Stress in Supreme Court oral arguments
« previous post | next post »
We just got the acceptance notice from Interspeech 2008, so it's OK for me to inform you that Associate Justice Antonin Scalia has joined Queen Elizabeth II in the elite ranks of those international celebrities who have served as subjects for experiments in instrumental phonetics. The paper accepted at IS2008 is Jiahong Yuan, Stephen Isard and Mark Liberman, "Different Roles of Pitch and Duration in Distinguishing Word Stress in English".
In fact, not only Justice Scalia, but also seven of the eight other justices on the 2001 Rehnquist court were (unwitting) subjects in our experiment. (Associate Justice Clarence Thomas didn't speak often enough to be included in the analyzed data.) We applied automated measurement techniques to recordings of 78 hours of oral arguments from the 2001 term of the U.S. Supreme court, in order to look at the (average) effects on pitch and time of primary word stress (e.g. the third syllable in jurisdiction), secondary stress (e.g. the first syllable in jurisdiction), and lack of stress (e.g. the second and fourth syllables in jurisdiction).
Most well-informed linguists will probably not find our two main conclusions very surprising — at least, not the content of our conclusions. But there's a methodological suprise, I believe, in the fact that such clear-cut results emerged from automated measurements of medium-quality recordings of natural interactions.
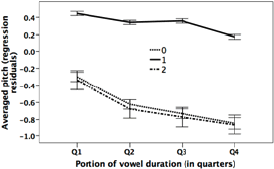 We found that vowels with main word stress (1-stress for short) were distinguished by pitch from vowels with secondary stress (2-stress) , and also from unstressed vowels (0-stress). As the plot on the right shows, the 2-stress and 0-stress vowels were remarkably similar in their normalized pitch contours, while the 1-stress vowels were quite different.
We found that vowels with main word stress (1-stress for short) were distinguished by pitch from vowels with secondary stress (2-stress) , and also from unstressed vowels (0-stress). As the plot on the right shows, the 2-stress and 0-stress vowels were remarkably similar in their normalized pitch contours, while the 1-stress vowels were quite different.
The vertical axis is in semitones, relative to a Justice-dependent reference, defined as the 10th percentile of all F0 values for that Justice. And the semitone values were normalized relative to their phrasal context, at least approximately, by representing them as differences from a regression line fitted to the F0 values for each phrase. Note that the average difference between the 1-stress vowels and the others, which is a bit more than one semitone at a point 3/4 of the way through a typical vowel's time course, corresponds to a pitch difference of about 7%. And as you can learn in a bit more detail in our IS2008 abstract, 1-stress vowels tend to have later pitch maxima (and earlier pitch minima), compared to other vowels.
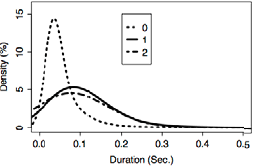 We also found that 0-stress vowels were distinguished in terms of duration from 1-stress and 2-stress vowels. The plot on the right shows density plots (smoothed histograms) of the duration distributions of the three types of vowels. In this case, the 1-stress and 2-stress vowels had remarkably similar distributions, while the 0-stress vowels were strikingly different.
We also found that 0-stress vowels were distinguished in terms of duration from 1-stress and 2-stress vowels. The plot on the right shows density plots (smoothed histograms) of the duration distributions of the three types of vowels. In this case, the 1-stress and 2-stress vowels had remarkably similar distributions, while the 0-stress vowels were strikingly different.
This general pattern is very similar to the one that was described by Ralph Vanderslice and Peter Ladefoged, "Binary Suprasegmental Features and Transformational Word-Accentuation Rules", Language 48(4): 819-838, 1972. They proposed that the English word-stress system should be analyzed in terms of two binary features, which they called heavy and accent:
The first distinction is between heavy and light syllables. If a syllable is heavy, it will have its full vowel quality; if it is light, it will be completely unstressed and will often have a reduced, centralized vowel. The phonetic mechanisms underlying this opposition are not very well understood, but they presumably involve the systems used in timing the articulations within a syllable. A light syllable corresponds to an unstressed or weak-stressed syllable in several important traditions of stress analysis.
The next distinction is between accented and unaccented syllables. The phonetic correlates of an accented syllable always include a momentary increase in the rate of expending respiratory energy (Ladefoged 1967: 44-6) and a concomitant pitch obtrusion (Bolinger 1958a). If a syllable is accented, it is also [+strong]. Unaccented syllables may be [+heavy] or [-heavy'. An unaccented heavy syllable is longer than a light one, other things being equal.
This proposal has by no means met with universal acceptance, in large part because the generalizations it proposes are by no means entirely general. The "chest-pulse" idea referenced by the notion of "a momentary increase in the rate of expending respiratory energy" is empirically shaky; some accented syllables in English have lowered pitch rather than raised pitch; pitch accents may be implemented in part on syllables adjacent to accented syllables; and so on. But still, something very close to Vanderslice and Ladefoged's features [±heavy] and [±accented] emerges strongly from the quarter-million vowels in our study.
And in this case, perhaps, the size of the collection is the point. The 78 hours of speech that we analyzed included 157,138 vowels with primary stress, 10,368 vowels with secondary stress, and 116,229 unstressed vowels (as defined simply by dictionary pronunciation entries for the words in the transcripts). But although phoneticians are patient drudges, there is no way we were going to measure the durations and pitch contours of 238,735 judicial vowels by hand. Instead, we used speech-recognition techniques to align the dictionary pronunciations automatically to the recorded speech, and then used simple computer programs to compile the prosodic statistics.
This was plenty of data for the points that we wanted to make. But out there in the virtual world, there are several orders of magnitude more hours of speech recordings with associated texts and metadata. The SCOTUS oral-argument archives alone amount to between 6,000 and 9,000 hours (though most of that is still languishing in the National Archives, waiting for Jerry Goldman to raise enough money to finish digitizing, transcribing and aligning it). There are millions of hours of oral histories, radio and TV broadcasts, court proceedings, political debates, audiobooks, and so forth. Even larger amounts of untranscribed audio is accumulating in cyberspace.
Up to now, most quantitative phonetics research has been based on measurements of relatively small amounts of speech produced under carefully controlled laboratory conditions. Recently, people have started to use more naturalistic data, though in most cases, the measurements are still done by hand. There remain good reasons to use laboratory speech, and good reasons to make measurement by hand — but we think that an important part of the future of phonetics lies in automated measurements of large bodies of natural speech data.
[This research is a spin-off of some work that Jiahong Yuan and I have done in using speech technology in preparing time-aligned transcripts of the recordings of U.S. Supreme Court oral arguments, in collaboration with Jerry Goldman's Oyez project at Northwestern. Our work was supported in part by NSF grant 0325739.]
[Queen Elizabeth was the only subject in Jonathan Harrington's "An acoustic analysis of ‘happy-tensing’ in the Queen's Christmas broadcasts", Journal of Phonetics, 34(4): 439-457, 2006, and in two papers from 2000 by Harrington, Palethorpe and Watson. These three papers and the associated public reaction were described in an earlier Language Log post, "Happy-tensing and coal in sex", 12/5/2006.]
Rick S said,
June 17, 2008 @ 11:25 am
Indeed, these results should come as no surprise to anyone with a high school education, let alone "well-informed linguists". At least, when I was taught to read dictionary pronunciation guides, pitch and duration were presented as the defining characteristics of syllable stress.
Your paper doesn't explain how you assigned each vowel to a stress class, but I assume you used some electronic form of a dictionary-style pronunciation reference, and thus your data was initially classified according to somebody's subjective impressions of pitch and duration. If so, it seems to me that your conclusions restate your assumptions, and all you measured was the reliability of your methodology in reproducing that subjective evaluation.
Was the real goal of your study to demonstrate this as a useful methodology, then, rather than "to explore the role of pitch and duration in distinguishing different stress classes"? Or am I perhaps wrong in equating vowel stress with syllable stress, or in assuming that pitch and duration were the implicit basis for your vowel stress classification?
Mark Liberman said,
June 22, 2008 @ 2:14 pm
@Rick S: We didn't just find that the duration and pitch are among the physical correlates of English stress, which indeed has been generally understood for some time. More specifically, we found that the pitch contours of vowels with main word stress are different (on average) from the pitch contours of vowels with secondary stress and vowels with no stress, while the last two categories are almost identical (on average) in pitch; on the other hand, main-stress and secondary-stress vowels have essentially the same distribution of durations, while unstressed vowels have a different distribution.
This decomposition of an apparently three-valued scale into two binary features (with one of the four combinations systematically missing) has not been generally assumed, by high-school english teachers or by linguists either. It might not even be true — you could make an argument (and some people would and have) that our results are misleading, since some secondary stresses do bear pitch accents, and are distinguished from main stresses merely by the decision about where to put a word boundary; and in other cases it's difficult to distinguish phonetically between secondary stress and lack of stress.
George Greene said,
June 23, 2008 @ 6:52 pm
I found the summary of the research fascinating; for further investigation, I'd like to see how judicial speech differs quantitatively from that of, say, advertising hacks or politicians (do I repeat myself?). However, the sum of the numbers of the three types of vowels by stress is 283 785, not 238 785..