Prescriptivist Science
« previous post | next post »
Is there any "prescriptivist science"? Could there be any? The reaction of some linguists will be that "prescriptivist science" is as much as a contradiction in terms as "creation science" is. But I disagree.
First, however, we have to reclaim the verb prescribe and its derived forms. In an earlier post about discourse anaphora ("Clarity, choice, and evidence", 5/23/2008), I complained about "the curious lack of prescriptivist science or even scholarship". From a certain perspective, this complaint is unfair. After all, there's a long and distinguished history of humanistic scholarship on matters of English usage, and usage scholars certainly come to conclusions and make recommendations. For 978 pages of evidence-based recommendations aimed at the general public, take a look at Merriam-Webster's Dictionary of English Usage.
But these genuine scholars of English usage find themselves forced to spend as much time marshaling evidence against the cranks who promote non-existent "rules" as they do correcting the barbarians whose prose is genuinely non-standard, confusing, or mistaken. As a result, the word "prescriptivist" is generally taken to refer to the crazies rather than to the scholars, and this seems unfair to me. The scholars also prescribe, after all, it's just that their recommendations are based on a rational analysis of the facts. It's as if we called witch-doctors "prescriptivists" because they prescribe on the basis of magical thinking about imaginary spirits, while calling practitioners of evidence-based medicine "descriptivists" because their recommendations are based on the factual relationship between remedies and their consequences.
Anyhow, this post is not focused on traditional humanistic scholarship, nor on the modern formal and statistical inheritors of this humanistic tradition in the domain of grammar. Instead, I want to look at the kind of rational investigation that we call "experimental science". And here, research relevant to English usage is much thinner on the ground. This is surprising, I think, because good writing is important, and arguments about usage often invoke claims and counter-claims that lend themselves easily to investigation by the techniques of modern psycholinguistics.
I'm not sure how to explain this (relative) silence. Perhaps one side generally believes that the rational evaluation of evidence has no role to play in questions of usage, which ought to depend only on the intuitions of fastidious arbiters such as themselves, while the other side mostly thinks that the "prescriptivist" arguments are too preposterous to merit investigation.
However, the silence is not complete — there is some prescriptivist science out there. This morning (it's breakfast time here in Marrakech), I'm going to take a look at two examples of the kind of study that I'm talking about. The first one is Julie Foertsch & Morton Ann Gernsbacher "In search of gender neutrality: Is singular They a cognitively efficient substitute for generic He?" Psychological Science, 8, 106–111, 1997.
Foertsch and Gernsbacher investigate whether the use of they with singular indefinite antecedents is confusing to readers. Their abstract:
With increasing frequency, writers and speakers are ignoring grammatical proscription and using the plural pronoun they to refer to singular antecedents. This change may, in part, be motivated by efforts to make language more gender inclusive. In the current study, two reading-time experiments demonstrated that singular they is a cognitively efficient substitute for generic he or she, particularly when the antecedent is nonreferential. In such instances, clauses containing they were read (a) much more quickly than clauses containing a gendered pronoun that went against the gender stereotype of the antecedent, and (b) just as quickly as clauses containing a gendered pronoun that matched the stereotype of the antecedent. However, with referential antecedents, for which the gender was presumably known, clauses containing singular they were not read as quickly as clauses containing a gendered pronoun that matched the antecedent's stereotypic gender.
In their first experiment, they presented subjects with (written) three-clause sentences like the four examples below, in which he, she or they refers to an indefinite, non-referential antecedent. The antecedents were set up to be stereotypically male, stereotypically female, or stereotypically neutral; and indefinite quantifiers like anybody were used as antecedents in a fourth sentence type:
1. A truck driver should never drive when sleepy, even if he/she/they may be struggling to make a delivery on time, because many accidents are caused by drivers who fall asleep at the wheel.
2. A nurse should have an understanding of how a medication works, even if he/she/they will not have any say in prescribing it, because nurses must anticipate how a patient will respond to the medication.
3. A runner should eat lots of pasta the night before a race, even if he/she/they would rather have a steak, because carbohydrates provide fuel for endurance events, while proteins do not.
4. Anybody who litters should be fined $50, even if he/she/they cannot see a trashcan nearby, because littering is an irresponsible form of vandalism and should be punished.
(Of course, only one of he/she/they was presented on each trial.)
The subjects were 87 undergraduates at the University of Wisconsin-Madison.
The sentences were presented on a screen, one clause at a time. After reading each clause, the subjects pressed a "Continue" button to see the next one. After completing all three clauses of each sentence, subjects were shown a prompt reading "True or False?", and pressed a button to respond.
The dependent measure was per-character reading time for the crucial second clause, and here is a graphical summary of the results:
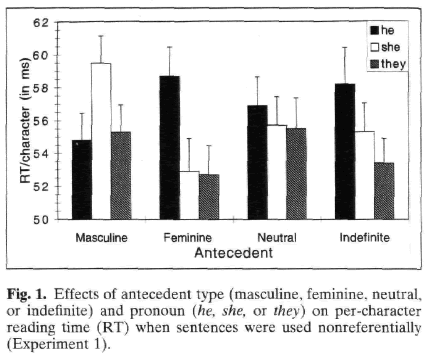
As you can see, the stereotype-mismatched pronouns (e.g. "truck driver … she" or "nurse … he") caused a delay of about 8 to 12 percent in reading, while in each case they was processed just as fast as the stereotype-friendly pronoun was. For the gender-neutral or indefinite-quantifier antecedents, they was as fast as or faster than its gendered competitors.
In their second experiment, they used similar phrases with referential antecedents that were putatively known to the writer:
5. That truck driver shouldn't drive when sleepy. even if he/she/they may be trying to make a delivery on time. because many accidents are caused by drivers who fall asleep at the wheel.
6. My nurse was able to explain how my medication would affect me, even though he/she/they had no say in prescribing it, because nurses must anticipate how patients will respond to medication.
7. A runner I knew always ate lots of pasta the night before a race, even when he/she/they would've rather had a steak, because carbohydrates provide fuel for endurance events, while proteins do not.
(In this experiment, the "True or false" question was replaced with some other yes-no question like "Do you agree?".)
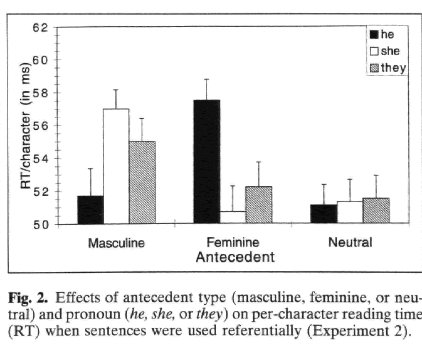
Again, the gender-mismatched pronouns added 10-15% to the reading time. This time, the results for they were mixed: somewhat slow for the stereotypically-masculine antecedents, but essentially the same for the stereotypically-feminine and neutral antecedents.
So singular they with indefinite, non-referential antecedents apparently imposes no extra cognitive load, at least on midwestern undergraduates as of the mid-1990s. With referential antecedents who are unknown to the reader, mismatch with gender stereotypes can be a problem in some cases, especially for stereotypically-masculine antecedents; but where stereotypes are not strong, they works fine.
Ten years later, another study took up the same question, and used more sensitive experimental techniques to come to a somewhat different conclusion. The results are reported in Anthony J. Sanford & Ruth Filik, "'They' as a gender-unspecified singular pronoun: eye tracking reveals a processing cost", Quarterly Journal of Experimental Psychology, 60(2) 171-178, 2007. Their abstract:
The plural pronouns they and them are used to refer to individuals with unknown gender and when a random allocation of gender is undesirable. Despite this apparently felicitous usage, “singular they/them” should raise processing problems under the theory that pronouns seek gender- and number-matched antecedents. Using eye-tracking, we investigated whether there was any processing cost associated with using singular they/them. There was a clear cost of number incompatibility for they/them. Thus, although singular they/them is in current usage, it does not appear that they/them is immediately tolerant of a plural antecedent, though such may be rapidly accommodated. The data are consistent with the search account of pronoun resolution and preserve the semantics of they/them as denoting plurality.
S&F don't like the idea that they has a singular sense, and reckon that
It may be the case that the global self-paced reading paradigm used by Foertsch and Gernsbacher was too coarse a measure to pick up the disruption caused by a mismatch.
So they ran 36 University of Glasgow students in an experiment that used a more delicate measure, namely an eye-tracking apparatus that determined the location and time of fixations during reading. They used 24 sentence-types in four versions each, such as:
Mr Jones was looking for the station. He saw [someone/some people] on the other side of the road, so he crossed over and/ asked [them/her] / politely / where the station was. / It was in a different part of town./
Their procedure:
The materials were in four files, with each item appearing in only one of its four versions in a given file. Over the four files, it appeared in all versions. A given file comprised six materials in each of the four conditions. Each file also included 86 filler items of a similar length to the test materials, but otherwise unrelated to the present study. Texts were presented as three or four written lines, with two blank lines between each line of text to aid fixation analysis
I'm going to present the whole table of results, though only a few of the numbers really matter, so here's their explanation of the dependent measures:
We report three measures of early processing: first-pass reading time, the sum of all the fixations made in a region until the point of fixation leaves the region either to the left or the right; and regression path reading time (also known as go-past reading time), the sum of fixations from the time that a region was first entered from the left to the time that the region was first exited to the right. This measure includes fixations made to reinspect earlier portions of text and is usually interpreted as providing an indication of early processing difficulty along with time spent reinspecting the sentence in order to recover from such difficulty. We also report the incidence of first-pass regressions. These are regressions out of a region to the left from the first time that the region is entered from the left. We report one later processing measure, total reading time, which sums the duration of all fixations made within a region and provides a measure of overall comprehension difficulty at this region.
Here's their table of results (click on the table for a larger version):
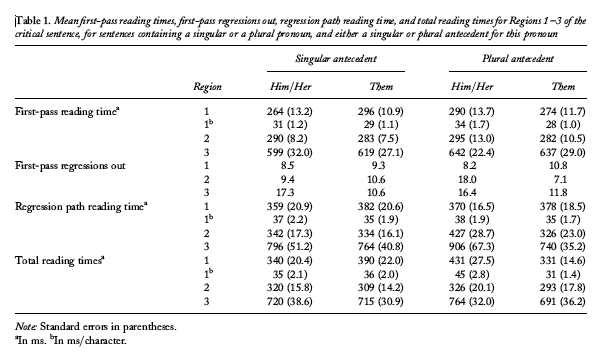
There are a number of ways to approach this data, but let's start by adding up the total reading time for all three segments. For him or her with a singular antecedent, the average was 1380 milliseconds, while for them with a singular antecedent, the average total reading time was 1414 milliseconds — a 34 millisecond difference! This difference was statistically significant, at least when the times were compared segment by segment. But the time for reading all three segments was only about 2.4% slower on average.
In contrast, him or her with a plural antecedent required an average of 1521 msec to read all three segments, while them with a plural antecedent took an average of 1315 msec, or 206 msec faster. That's a difference of about 16%.
They didn't test the disjunctive formula "him or her" for cognitive load.
Their conclusion:
While the use of they as a genderless “singular” referential pronoun in certain contexts certainly occurs and does not seem to cause problems of felicity from the point of view of casual observation, some processing difficulties were nevertheless observed in our eye-tracking study. Earlier researchers (Foertsch & Gernsbacher, 1997) found that with neutral, apparently genderless, antecedents like someone, or a runner subsequent clauses referring to that individual by he or she, or they, revealed no reliable disadvantage in the case of using they. On the surface, this might be taken as compatible with the position that there is indeed no processing disadvantage to using they as a genderless singular. In the present experiment, we increased the sensitivity of the design in two ways. First, we used continuous eye-tracking, enabling more subtle measurement of any possible patterns of disruption. Secondly, we compared the effects of genderless referential plural antecedents with that of genderless singular referential antecedents. On total time for the pronoun region, we observed a strong, conventional, number-mismatch effect, such that plural pronouns created less processing disruption in the context of plural antecedents than in the context of genderless singular antecedents.
This result is compatible with the view that after encountering a plural pronoun (they, them), a search is initiated for a plural antecedent in the mental representation of the discourse and not for one that could be either plural or singular. So where does this leave the singular use of they/them? Since it is in common use, we suggest that although it gives rise to a mismatch, it is rapidly accommodated as an acceptable deviation. This is quite unlike the case with singular pronouns in the context of plural antecedents, because these are not in common use and, we claim, do not make sense without making an inference like “he or she refers to just one of the plurality in the antecedent”.
Of course, the result is also consistent with the view that they/them is ambiguous (or vague) between plural and genderless singular, with a default preference for the plural reading, and that the slight increase in processing time is the result of resolving the ambiguity towards the non-default reading.
But crucially, despite references to questions of usage, these papers are mainly oriented towards a debate among psycholinguists about the nature of pronoun processing, not towards a debate about pronoun usage among providers of writing advice. And as a result, the experiments don't directly address the issue that really matters in most practical cases — how should you refer to a non-referential singular indefinite antecedent ("anyone"; "a student"; etc.) when you need or want to leave sex unspecified? To be relevant to this real usage debate, experiments would need to test they against "he or she" (or "she or he", or "that person", or whatever); and would also need to check systematically for the cognitive load imposed by attempts to use he as a default pronoun.
My point, however, is that it's no longer necessary to trade unsupported assertions about what is or isn't "clear" or "vague" or "confusing". Modern experimental techniques make it easy to test hypotheses about "clarity" and "ease of comprehension" and "reader confusion" and so on. If the measure is some sort of reaction time, you don't even need any apparatus beyond ordinary personal computers. So have at it, all you prescriptivists usage cranks language mavens. I'll be happy to join you in advising against splitting infinitives or stranding prepositions or using summative which and this, if you can provide sound experimental evidence that these practices cause significant problems for readers.
More seriously, clear writing is important — too important to be left to the witch doctors. So shouldn't psycholinguists devote more of their collective energy to experimental investigations of textual (un)clarity?
jaap said,
May 30, 2008 @ 6:41 am
"As you can see, the stereotype-mismatched pronouns (e.g. "truck driver … he" or "nurse … she" caused a delay of …"
There is a missing ")" and I think you swapped "he" and "she".
Mark Young said,
May 30, 2008 @ 9:15 am
Hi,
Would you mind telling us more about the sample sentences for the second paper?
In particular, what are regions 1, 2 and 3? From the relationship between the numbers in the table (264ms –> 31ms/char, 378ms –> 35ms/char), it looks like region 1 would be 8 to 11 characters long — the word(s) "someone" or "some people"? But regions 2 takes about the same time to read, and region 3 about twice as long. (Is region 3 the blue text "where the station was"? I'm so confused!)
Mark Liberman said,
May 30, 2008 @ 9:28 am
As I understand the paper, region 1 is "asked them/her/him", region 2 is "politely", and region 3 is "where the station was".
James said,
May 30, 2008 @ 10:00 am
Pardon my ignorance, but when did singular they begin to have wide-spread usage? Perhaps there is a delay in reaction time because the people tested only picked up this usage in their teen/adult life. Maybe if we ran this experiment again on a different age group, or in another 10 years, we could have native speakers who acquired singular they as they were acquiring English in infancy. Is it possible that such speakers would not have a significant difference in processing time? What about the reverse? Do older speakers, who learned English at a time when singular they was rare or non-existant, have a longer processing delay?
goofy said,
May 30, 2008 @ 10:23 am
James: "they" with a singular antecedent has been used in English writing since around 1300.
Karen said,
May 30, 2008 @ 11:21 am
James: also, anyone who "learned English when singular they was rare or non-existent" had to have that proscription beaten into them in school. English teachers spent an inordinate amount of time correcting 'them' to 'him'.
John Maloney said,
May 30, 2008 @ 11:30 am
A "crazy prescriptivist" (in your sense) could reply that concepts like
clarity and ease of comprehension are just fine, but that many written languages value things like complexity and balance of structure, allusions to old classics, use of obscure vocabulary, etc. This was certainly true in older styles of English and currently in other languages. The most esteemed prose styles of many languages can be very difficult to comprehend, even for native speakers.
I think a prescriptivist could say you're just begging the question by assuming
clarity is the main criterion by which to judge a linguistic phenomenon. Hence the psycholinguistic analysis is simply irrelevant to making judgements about it.
Stephen Downes said,
May 30, 2008 @ 11:59 am
> they ran 36 University of Glasgow students in an experiment…
If the sample were of sufficient size, and representative of English speakers in general, then the results of the study might be call 'evidence'.
Not otherwise.
Bill Walderman said,
May 30, 2008 @ 12:04 pm
A link for James:
Bill Walderman said,
May 30, 2008 @ 12:05 pm
A link for James to copy into his browser:
http://www.crossmyt.com/hc/linghebr/austheir.html
Sorry, it didn't work the first time.
James said,
May 30, 2008 @ 1:33 pm
So we need some native English speakers from the 13th century in order to get a group of people for whom this is rare or non-existant? I think there is a problem with my earlier suggestion…
Rubrick said,
May 30, 2008 @ 1:39 pm
"More seriously, clear writing is important — too important to be left to the witch doctors."
True, although I'd rather enjoy seeing William Safire with a bone through his nose.
Mark Liberman said,
May 30, 2008 @ 2:00 pm
@Stephen Downes: I certainly agree that we need to be cautious about drawing general conclusions from experiments run on a few undergraduates in one time and place. I've made this point in a number of posts criticizing overinterpretation of small and demographically unrepresentative studies as demonstrating differences between men and women, for example.
However, some evidence on points like this is better than no evidence at all, which is what most language mavens making claims about clarity and readability have. (That doesn't mean they're wrong — just that they're making testable claims for which the only evidence is their own intuition.)
And in this case, we see that undergraduates in Madison WI in 1996 and undergraduates in Glasgow Scotland in 2006 behaved in roughly the same way. Since their behavior is consistent with what we would expect given the widespread use of they with non-referential indefinite antecedents, I'd be willing to wager a substantial sum on how a larger and more demographically representative sample would behave.
Bill Walderman said,
May 30, 2008 @ 2:15 pm
I wonder whether the S&F study was sensitive to the distinction drawn between drawn in the F&G study between (1) sentences in which singular "they" referred to an indefinite antecedent and (2) sentences in which singular "they" referred to an antecedent whose characteristics were known to the writer but not to the reader. I think that singular "they" is more acceptable to many English speakers in the first class of sentences than in the second, and I suspect that failing to make that distinction could skew the results.
Mark Liberman said,
May 30, 2008 @ 2:31 pm
@Bill Walderman: Yes, I agree that this distinction is important , though I think that the later study limited its scope to cases where either the characteristics of the referent(s) are unknown to the writer, or else it's not clear one way or the other.
But really, do you see how rich the field of Prescriptivist Psycholinguistics is, even in this one domain of "singular they"? There's material here for dozens of dissertations…
Dance said,
May 30, 2008 @ 6:46 pm
I was trying to imagine what actual quantifiable research into summative "this" might look like. But it seemed everyone agreed that in some cases summative "this" works fine and in some cases it's better to add a noun, and it all depends on context. So I thought the research question would be "how *often* is summative "this" actually used in cases where an additional noun is preferable for comprehension?" Rather than "does summative "this" slow down comprehension?" Examining empirical use, rather than trying to elicit a model.
Mark Liberman said,
May 30, 2008 @ 9:30 pm
@Dance: We know what it's like when readers (or listeners) are confused about anaphor reference. So it would not be too hard to test the hypothesis that summative "this" or "which" is *always* confusing, or is *always* more difficult to process than the same phrase with a noun of the appropriate type added.
One way to approach this would be to take some text from a high-quality source where summative "this" and "which" are common, and compare processing time with and without added nouns. I guess you could also look at cases where the nouns were present in the original, [a situation] which will be fairly common as well, and see whether "omit needless words" causes cognitive difficulties in those cases.
Another limiting case is how well people can agree about the referent of such discourse anaphora, independent of time pressure — are intersubjective agreement rates uniformly worse for one type of anaphor compared to another? In a later post, I'll discuss some recent work of this kind.
Jonathon said,
May 31, 2008 @ 1:27 am
John Maloney: According to a lot of prescriptivsts, clarity is the main criterion—or at least one of the main criteria—for judging an item of usage. I think Mark Liberman is simply responding to arguments that prescriptivists have made. Whether or not clarity should be the main criterion is another issue.
Dance said,
May 31, 2008 @ 9:47 am
One way to approach this would be to take some text from a high-quality source where summative "this" and "which" are common, and compare processing time with and without added nouns.
Yeah, like the Mill examples from the previous post. But I was thinking either people would have to read the same text twice, in which case the second time is a repeat, or you have to get test subjects all calibrated to have roughly the same reading speed and ability to comprehend something like Mill—I'm sure reading speed is usually accounted for, but I boggled on the other. I suppose two very similar Mill passages, each tweaked to opposing extremes, could work around that issue.
But I still think setting out to test an *always* hypothesis is asking the wrong question—who really believes that in the hands of a good writer, summative this still *never* works just as well? I guess the test could be done with writing universally acknowledged to be average.
Another limiting case is how well people can agree about the referent of such discourse anaphora, independent of time pressure
Now that approach sounds very intriguing, thanks. And easier to set it to test hypotheses such as "preceded by a short declarative sentence, summative 'this' offers no detriment" or "summative 'this' when beginning the last sentence of a paragraph troubles comprehension." So that the aim is to develop a model to guide the contextual judgment necessary for effective use of summative "this". Which strikes me as more useful than simply proving an always/never hypothesis. Though I'm not entirely sure such a model would qualify as *prescriptivist* science.
Rick said,
June 1, 2008 @ 3:46 pm
Is there any "prescriptivist science"? Could there be any? The reaction of some linguists will be that "prescriptivist science" is as much as a contradiction in terms as "creation science" is. But I disagree.
Perhaps the analogy could be made to "applied science?"