
Jonathan said,
May 8, 2008 @ 8:17 pm
"Rhythmicity is not isochrony"
That deserves a post of its own.
Andrew S said,
May 9, 2008 @ 12:53 pm
"English syllables can be as simple as a single vowel, or (in the short passage in today’s experiment) as complex as church or priest, while the most complex Spanish syllables are substantially simpler."
This begs an interesting question: how complex can syllables be?
John Cowan said,
June 8, 2008 @ 1:23 am
The Georgian surname "Mgrvgrvladje" (where the transcription is basically IPA) is said to have two syllables. Naturally, it takes a good deal longer to say "mgrvgrvla" than to say "dje".