TO THE CONTRARYGE OF THE AND THENESS
« previous post | next post »
Yiming Wang et al., "Espresso: A fast end-to-end neural speech recognition toolkit", ASRU 2019:
We present ESPRESSO, an open-source, modular, extensible end-to-end neural automatic speech recognition (ASR) toolkit based on the deep learning library PyTorch and the popular neural machine translation toolkit FAIRSEQ. ESPRESSO supports distributed training across GPUs and computing nodes, and features various decoding approaches commonly employed in ASR, including look-ahead word-based language model fusion, for which a fast, parallelized decoder is implemented. ESPRESSO achieves state-of-the-art ASR performance on the WSJ, LibriSpeech, and Switchboard data sets among other end-to-end systems without data augmentation, and is 4–11× faster for decoding than similar systems (e.g. ESPNET)
There are several technical terms that may need explanation here — especially "neural" and "end-to-end".
"Neural" refers to machine-learning systems based on pseudo-neural networks, i.e. complex patterns of linear-algebra operations with interspersed point non-linearities, representing in highly abstracted form the activity of biological neurons. Systems of this kind can be "trained" to perform operations like prediction and classification, and most contemporary "AI" applications are based on such technologies.
"End-to-end" is the trend towards eliminating traditional intermediate stages between inputs and outputs. Thus in speech recognition, streams of audio waveform samples come in one end, and streams of text characters come out the other end. Traditional intermediate stages include spectral analysis of the audio, representation of the character stream as a sequence of words, a "language model" giving the contextual probability of words, and a pronouncing dictionary or letter-to-sound rules to mediate the relationship between words and sounds. In an end-to-end system, all there are gone — there's nothing in between audio input and letter-stream output but pseudo-neural network nodes, with connection values learned from training. An end-to-end machine translation system might take in text as a stream of Chinese characters and put out the English translation as a stream of ASCII letters.
In some ways, this is the ultimate implementation of empiricist epistemology. It's not the case that there's a single universal system that can learn anything — there are many choices of network architecture and training parameters, whose performance depends on the nature and relationship of the inputs and outputs. But it's still impressive that systems of this kind, without obvious built-in knowledge, can often do such a good job of learning complex relationships.
However, it's worth noting that the learning process — and even its endpoint — is not very human.
Running a slightly-modified version of the prescribed Espresso LibriSpeech training recipe, early results look like this:
Reference text: ALL RIGHT
ASR output: LINRIS BALLOON
Reference text: A GREAT TECHNICAL ADVANTAGE OF LARGE PRODUCTION IS THE BETTER AND FULLER USE OF MACHINERY A LARGE FACTORY WITH A LARGE OUTPUT CAN KEEP A SPECIAL MACHINE ADJUSTED FOR EACH PATTERN AND PROCESS
ASR output: AND LITTLE DEALMNICAL AND OF THENESSION OF THE SAME OF THE OF OF OF THES AND MAN AND THAT AND THE VERY NUMBER OFROABLE BE THE SMALLLY ANDMENT BY THE OTHERTER THE
After another epoch of training:
Reference text: IT INDICATED THAT HIS POWERFUL MIND WAS ON THE VERGE OF DESPAIR AND MADNESS AH MY CHILD MY POOR CHILD CRIED THE BARONESS FALLING ON HER CHAIR AND STIFLING HER SOBS IN HER HANDKERCHIEF VILLEFORT BECOMING SOMEWHAT REASSURED
ASR output: AND WAS THEICATE THAT THE OWN MIND WAS TO THE CONTRARYGE OF THE AND THENESS AND THAT DEAR SAID DEAR FELLOW I THE KINGESS AND DOWN THE KNEES AND SAIDUNLED HER TOBB AND HER ARMS A PALESSURED
A little later:
Reference text: HE GAVE HIM A GOOD ROWING AND TOLD HIM HE DESERVED ANOTHER HAMMERING WHICH HE HAD A GOOD MIND TO GIVE HIM IF WE HADN'T BEEN STARTING FOR A JOURNEY WARRIGAL DIDN'T SAY A WORD TO HIM HE NEVER DID STARLIGHT TOLD ME ON THE QUIET THOUGH HE WAS SORRY IT HAPPENED
ASR output: THE GAVE HIM A GOOD BLOWING AND TOLD HIM THEY DESIREDD ANOTHER HE WHICH WHICH HE HAD A GOOD MODE TO GIVE HIM IF WE HADN'T BEEN STARTING FOR A JOURNEY WHILERIGGALD'T SAY TO WORD TO HIM HE NEVER DID SOLIGHT TOLD ME ON THE QUIET THAT HE WAS SORRY AT HAPPENED
After a half a dozen training epochs, the word error rate is down to about 12%, and many of the results are impressively good:
Reference text: AMERICAN GIRLS ALWAYS HAVE MORE THINGS THAN ENGLISH GIRLS SHE OBSERVED WITH ADMIRABLE COOLNESS THEY DRESS MORE I HAVE BEEN TOLD SO BY GIRLS WHO HAVE BEEN IN EUROPE AND I HAVE MORE THINGS THAN MOST AMERICAN GIRLS FATHER HAD MORE MONEY THAN MOST PEOPLE
ASR output: AMERICAN GIRLS ALWAYS HAVE MORE THINGS THAN ENGLISH GIRLS SHE OBSERVED WITH ADMIRABLE COOLNESS THEY DRESS MORE I HAVE BEEN TOLD SO BY GIRLS WHO HAVE BEEN IN EUROPE AND I HAVE MORE THINGS THAN MOST AMERICAN GIRLS FATHER HAD MORE MONEY THAN MOST PEOPLE
Reference text: BE UNDER ANY CIRCUMSTANCES JUSTIFIABLE I DO NOT PRETEND TO JUDGE SAINT AUGUSTINE IN HIS ONE HUNDRED NINETEENTH LETTER TO JANUARIUS SEEMS NOT TO DISAPPROVE OF THIS CUSTOM
ASR output: BEYOND UNDER ANY CIRCUMSTANCES JUST RIVALIABLE I DO NOT PRETEND THE JUDGE SAY IINE IN HIS ONE HUNDRED NINETY LETTER LETTER TO JANUARYNUARIUS SEEMS NOT TO DISAPPROVE OF HIS CUSTOM
(Representing the texts in monocase without punctuation is a choice made by the folks who put together the LibriSpeech corpus.)
Obviously this is not what we would expect to see from a human language learner repeatedly (but passively) exposed to a thousand hours of audiobooks with the associated text streams.
Why "Espresso"? It's not an acronym, but rather the continuation of a meme that started with Kaldi, an earlier open-source ASR toolkit named after the Ethiopian goatherd who is said to have discovered coffee.
And the characteristic behavior of end-to-end systems is probably what explains some of the odd errors that YouTube's auto-generated transcripts mix in with otherwise excellent recognition — e.g. in Boris Johnson's recent U.N. speech, we have e.g.
| What he said: | so that no bin goes unemptied, no street unswept and the urban environment is as antiseptic as a Zurich pharmacy |
| The automatic transcript: | so the Mobe in goes an empty Dino Street unswept and the urban environment is as antiseptic as as Urich pharmacy |
| What he said: | when Prometheus brought fire to mankind in a tube of fennel, as you may remember, with his brother Epimetheus |
| The automatic transcript: | when Prometheus brought fire to mankind in a tube of phenol as you may remember with his brother Epimetheus |
| What he said: | we have discovered the secrets of less than nought point three percent of complex life |
| The automatic transcript: | we have discovered the secrets of less than Northpoint 3% of complex life |
[h/t Neville Ryant]
Gregory Kusnick said,
September 29, 2019 @ 4:04 pm
"an open-source, modular, extensible end-to-end neural automatic speech recognition (ASR) toolkit"
Should I infer that "end-to-end neural automatic speech recognition" is a fixed-phrase term-of-art that requires no internal punctuation?
[(myl) It's a left-branching complex nominal, something like (ignoring N-bar levels)
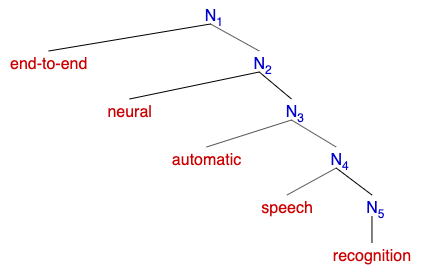
so what internal punctuation could you use? ]
AntC said,
September 29, 2019 @ 4:07 pm
CONTRARYGE
Whatever the merits of "end-to-end"ness, it seems to me this thing could do with a 'sanity check' just after the end, to catch sequences of letters that couldn't possibly be words. I see it's trying to deal with input containing Proper Names (and presumably acronyms), so it wouldn't be as simple as looking in a dictionary, but even a basic Markov algorithm would tell that …YGE# is not a letter-sequence in English. (Where # is word delimiter; and that sequence is not in the input.)
How does it go translating into written Chinese, as opposed to an alphabetical orthography? Because you must choose a valid character/no opportunity for some random collection of radicals — or is that what "end-to-end"ness would do?
[(myl) In some ways it's even more puzzling that such systems generally don't do sanity checks on their inputs.
In the case of Chinese, I expect that an end-to-end system would have hanzi characters at the text end, not radicals. Though I guess for truly hardcore end-to-endity, you'd map from waveform samples onto screen pixels :-)…]
Gregory Kusnick said,
September 29, 2019 @ 5:11 pm
MYL: I suppose I would have naively considered "end-to-end" a modifier on par with "open-source", "modular", and "extensible", so I would have expected (at least) one more comma.
[(myl) Oh, I see. Yes, I guess it's the term-of-art thing — those other three terms are in some sense non-restrictive, whereas "end-to-end neural" are restrictive modifiers of ASR in that context.]
Joe said,
September 30, 2019 @ 11:44 am
@myl: "In some ways, this is the ultimate implementation of empiricist epistemology."
These accelerated rates of "empirical advancement" in Machine Learning gives some AI researchers the heebie-jeebies (See Winner's Curse?). Machine learning and neural networks in particular are notoriously uninterpretable and therefore a cause for concern if these systems end up making decisions that affect people's lives. Critics of this position either argue against these concerns with "it just works – can't argue with results" or "humans are black boxes, too". I imagine that the fix to this unaccountability problem is to throw more AI at it, perhaps a machine learning module designed to "explain" the results.
AntC said,
September 30, 2019 @ 4:32 pm
Thanks @Joe, some good points.
throw more AI at it Sorry, I'm not seeing a lot of the I with myl's examples. My particular suggestion for the basic Markov algorithm sanity check I'd describe as "throw more dumbness at it".
perhaps a machine learning module designed to "explain" the results. But if the results come through a 'black box', nothing can explain by peering into its workings. It can only guess at the workings from the external appearance. And humans are already pretty good/bad at that. I don't see it gives any more confidence in the result.
"humans are black boxes, too" well no. For "decisions that affects people's lives" (like medical diagnosis), there are documented procedures, tests and examinations. The decision does need judgment from an expert, and yes they're fallible, but there are ways to audit the decision process and detect where it's gone wrong and learn from that.
And there's peer review. If three of these end-to-end algorithms come up with the same answer, does that give me more confidence than just one? If they come up with three trivially different but morally the same answers, is there an arbiter can apply 'common sense'?
Mary Kuhner said,
September 30, 2019 @ 5:21 pm
Chessplayers are getting increasingly familiar with computer analysis and scoring of games, and one thing that's emerging is that their standards aren't our standards, even when we're both "trying to win the game" and we do agree on what that means.
Soltis, in one of his books, gives an example of a position in which a reasonably skilled human will quickly find a checkmate in five moves. Every move by the stronger player forces the response of the weaker player, so it is easy to calculate. It turns out that the initial position also allows checkmate in three moves, but the first move is "quiet" (it does not force the opponent's response) and humans do not like it because *every single opponent response* has to be calculated. In other words, humans have a criterion beyond "Is this variation good or bad?" namely "Is this variation easy or hard?" And, for human use, this is absolutely a sensible criterion; many games have been lost because a player embarked on a "hard" continuation and then made a mistake.
So once we get a large corpus of this kind of black-box translation we should take a careful look and see what the machine's biases are, before deciding whether we want to use it. Most people who use chess engines to study know that sometimes the machine suggests a move that is just not "human" and you probably shouldn't take its advice. I recall a case where it recommended a devilishly difficult position with queens on the board and three extra pawns for me, rather than a mindlessly easy win with no queens, but only two extra pawns. It's entirely rational for a human to prefer the latter! –In fact my opponent simply resigned; I doubt he would have resigned the queen endgame.
Andrew Usher said,
September 30, 2019 @ 6:39 pm
This subject isn't particularly interesting to me – yet – but the second-last transcription caught my eye because of the substitution 'phenol' for 'fennel'. I admit that choosing between the two requires more context than a computer is likely to have, but why is it programmed with the incorrect pronunciation of 'phenol'? (A priori, it would seem 'a tube of fennel' and 'a tube of phenol' are about equally unlikely.)
This is a real annoyance to me; I say the only pronunciation of 'phenol' is FEE-nol (-nahl, -nawl) and will correct anything else. There can be no authority for the short vowel, '-ol' is never reduced in chemical names, and second-syllable stress (which I have heard!) is beyond risible. Similarly the prefix 'phenyl-' has a long e, not a short; so neither can be 'fennel'.
k_over_hbarc at yahoo dot com
PaulB said,
September 30, 2019 @ 7:21 pm
"DEAR SAID DEAR FELLOW I THE KINGESS AND DOWN THE KNEES AND SAIDUNLED HER TOBB AND HER ARMS A PALESSURED"
Professor Unwin? Is that you?
AntC said,
September 30, 2019 @ 10:39 pm
@Mary, I'm not seeing that chess playing/analysis is comparable to language-based tasks. Chess has hard-edged rules compared to language. Even if we don't program those rules into the engine, but merely expect it to learn from experience of (say) moving a knight diagonally and getting told that's illegal, there is still only a handful of final outcomes: win/lose/draw/illegal move.
With language-based tasks, there's nuanced outcomes like: well that spelling might be a word of English, but it isn't/there is a word pronounced like that but it isn't spelled the way you'd reasonably expect; there is a word spelled that way but it' s the wrong part of speech/doesn't make sense in that context ("red" vs "read"); that is kinda English but no human would say that — such as how people detect non-native language users.
Chess and Go, etc playing have been the great successes of AI. I am a lot less than convinced that the stimulus-response style of AI learning is ever going to get very far with language tasks. (Where the stimulus is the corpus, and the response is something like: yes that transcription/translation made sense.) Perhaps AI for language doesn't need to mimic human thought processes (as if we know what they are ha!), but it does seem to me there needs to be a model of what makes sense in the mini-world of the discourse; and that is based on both verbal and non-verbal inputs — as in going and walking/looking around in it.
Rodger C said,
October 1, 2019 @ 7:02 am
@Andrew Usher: What's your field? In college chemistry in West Virginia in the 60s I was taught to pronounce "phenol" fa-NOLE, emphasizing the element that conveys the class of the compound.
Andrew Usher said,
October 2, 2019 @ 6:41 pm
So your pronunciation rhymes with dole not doll, is that right? That apparently exists too. I'm not sure what you mean by 'the element that conveys the class of the compound' – phenol (C6H5-OH) contains no unusual element, if you meant 'functional group' that's the alcohol (-OH) moiety; and no one says alco-hole. The ending '-ole' is used for a different group of compounds, as well.
My pronunciation is clearly the majority preference of dictionaries (online check), and in actual use – Youglish gives ~50 actual hits, which show almost all the possible pronunciations but FEE-nol is most common. For 'phenyl-' the short vowel appears more common. [I can't explain that, unless someone had the sense that '-yl' shortens vowels like '-ic' does, but there's no Latin explanation for '-yl' – I can't think of any other unambiguous examples of a preceding vowel shortening before '-yl', but can think of one counterexample: (iso)propyl (the vowel U never shortens, so can't be used in an example).]
Finally, the etymology is undoubted: *phene (= benzene) + -ol (from 'alcohol'), and the latter doesn't have primary stress in any other name.
Rodger C said,
October 3, 2019 @ 6:38 am
I should indeed have said "functional group." It's been a long time.
Arfur said,
October 4, 2019 @ 11:03 am
@Andrew Usher:
Alco-hole is just another term for the garden variety of drunken British slag.