Noisily channeling Claude Shannon
« previous post | next post »
There's a passage in James Gleick's "Auto Crrect Ths!", NYT 8/4/2012, that's properly spelled but in need of some content correction:
If you type “kofee” into a search box, Google would like to save a few milliseconds by guessing whether you’ve misspelled the caffeinated beverage or the former United Nations secretary-general. It uses a probabilistic algorithm with roots in work done at AT&T Bell Laboratories in the early 1990s. The probabilities are based on a “noisy channel” model, a fundamental concept of information theory. The model envisions a message source — an idealized user with clear intentions — passing through a noisy channel that introduces typos by omitting letters, reversing letters or inserting letters.
“We’re trying to find the most likely intended word, given the word that we see,” Mr. [Mark] Paskin says. “Coffee” is a fairly common word, so with the vast corpus of text the algorithm can assign it a far higher probability than “Kofi.” On the other hand, the data show that spelling “coffee” with a K is a relatively low-probability error. The algorithm combines these probabilities. It also learns from experience and gathers further clues from the context.
The same probabilistic model is powering advances in translation and speech recognition, comparable problems in artificial intelligence. In a way, to achieve anything like perfection in one of these areas would mean solving them all; it would require a complete model of human language. But perfection will surely be impossible. We’re individuals. We’re fickle; we make up words and acronyms on the fly, and sometimes we scarcely even know what we’re trying to say.
The "noisy channel model" does have its roots in work done at AT&T Bell Laboratories, but Claude Shannon did that work in the 1940s, not the 1990s. Here's the diagram from his 1948 monograph "A Mathematical Theory of Communication":
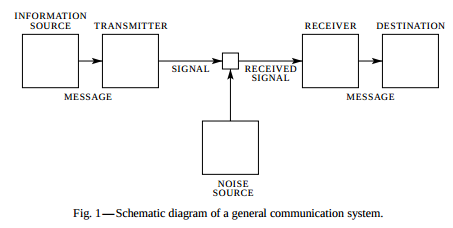
As far as I know, the first attempt to apply this idea to spelling correction was was in Josef Raviv, “Decision making in Markov chains applied to the problem of pattern recognition,” IEEE Trans. Inform. Theory, Oct. 1967:
Bayes’ decision making in Markov chains was applied to the problem of pattern recognition. Experiments, in the multifont recognition of English legal text and names, were performed.
The main idea is to combine, in the appropriate way, past and future measurements with the measurements on the character presently being recognized, and arrive at an optimal decision on the identity of this character. It is important to give the proper weighting to the information obtained from context (by context we mean past, and/or future information) versus the information obtained from the measurements on the character being recognized.
This was in the context of OCR ("optical character recognition" — applications to the correction of human typing would obviously need to wait until creating and editing digital documents became common, which didn't happen until the 1980s.
Much of the early work on applications of the Noisy Channel Model to speech recognition and to machine translation was done in Fred Jelinek's group at IBM in the 1970s and 1980s. Fred arrived at IBM in 1972, just as Josef Raviv left to head the new IBM Haifa Research Center. Until the mid-1980s, when information theory again became fashionable in AI, this group was part of what John Bridle used to call the "cybernetic underground".
The earliest applications of these ideas in a reasonably modern form to spelling correction took place more or less simultaneously (as far as I know) at IBM and at AT&T Bell Labs:
[From IBM] E. Mays, E.J. Damerau, and R.L. Mercer, "Context-based spelling correction", IBM Natural Language ITL, Paris 1990.
[From Bell Labs] M.D. Kernighan, K.W. Church, and W.A. Gale, "A Spelling Correction Program Based on a Noisy Channel Model", ACL 1990.
Those papers, of course, come out of research that had been going on during the previous decade or so at IBM and at Bell Labs and elsewhere. (See the abstract of K.W. Church and W.A. Gale, "Probability Scoring for Spelling Correction", Statistics and Computing 1991, for a sketch of the relationship.) I wouldn't be surprised to learn that there was some other simultaneous or earlier spelling-correction work of the same general kind, since the techniques used were (by then) standard, and the application is an obvious one.
Looking at the bibliographies of the above-cited works also led me to read an interesting contribution by Henry Kucera from Brown University, "Automated Word Substitution Using Numerical Rankings of Structural Disparity Between Misspelled Words & Candidate Substitution Words", U.S. Patent Number 4,783,758, 1988. This patent expresses itself in the curious pseudo-electrical language that used to be used to support the pretense that what is being patented is a device rather than an algorithm:
[T]he invention relates to an improved spelling correction system comprising dual input elements, a comparison element, and a selection element. A first input element accepts a suspect expression signal representing an incorrectly spelled linguistic expression. A second input element accepts an alternate expression signal representing a correctly spelled linguistic expression. These expressions are compared by the comparison element, which generates a disparity signal representing numerically the degree of difference between the two expressions. The selection element evaluates the disparity signal to determine whether the correctly spelled expression is a potential substitute for the incorrectly spelled expression.
So anyhow, the Google work that Gleick describes no doubt does trace its roots back to the work at Bell Labs represented by the Kernighan, Church, and Gale paper — among other things, several people at Google now were part of that group then. But the "noisy channel model" goes back to Claude Shannon at Bell Labs in the 1940s, and its applications to speech and language processing applications, including spelling correction, go back at least to work in the 1960s and 1970s at IBM and elsewhere.
James Gleick knows much of this, I suppose, given the content of his 2011 book The Information. But maybe not — none of the key players except for Shannon is named in his book, and in particular, there's no mention of Fred Jelinek and the IBM group, nor of Ken Church and others at Bell Labs.
Maybe this NYT piece means that Gleick is preparing a new book on the nature and history of statistical NLP? Someone should, anyhow. Given how important this stuff is to the modern world, it's amazing how few people know anything about it. My 2010 obituary for Fred Jelinek in Computational Linguistics discusses Fred's contributions in the context of the intellectual rise, fall, and rebirth of Information Theory as applied to speech and text.
[Note: The title of this post was stolen from Jason Eisner and the First Workshop on Unnatural Language Processing, held (in some sense of that word) at JHU in early April, 2005 — see "Noisily Channeling Claude Shannon", 4/2/2005.]
KeithB said,
August 6, 2012 @ 9:44 am
Wait, there are two Kernighan's at Bell Labs?
[(myl) At that time, there were.]
Jeff Carney said,
August 6, 2012 @ 11:19 am
When I type “kofee” into the search box, Google returns results for "kofee," though it does offer to return results for "koffee" instead.
Mark F. said,
August 6, 2012 @ 12:09 pm
I interpreted the passage as saying that Google's autocorrection algorithm had roots in work done at Bell Labs in the early 90's, and that the work in the early 90's depended on (but didn't introduce) the noisy channel model, a "fundamental concept" developed at some unspecified earlier place and time.
Eric P Smith said,
August 6, 2012 @ 1:35 pm
This story, probably apocryphal, was told to me in my childhood. A schoolboy had atrocious spelling but his generous teacher promised to award him a pass on his spelling if he could get even one letter right. The teacher asked him to spell 'coffee' and got the answer KAWPHY.
peterv said,
August 6, 2012 @ 2:31 pm
Which brings to mind a long-ago cartoon of Australian cartoonist Patrick Cook:
Q: What are kerbs?
A: Tableware which Americans drink coffee from.
Robert Coren said,
August 7, 2012 @ 9:55 am
On the rare occasions when I have guests for breakfast and they happen to be up and about while I'm preparing breakfast, I generally tell them "There will be coffee anon." I'm still waiting for one to ask me if I'm really expecting the former Secretary General.
Dennis Norris said,
August 8, 2012 @ 4:40 am
Sachiko Kinoshita and I have used the noisy-channel concept to build a computational model of human reading. The model can simulate a wide range of experimental data. Given how well Bayesian/noisy channel systems can perform spelling correction, you won't be surprised to know that the model can decode the famous "Aoccdrnig to a rscheearch at Cmabrigde Uinervtisy" email.
Norris, D., & Kinoshita, S. (2012). Reading Through a Noisy Channel: Why There’s Nothing Special About the Perception of Orthography. Psychological Review. doi:10.1037/a0028450