Recording-stable acoustic proxy measures
« previous post | next post »
Behind yesterday's post about possible cultural differences in conversational loudness ("Ask Language Log: Loud Americans?" 11/25/2017), there's a set of serious issues in an area that's too frequently ignored: the philosophy of phonetics. [This is an unusually wonkish post on an eccentric topic — you have been warned.]
If the question had been about pitch stereotypes — one unsupported generalization that I've sometimes heard is that "American men have more monotone voices than British men" — there'd still be a set of serious difficulties in the way of providing an empirical test.
What do we mean by "American" and "British" men, in terms of age, class, region, ethnicity, etc.? How do we control for context, given that an individual's pitches can vary by a factor of two or more between quiet conversation and public speaking (see the note on Ann Richards and Martin Luther King Jr. in "Biology, sex, culture, and pitch" 8/16/2013), or as a function of background noise level and interlocutor distance (Liberman and Pierrehumbert, "Intonational invariance under changes in pitch range and length", 1984; Garnier et al., "Influence of Sound Immersion and Communicative Interaction on the Lombard Effect", 2010), annoyance or other sources of arousal ("Raising his voice" 10/8/2011, "Debate quantification: How MAD did he get?" ), register/genre/style, and so on?
And how do we quantify "monotone"? Let's start with the fact that the fundamental frequency ("f0"), the standard proxy for the linguistically-relevant dimension(s) of pitch, is sometimes not a well-defined quantity in the real world, and in any case is often not a reliable correlate for the perceptual and linguistic features we care about (See "Pitch contour perception" 8/28.2017, or "Tone Without Pitch", ETAP 5/30/2015). Assuming that time-local estimates of voice f0 are the appropriate measurements, there's still the question of how to summarize the values from different places in the syllables, words, and phrases of interest — should we weight values according to the local amplitude? should we pay special attention to extrema or to regions of rapid change or both? should we use a linear or a log scale or something else? should we attempt a more complex perceptual weighting based on time/frequency/amplitude considerations, syllable segmentation, etc.? in whatever transformed space, should we look at means and variances, (perhaps-weighted) quantiles, median absolute deviation from the median, or what?
All the same, researchers who want to compare pitch ranges across different groups are in relatively good shape. We have a reasonable proxy measure — fundamental frequency — which can be somewhat reliably recovered from most recordings, because it's not much affected by microphone and other channel characteristics, signal encoding, and so on. We can chose datasets, at least in principle, where we can try to ensure that the recording contexts are on average similar across the groups to be studied. And if several different quantification methods point to the same answer, then we can feel some confidence in our results.
I haven't done this sort of test for the stereotype about American and British male pitch ranges. But a decade ago, I did a Breakfast Experiment™ to test someone's suggestion that female/male pitch polarization is greater in Japanese than in (American) English. The results ("Nationality, Gender and Pitch" 11/12/2007) supported the stereotype:
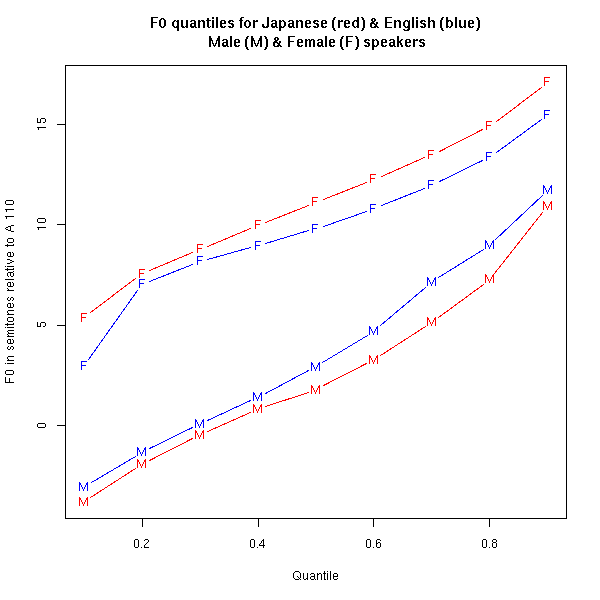
There are still plenty of issues — the speakers were not matched across languages in age and relationship, for example — but overall this is a reasonable first-order test of the hypothesis, suggesting that there's something worth looking into further.
With respect to the "loud Americans" hypothesis, we're in much worse shape. There are all the same problems about which Americans, recorded where, doing what. And amplitude, the acoustic proxy for "loudness", is at best an even more problematic measure than fundamental frequency. This is partly for psychophysical reasons — we need to decide how to weight different frequencies, for example. And the correspondence between the linguistic-phonetic dimension of vocal effort (in production or perception) and any frequency-weighted amplitude measure is much worse than the problematic correspondence between pitch and fundamental frequency. Thus if we try to increase the "loudness" of stressed syllables in speech synthesis by local increases in amplitude, it just sounds like someone is twiddling the gain knob — because that's what it is.
But the biggest problem is simple and obvious:
Audio recordings do not preserve the amplitude of the recorded source.
The amplitude of a (digital or analog) audio signal is essentially arbitrary, depending on the microphone placement and amplitude settings in the original recording, and any subsequent analog or digital processing.
Reliable sound-level meters do exist, of course, but again, the values that they register depend on their placement relative to the source and on the acoustics of the recording environment.
As a result, it's somewhat meaningful (for example) to compare f0 measurements for American, British, French, German, Japanese, and Chinese news broadcasters, or for the participants in the Scottish, Canadian, American, Australian Dutch, Italian, Japanese, Swedish, Occitan, and Portuguese Map Task Dialogues. But it's completely meaningless to compare amplitude (or "loudness") measures across such datasets. We can easily do it, but the results would have no value whatsoever, except perhaps as evidence about the level-setting and post-processing practices of the various sources. And the same problem applies to essentially of the existing (millions of hours of) audio recordings across individuals, contexts, and languages.
So is there any way to test the "loud Americans" hypothesis? As far as I can see, we'd need to outfit a set of restaurant tables in different countries with sound-level meters, and record a large-enough sample of visitors of different national categories. We'd need simultaneous video recordings to check whether the different groups were sitting at different distances from the meters. And unless the meters and cameras were hidden (which is ethically and legally problematic) there would be an Observer's Paradox problem.
It's worth noting that the gender-polarization experiment had an additional advantage, namely that we're looking at differences within a given category (and often within a given conversation). Given appropriately random microphone placement or phone-channel characteristics, we could ask (for example) whether in conversations between older people and younger people, or males and females, or Democrats and Republicans, there's any reliable difference in amplitude between one category of speakers and the other.
There's an additional paradox about relative amplitude. It's often a robust measure of linguistic differences in production, as shown for example in Kochanski et al. "Loudness predicts prominence: Fundamental frequency lends little", JASA 2005. But manipulating it is often not very effective in perceptual terms, as suggested by an old experiment that hasn't gotten as much attention as it deserves — Nakatani and Aston "Perceiving the stress pattern of words in sentences", JASA 1978:
The cues for hearing the stress pattern of a word may be different depending on whether the word occurs in isolation or in a sentence. Furthermore, even within a sentence, the relative importance of the cues depends upon where the word occurs in the sentence, and upon phrasal accent. For example, contrary to Fry's classic results with words in isolation, the pitch contour was useless as a cue for perceiving the stress pattern of a noun preceded by an accented adjective. The word's duration pattern proved a more robust cue than pitch for stress pattern perception; the word's amplitude contour was useless as a cue. These results derive from an experiment where listeners had to identify the stress pattern of bisyllabic nonsense words embedded in meaningful sentences. The listeners had only to choose between the nonsense words “MAma” and “maMA” (10 and 01 stress patterns, respectively) on the basis of the perceived stress pattern. The duration, fundamental frequency, amplitude and spectral features of the nonsense words were manipulated factorially via LPC analysis‐synthesis to assess the relative importance of these acoustic features as cues for stress perception.
Jarek Weckwerth said,
November 26, 2017 @ 9:24 am
Thank you! LL needs more of this!
Bobbie said,
November 26, 2017 @ 9:29 am
As an American, when I traveled in Europe, I was sometimes struck by how loudly some Americans spoke. I remember an incident in a Danish clothing store where an American woman was speaking very loudly about how "cute" the small Danish coins were. But now I wonder if her voice seemed louder because I understood what she was saying. (Let's not even get into the insulting aspect of what she was saying, as if *her country's coins were somehow better.)
Lex said,
November 26, 2017 @ 9:36 am
"This is an unusually wonkish post on an eccentric topic — you have been [aroused]." FIFY.
Gregory Kusnick said,
November 26, 2017 @ 1:10 pm
This is far from my area of expertise, but the first thing that leaps to mind is some sort of machine-learning approach to vocal-effort detection. After all, human listeners have no difficulty distinguishing whispers, conversational speech, oration, shouting, etc. regardless of physical proximity or playback volume. So clearly the signal contains sufficient information, independent of amplitude, to enable such discrimination, and it seems like it ought to be possible to train up a network that can extract that information.
[(myl) "Vocal effort" is certainly an excellent research topic. There's interesting work on it going back 50 years or so. But one of the things we don't know is just how much information about vocal effort is actually transmitted in recorded signals. My guess is that intersubjective identification of vocal-effort levels from recordings is not that good — maybe four levels or so? — but that discrimination of increases or decreases, for a given speaker in a given context, is better.]
unekdoud said,
November 26, 2017 @ 2:29 pm
You could calibrate each recording with the help of some sort of Standard Loudness Emitter, to be placed in a consistent location near the speakers. You'd still need some clever setup to avoid the observer effect.
[(myl) Actually if you had one microphone per table, and calibrated each such setup carefully, and didn't change anything in the geometry or the signal path, you wouldn't need to play any further calibration sounds.]
KevinM said,
November 26, 2017 @ 3:41 pm
Re: the restaurant experiment, you'd also have to control for the loud Americans at the next table.
Noel Hunt said,
November 26, 2017 @ 3:47 pm
Your graph of f0 for Japanese men against male English speakers is very interesting from the point of view of something I mentioned in one of Prof. Mair's posts recently, and that is the articulatory setting of Japanese. According to Vance, the resting configuration of the oral cavity for Japanese includes a slight raising of the back of the tongue towards the velum, which gives rise to a slight velarized quality to the voice. My impression is that it is accompanied by lip-rounding to the point of pouting on occasion. This is very distinctive in 'tough-guy' speech, but can be heard in the voice of most Japanese. Could this partly account for a lower f0 for male Japanese speakers as opposed to male English speakers? As for women, I suspect Japanese women's voices are initially pitched rather higher than female English speakers to start with so the effect of the velarization can't be seen.
From this point of view, a graph of the f0 component of male Arabic speakers should prove to be interesting, in that velarization is much more prominent in Arabic.
Mr Punch said,
November 27, 2017 @ 8:33 am
The way to study this is to mic restaurant tables *in places where tourists of many different nationalities gather.* Surely someone could write a grant to spend a summer hanging out in restaurants in, say, Venice.
James Wimberley said,
November 27, 2017 @ 9:02 am
The NSA at least has access to a gigantic database of phone calls. You can't adjust the microphone sensitivity in a typical smartphone, or if you can, most users won't change the default. That leaves the variation in placement. As a first approximation, this is random, so it may be possible to tease out cultural variations. Many calls are made from places with standard levels of background noise, like offices or streets, allowing a correction for microphone placement. Big Brother and his sibling Big Data should be able to crack this one.
Vulcan With a Mullet said,
November 27, 2017 @ 11:55 am
My intuition is that it's not the amplitude, but the level of irritation in the hearer that interprets it as such, no matter what the language or topic…
Vassili said,
November 27, 2017 @ 1:21 pm
"loud Americans" are called that because their voices supposedly stand out above the noise. It seems to allow direct translation in measurement procedure: just take RMS of total signal when Americans are speaking vs RMS of total signal when they are not speaking. IANAA (I am not an audiologitst :))
[(myl) But the RMS (or any of the more psychophysically plausible loudness measures) depends on distance to the microphone, room acoustics, etc. If we place a dozen intermittent sound sources in a room, with identical output amplitudes, and try your method for determining their relative loudness, the experiment can identify any one of them as louder than the others, depending on where we put the microphone, what reflecting or absorbing surfaces are where, etc.]