HTER
« previous post | next post »
I'm in Marrakech for LREC2008, and so I should be blogging about all the interesting things going on here. But instead, at least today, I'm going to post the first installment of something that's been on my to-blog list since early April.
At the P.I. meeting of the DARPA GALE program, there was a panel discussion, chaired by Philip Resnik, on on the topic of Chinese-English machine translation. Or rather, according to Philip's introductory slide, on the topic "What the @#$% Do We Do About Chinese-English MT?"
Why was this question a relevant one? Well, once again the results of quantitative evaluation of Chinese-English MT were disappointing. Compared to Arabic-English, the program's targets for Chinese-English were lower, and yet the performance relative to the targets was worse. Here's a graphical representation of the results of two tests, Phase 2 and Phase 2.5, on Chinese newswire (where the target for 100-HTER was 75%):
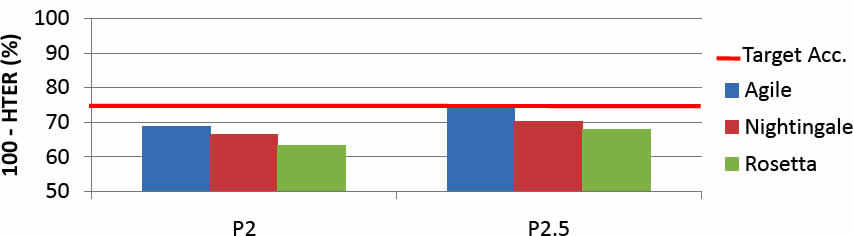
(As usual, click on the picture for a larger version. And FYI, "Agile", "Nightingale" and "Rosetta" are the names of three competing teams in the project.) Here are the results for translation of Arabic newswire (where the target for 100-HTER was 80%):
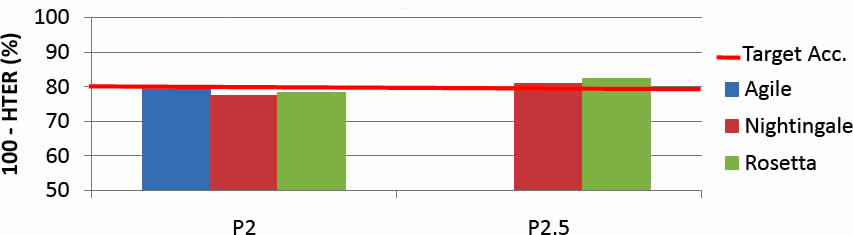
For those who are keeping score at home, I should say that the targets were not for the average HTER score — rather, 90% of the translated material had to be at the target or better. But, you may be asking, what does this mean? Let's pause for a moment to explain this HTER (or "100 minus HTER") business.
HTER ("Human-targeted Translation Error Rate") is an edit-distance measure: "the fewest modifications (edits) required to the system output so that it captures the complete meaning of the reference, using relatively fluent English". The formal definition is:
HTER = (Substitutions + Insertions + Deletions + Shifts)/Reference Words
Skilled monolingual human editors compare MT output against a reference translation, and modify the MT output so that it has the same meaning as the reference, and is "understandable" English. Each inserted/deleted/modified word or punctuation mark counts as one edit, where shifting a string of any number of words, by any distance, counts as one edit.
After the human editing of the MT output, a program compares the unedited MT output to the human-edited version and to the reference translation, and finds the minimum number of edits that will create one or the other of these.
Here's one example:
| Reference ("Gold standard") translation: | Three employees of a haulage firm have been arrested on suspicion of dumping the chemical waste. Currently it is not yet clear what the waste is that came from the plastics plant. |
| MT Output: | Of the three officers arrested for dumping the chemical waste, a freight industry is still not clear what is the waste from a plastics factory. |
| HTER: | three officers of a freight industry were arrested for dumping the chemical waste, but it is still not clear what the waste is that came from a plastics factory. |
We can represent the deletions in red, the insertions in green, and the shifts in blue:
Of the three officers of (1) were arrested for dumping the chemical waste, (1) a freight industry but it is still not clear what (2) is the waste that came from a plastics factory.
Error count = 10 (2 deletions, 6 insertions, 2 shifts)
Word count = 34
HTER = 29.412
[I discussed another automatic MT evaluation metric in one of the first LL posts, "The value of evaluation", 7/30/2003.]
Here's a graphic showing some further details of the scoring process:

Left for a later post: what some of the panel participants thought about why Chinese is so hard.
For now, here's one example of a case where Google's Chinese-English translation failed in part to produce comprehensible output, exhibiting some of the relevant issues:
昨天下午,当记者乘坐的东航MU5413航班抵达四川成都“双流”机场时,迎接记者的就是青川发生6.4级余震。
Yesterday afternoon, as a reporter by the China Eastern flight MU5413 arrived in Chengdu, Sichuan "Double" at the airport, greeted the news is the Green-6.4 aftershock occurred.
There are two place names that have been translated by (part of) the base meaning of their consituent morphemes. Thus “双流”机场, which should have been "Shuangliu" Airport, instead came out as "Double" at the airport. Here are the entries from the Chinese-English dictionary at mandarintools.com
双流 Shuāng liú (N) Shuangliu (place in Sichuan)
双 shuāng two; double; pair; both
流 liú to flow; to spread; to circulate; to move
And 青川, which should have been Qingchuan — the town closest to the epicenter of the aftershock — instead contributed the Green in Green-6.4.
青川 Qīng chuān (N) Qingchuan (place in Sichuan)
青 qīng green (blue, black)
川 chuān river; creek; plain; an area of level country
Let me say, to start with, that I think it's amazing that automatic translation of this quality exists and is freely available on the web. And Google translates 双流 correctly (as Shuangliu) if it's presented without quotation marks, but as "Double" if the input is presented in quotes; and likewise 青川 by itself is translated correctly (as Qingchuan), but 青川6.4 is translated as Green-6.4, and 青川发生6.4 as Green-in 6.4. Thus the vagaries of phrase-based statistical MT
Of course, there are obviously some other problems in word order and so on — I'll leave it to the reader to calculate the HTER.
Dan T. said,
May 27, 2008 @ 2:35 pm
Some languages seem to be harder than others for automated translation. Korean, for instance, seems to always come out as incomprehensible word-salad when translated automatically into English, or at least that has been my experience when I've tried it.
Robert said,
May 28, 2008 @ 1:42 am
Is the difficulty of machine translation correlated with how analytic or synthetic the language is? The two extremes would seem to pose different challenges.
Brett said,
May 28, 2008 @ 11:46 am
"Korean, for instance, seems to always come out as incomprehensible word-salad when translated automatically into English." Yes, but try translating it into Japanese and the results are lovely.