The language of phone numbers
« previous post | next post »
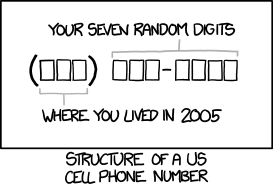
What xkcd is getting at with the latest comic is about syntax and semantics. I'll show you the syntax below, but as far as meaning is concerned, the point is that cell phone numbers have almost no semantics. The area code part (the first three digits) used to function as a locational marker when phones were in fixed locations in houses, but since Americans not only tend to move every three years or so but they now take phone numbers with them, and cell phone universality only really began to pick up in America five to ten years ago, it really does tend to reflect a former abode. My cool son Calvin, for example, has a number which implies that he lives in Oakland, California; he doesn't, he does his video game programming in the Pacific North West.
And the rest of the number, the other seven digits? Space enough there for some real personal information, but it is not used. It functions merely as arbitrary material to distinguish one cell phone's location point in the information universe from all the others.
With 10-digit strings we can distinguish roughly 10,000,000,000 phones from each other. That assumes someone can have the number 000-000-0000, which is probably God's number; and sure, maybe Satan has laid claim to 666-666-6666, so it's not available; but we're only being approximate here. The bottom line is that there's enough space in principle for everyone in the USA to have 20 or 30 different cell phone numbers, if we use it efficiently.
But we don't. I have often stared at documents like gas bills and been amazed to see things like account numbers or other identification numbers as long as 18 or 20 digits. There are only about 7 × 109 people in the world. Some account numbers are so long you could give separate account numbers to every member of the population on a billion planets with populations like ours. Those numbers could record the addresses and ages and incomes of the customers instead of just being random digit strings. But we don't do that. The information society that people get so worried about — the world in which The Government knows all your details and tracks everything you do — hasn't arrived yet, and probably never will. We're not that organized as a species. We waste too much time and too many of our computational resources keeping track of pointless random digit strings and being unable to relate them to each other.
(You may say I'm not paranoid enough about government intrusion and snooping, but I say that a civilization in which it is all but impossible to get duplicate entries out of junk mail address databases is not a civilization that is going to be able to figure out how to correlate your pornography rentals, golf club memberships, gas bills, and political leanings. I'm not saying they aren't evil enough to do it; I'm saying they're too incompetent to do it.)
Now for the syntax of cell phone numbers (I did promise). The syntax of North American phone numbers — the only phone numbers you can enter in many databases, which is truly a curse for someone like me who commutes across the Atlantic — can be described by a grammar in which the dictionary is {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, -}, the "parts of speech" (syntactic categories for words and phrases) are {N, A, B, C, D, E, F}, and the rules say that a phone number consists of a 3-digit area code and a body with a separator between them; that a body consists of a 3-digit exchange code and a 4-digit local number with a separator between them; and that the digits are {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, -}. This is how it is done with precision:
- N → A C B
- A → D D D
- B → E C F
- C → –
- E → D D D
- F → D D D D
- D → 0
- D → 1
- D → 2
- D → 3
- D → 4
- D → 5
- D → 6
- D → 7
- D → 8
- D → 9
This is a rewriting system — what Noam Chomsky calls a generative grammar. You start by writing down an N, and then read the arrow as "may be replaced by". The grammar describes a set: the set of all and only those digit strings that you can arrive at through some series of string rewritings that the rules permit. (There are techniques for abbreviating such grammars, like writing the last ten rules as "D → 0|1|2|3|4|5|6|7|8|9|-", but I haven't bothered to use them.) If you like, you can think of the capital letters as having these mnemonic meanings:
- N: Number considered as a whole
- A: Area code (or rather, what was once an area code)
- B: Body of the number
- C: Character like hyphen or space for separating segments
- D: Digit chosen from {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
- E: Exchange (or what used to be the exchange back in 1950)
- F: Four random digits with no pretense at any meaning at all
A sequence of strings licensed by the rules is called a derivation. It's essentially a proof that a certain string is indeed a cell phone number. Here's a proof that shows, by building the number steadily from the left hand side according to the rules, that 202-466-1033 is a possible cell phone number (though actually it's the landline number for The Chronicle of Higher Education). N is the first line; every derivation starts with that. Each subsequent line is formed from the previous line by applying just one of the rules.
A C B
D D D C B
2 D D C B
2 0 D C B
2 0 2 C B
2 0 2 – B
2 0 2 – E C F
2 0 2 – D D D C F
2 0 2 – 4 D D C F
2 0 2 – 4 6 D C F
2 0 2 – 4 6 6 C F
2 0 2 – 4 6 6 – F
2 0 2 – 4 6 6 – D D D D
2 0 2 – 4 6 6 – 1 D D D
2 0 2 – 4 6 6 – 1 0 D D
2 0 2 – 4 6 6 – 1 0 3 D
2 0 2 – 4 6 6 – 1 0 3 3
It's probably possible to make a similar grammar for the whole of English. It might start (using S for "sentence", NP for "noun phrase", VP for "verb phrase", D for "determinative", N for "noun", etc.) like this:
S → NP VP
NP → D N
VP → V NP
. . .
And so on for the rest of English sentence structure (see The Cambridge Grammar of the English Language for an informal overview of the other details you'd have to cover). Piece of cake. A few more decades and we linguists will have it done.
Keith M Ellis said,
November 2, 2012 @ 3:39 pm
Just a note that some very long numbers, such as credit card numbers, are deliberately long so that it's unlikely that a valid number could be picked at random. Also that "we waste too much […] too many of our computational resources keeping track of pointless random digit strings" is really not at all true; the length of identifiers like these is utterly unimportant in the context contemporary data storage.
[Keith: Yes, I'm aware that 20 bytes per customer is not going to cause the disks to fill up at the server farm. I'm not suggesting that the systems in use are too small; I'm suggesting that what is done with them is too randomly insane. One example from just this morning I was given about 70 pages of documents in hard copy (apparently mandated by Federal regulations) by a banking company that had opened some transferred accounts for me, and on one page was a key to the list of codes for professions that took up maybe 10 square inches (A = executive, B = legal, C = medical, D= engineering, F = other professional… that sort of thing), with about 20 or 30 categories. And the key was necessitated by the fact that the database allowed only one letter to record my profession (I = education) on the form on the previous sheet. What the hell is that all about? Why insist on a length limit of one letter for profession information if you are then going to have to devote an eighth of a page of boilerplate to explaining the system of one-letter codes? It's just one small random example from today of why I frequently think present-day information systems are nuts. There are many others. Like the banking system I use that allows a 38-character text description (way too short) to accompany a transfer of money to someone else's account, but the system forbids commas, colons, semicolons, question marks, exclamation points, parentheses, plus signs, equals signs, quotation marks, and numerous other ASCII characters. Why?? (And I don't even want to know what my bank is actually using to store its financial information. I have a friend who is a banking computer security expert, and I have heard tales of ancient IBM mainframes in chilled basements still running unintelligible COBOL programs that have been patched multiple times but couldn't be rewritten because nobody really knows what they say or how they do what they do.) I could go on… but I really mustn't.—GKP]
James Iry said,
November 2, 2012 @ 3:59 pm
Many assigned numbers are long for reasons beyond uniqueness
1) Built in error detection requires redundancy.
2) Some numbers include semantics which constrain the valid values in parts of the number.
Credit cards and many other account numbers exhibit both error detection and semantic fields. http://en.wikipedia.org/wiki/Bank_card_number
Chris said,
November 2, 2012 @ 4:20 pm
Without getting into the full details of the NANP, it's worth noting that there are some extra rules in place to make numbers like "0" and "911" work, and to use 7-digit numbers when local. I'd write it more like:
S → 0 | M | B | L
M → D2 1 1
B → 1 C A C L
A → D1 D2 D2 | D1 1 D2 | D1 D2 1
L → D2 D0 D0 C D0 D0 D0 D0
D2 → 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
D1 → 1 | D2
D0 → 1 | D1
C → –
S
0
S
M
D2 1 1
9 1 1
S
B
1 C A C L
1 – A C L
1 – D1 D2 D2 C L
1 – 2 1 5 C L
1 – 2 1 5 – L
1 – 2 1 5 – D2 D0 D0 C D0 D0 D0 D0
1 – 2 1 5 – 5 5 5 – 5 5 5 5
7-digit numbers are disappearing, for the reasons given above, but 911 will be around for a long time. 0 ("operator") seems antiquated already.
(for reference: Start, Mnemonic, Big, Little, Area, Digit, Connector)
Wonks Anonymous said,
November 2, 2012 @ 4:22 pm
One of my favorite xkcd's is about the benefit of having a longer string of random digits:
http://xkcd.com/936/
[Agree: I loved that one. Frightening though it is.—GKP]
Jim said,
November 2, 2012 @ 4:26 pm
Ah, good ol' context-free grammar. :) As a programmer I would probably write it something like this:
phone-number = area-code "-" base
area-code = 3digit
base = exchange "-" local
exchange = 3digit
local = 4digit
digit = 0-9
The cool thing is that there's tools which can take a grammar like this and automatically produce code which will parse input that fits the grammar or warn you if it doesn't.
Saul Reynolds-Haertle said,
November 2, 2012 @ 4:29 pm
Some very long numbers, mostly when dealing with computers, are deliberately long so that you can generate a new unique number by picking one at random – that is, it's so unlikely that a valid number could be picked at random that it's safe to just randomly generate a new value and use it. This is used when throughput is important, for example, in databases and websites, or when checking uniqueness is difficult, for example, when making network cards and you have to make sure that you and your competitor never accidentally give two pieces of hardware the same address.
Dan Parvaz said,
November 2, 2012 @ 5:25 pm
Further allowances could be made for more traditional US phone numbers where area codes, for example were as follows:
A → [2-9] [0|1] [2-9]
And Payphones were
PP → A E PL
PL -> [2-9] [2-9] 99
… in fact, we'll call that the grammar; any innovations, we'll just throw into the lexicon :-)
Dan Parvaz said,
November 2, 2012 @ 5:26 pm
Oops, make that:
PL -> [0-9] [0-9] 99
Richard Moloney said,
November 2, 2012 @ 5:49 pm
What I find interesting is that, in the United States, there is a universally accepted subdivision of a phone number as (3 digits) (3 digits) (4 digits), which translates over into speech. When I moved to the States for a short time last year, I wasn't aware of this and was surprised how disconcerted people could get when I told them my phone number. So if I told them was 111 – 1111 – 111 they might reel a little before asking me if I meant 111 – 111 – 1111.
kkm said,
November 2, 2012 @ 5:55 pm
There's a typo in Chris' grammar: The rule for D0 should be
D0 → 0 | D1
Jeff Carney said,
November 2, 2012 @ 6:31 pm
I actually work in one of those corners of the world where almost every part of my (landline) office number is genuinely semantic.
Area code (435) indicates my office is in rural Utah
3-digit prefix (283) indicates it is in a town called Ephraim
Non-random first digit of the remaining four (7) indicates that it is on the college campus located in that town.
So there are only 3 truly random digits in my number. I can imagine a campus where those could actually correspond meaningfully to my physical location (D2 = building, D3+D4 = office) but we would have to sacrifice the semantics of room numbers for that to work.
One possible solution is assigning the college its own prefix (this is not uncommon) so as to free up D1. This would work for a campus with 10 buildings (of the sort that require phones) of 10 stories each, each story being permitted 100 rooms where phones must be used. That describes my campus pretty well. In 2012, anyway.
The power solution would include changing all telephone number pads so that the letters a-f can be used for hexadecimal representations. This would allow for 16 16-story buildings with 256 rooms on each floor. I'd still be limited to 10,000 actual phones, but I don't imagine we'll need to put up that many 16-story buildings for quite a while.
By then, of course, keypads will be functionally hexadecimal.
peterv said,
November 2, 2012 @ 6:46 pm
@Richard Moloney:
Telephone operators in the Bell system (and in other national telecommunications systems) adopted a standard way of speaking numbers. Thus, for instance, 111 would be "one, double-one" and 1111 would be "double one, double one".
mgh said,
November 2, 2012 @ 10:09 pm
This seems like a good place to remember Allan Sherman's 1963 "Let's All Call Up AT&T And Protest To The President March", in opposition to the popularization of direct digit dialing http://www.youtube.com/watch?v=vYnpfi2vdrI
Reinhold {Rey} Aman said,
November 2, 2012 @ 10:17 pm
@ Richard Moloney:
What I find interesting is that, in the United States, there is a universally accepted subdivision of a phone number as (3 digits) (3 digits) (4 digits), which translates over into speech. When I moved to the States for a short time last year, I wasn't aware of this and was surprised how disconcerted people could get when I told them my phone number. So if I told them was 111 – 1111 – 111 they might reel a little before asking me if I meant 111 – 111 – 1111.
Related problem: Spoken five-digit postal ZIP-codes have to be grouped as (3 digits) + (2 digits) separated by a pause (-) to avoid confusion. I had to instruct a local reference librarian (Santa Rosa, Calif.) of this standard. Instead of saying "606 – 12" (standard), he would say "60 – 612" (confusing, because of wrong rhythm); 606 = Chicago. He also messed up Canadian postal codes: instead of the standard grouping, e.g., "M5W – 1G3" (Toronto), he would say "M5 – W1 – G3". Oy!
Keith M Ellis said,
November 2, 2012 @ 10:49 pm
Geoffrey, I suspected you knew full well that long numbers are not a data storage problem, but you did write it in a way that seems to make that claim unambiguously.
But, yeah, what you complain about in your comment-response is infuriating. I'm pretty sure, though, that it's partly due to legacy concerns and partly due to what we might call legacy thinking. I'm not sure how contemporary database and systems designers are trained, you'd hope that they'd realize that the days of necessarily cryptic abbreviations are long gone.
I don't doubt that a bunch of back-end stuff is still COBOL stuff, though much of it has been moved from the mainframes it used to run upon.
My father was one of those old-school COBOL mainframe programmers and systems analysts — he was trained to write, and renowned as being adept at writing, extremely storage-efficient code. Which, in those days, also very much meant database efficiency. If, like him, you started out as a keypunch operator, you probably had a visceral motivation to be very economical.
There really isn't any reason anymore why actual humans ever need to worry about cryptic alphanumeric symbolism for records and IDs and such, the IT infrastructure now is fully capable, both in speed and storage, to entirely mediate that out of visibility. That includes phone numbers, postal codes, many other things.
But we still have a lot of this mysterious, unwieldy stuff because of legacy inertia.
Back in 1997, or so, I worked for one day at IBM on big, special-built, phone switching computers — I have a congenital bone/joint disease and I wasn't aware when I accepted the job that the assembly work involved was something that I really wasn't able to do. (There were two techs assigned to build and test each switch, which took a couple of weeks each.) Anyway, it was quite interesting, as there was right at that time a burgeoning market for these big long-distance exchange switches because of a recently passed federal law that required full number portability. It was explained to me that these new switches would fill-in the system at that area-code switching level to allow nationwide number portability. I recall thinking, boy, it sure is about time for that sort of thing (although, honestly, I had some awareness of the phreaking world in the early-80s and it is pretty amazing how quickly the phone system went from an analog/digital hybrid to fully digital).
And yet … we're still using area codes in a geographically-bound fashion. Many cell customers themselves don't, because for other cell customers there's no cost difference, even if it's long-distance. But I'm not sure that these out-of-area calls are switched as if the numbers were truly portable, as opposed to, well, out-of-area. Probably, this would require that you could have your number transferred to your new area, which, as far as I know, you still can't do across area codes. But I'm certain that it's possible in the existing technology and has been for at least fifteen years. (Maybe it took awhile to roll those switches out everywhere, though.)
Michael B said,
November 2, 2012 @ 11:06 pm
I have found, when filling in boxes online, that a 10-digit phone number (e.g., 2022022020) causes no problems. However, a nine-digit zipcode (e.g., 123212131) usually gets rejected, as does a zipcode expressed as 5+4 digits (e.g., 12321-2131). Why?
And, while we're on this topic, can I say how utterly confusing, as an American who speaks reasonably good French, I find the French convention for stating phone numbers? For instance, if memory serves, 76 67 84 96 is rendered as soixante-seize, soixante-six, quatre-vingts-quatre, quatre-vingts-seize. Or does memory fail?
John Roth said,
November 2, 2012 @ 11:50 pm
Actually, it is (or at least was) more complex than that. At one time neither area codes nor exchanges could start with 0 or 1, and area codes had to have 0 or 1 as the second digit. The first constraint was to allow 0 and 1 to be used as operator and long distance prefixes, and the second was to allow area codes to be identified before the rest of the number had been entered. Also, the sequence 11 as the second and third digit is reserved for special purposes – 911 being one of the possibilities.
A lot of the mess is simply local politics. I've lived in parts of the country where there are multiple area codes serving the same geographic territory; adding an additional block causes absolutely no public hassle. I've also lived in parts of the country where they decided to split a territory into two different area codes, causing a huge amount of hassle for everyone concerned. It's simply local politics.
Mark Mandel said,
November 3, 2012 @ 12:06 am
What I find most frustrating about phone numbers, ZIP codes, and numerical dates (today is 11/3/12, or 2012-11-03 (ISO), or 20121103, or 110312, or…) is how unforgiving most web pages are.
* A single field: Enter the number with hyphens (per the grammars here) or spaces, and
** the field stops accepting the characters because it's counting the separators: [212-567-90][STOP], or
** you finish entering all the data on the page and hit SUBMIT (TO OUR RIGID ELECTRONIC RULE, YOU POWERLESS BLOB OF MOSTLY WATER!), and you get an error message, probably buried somewhere on a page three screens long, which tells you you've done something wrong but doesn't say what. If you're very lucky, it tells you the problem's in the number. If you're very unlucky, the site has thrown away everything you entered on the form.
* A field with subfields:
** Each subfield expects exacly n characters. It may say mm dd yy underneath the fields, in dark grey on pale grey or vice versa because the programmers, unlike humans,‡ think it's natural to always use leading zeros and don't see any need to change nature or to expect anyone to do anything differently. So you casually type 11 1 12, and when you SUBMIT, the page yells at you for entering an invalid date, 11 11 2 or 01 11 12.
‡ </Sarcasm> Some of my best friends are programmers.
In my freshman year of college in Annapolis, the phone numbers had only five digits.
Satan's number would be more like 666-7734.
Keith M Ellis said,
November 3, 2012 @ 2:06 am
You probably meant "999-7734", right?
Keith M Ellis said,
November 3, 2012 @ 2:12 am
(Also: Aha! Fellow johnny!)
Andrew Shields said,
November 3, 2012 @ 3:07 am
Regarding Richard Moloney's remark:
Back around 1990, I had a friend in Philadelphia whose phone number was 4945649. I remembered the number as 49 456 49, simply because it was so easy that way. But when another friend asked me for that number and I recited it that way, he didn't understand it. And I couldn't recite it the conventional way! So I had to write it down for him.
Cy said,
November 3, 2012 @ 3:17 am
@Mark Mandel
Yes. Truly, truly awful. You suggest programmers are human, but I doubt your claims without some tests. They also limit alphanumeric input boxes, with the infamous impossibility for anyone with a last name of Ng or Le to happily apply to college, or arbitrarily short cut-offs. I have a long first name+last name (but not a statistical outlier by any means!) that always was truncated on scantrons throughout my education, leading to all kinds of problems matching scores to the person. My wife was not given a middle name, and it caused so much trouble she just eventually made one up as a kid. That was a lot of fun to explain when renewing the passport, and it took more than a year because of that for her to change her last name. And since I'm talking anyway, and GeoPull has left comments open to a bunch of cranks such as myself, my wife's mother had the same maiden name as her married name, so she automatically is rejected whenever people try to run her info for credit, because of course it's an error! But she's Vietnamese – 60% of the population has that surname. All of these things are great assignments for students learning regular expressions – we should farm them out to the programmers in-training.
Stephen Checkoway said,
November 3, 2012 @ 4:32 am
Are you claiming that English is context-free? http://acl.ldc.upenn.edu/J/J84/J84-3002.pdf claims via a basic proof technique for nonCFLs (intersect a regular language with a CFL to get a nonCFL) that English is not CF. The math is simple, the linguistics is far outside my area of expertise so I can't evaluate that. Is it wrong?
Jonathan D said,
November 3, 2012 @ 6:37 am
I have trouble telling anyone my own phone number, because it's much easier to remember as xx-xxxx-xx than the xxxx-xxxx I try to say as.
MattF said,
November 3, 2012 @ 7:19 am
Back in the old (pre-area code) days, the first three characters in a New York City seven-character telephone number identified the 'exchange' and referred to a specific neighborhood. I wonder how people now interpret the title of the novel (and movie) 'Butterfield 8'… In any case, when I was growing up, my telephone exchange was mid-Queens 'Twining 7', which my dad always used to jokingly change to 'Twinkle 7', a species of joke that is now obsolete.
Rod Johnson said,
November 3, 2012 @ 9:00 am
@Stephen Checkoway: It was conventional wisdom from The Logical Structure of Linguistic Theory on that human language is not context-free. Then starting in the late 70s, I guess, there was a flurry of work questioning transformations, and probably the most thoroughly worked-out alternative, Generalized Phrase Structure Grammar, explicitly proposed a context-free alternative. GPSG was largely the work of Gerald Gazdar and one Geoff Pullum. So I would say the answer is probably yes… but the remark you're responding to isn't, I don't think, that proposal. Instead it's an ironic reference to the naive belief that many generative grammarians had in the early days that syntax had been for the most part figured out, and the rest was mere detail. Suffice it to say, things turned out to be more complicated than that.
Rod Johnson said,
November 3, 2012 @ 9:18 am
(Geoff may want to correct me, of course. But if you're interested in a first-person account of how GPSG came about, you might want to look here.)
Erik said,
November 3, 2012 @ 10:06 am
It's amazing how interesting phone numbers can be made. But no mention of the fact that country calling codes are are prefix-free?
Mr Fnortner said,
November 3, 2012 @ 11:12 am
So what does the phone switch do with overlong numbers, such as are formed when words are used (for marketing purposes) for the digits, as in: "Call HIRE-A-PLUMBER" for "Call 447-3275", and the dialer punches in "447327586237"? And does the grammar need to be adapted to account for garbage digits at the end?
Brian said,
November 3, 2012 @ 11:36 am
Most telephone systems ignore excess digits, so overlong numbers do no real harm.
Rod Johnson said,
November 3, 2012 @ 2:19 pm
Right, but if you're trying to parse a number according to the rules above, what do you do when there are extra digits? It's like trying to parse a sentence like "John loves Mary Sally Bill."
Stephen Checkoway said,
November 3, 2012 @ 2:47 pm
@Rob Johnson: I don't follow your comment. If I'm understanding correctly, GPSG is equivalent to a CFG (you wrote alternative but Wikipedia writes, "One of the chief goals of GPSG is to show that the syntax of natural languages can be described by context-free grammars"). If that's true and if the proof in the paper I linked is correct, then English cannot be described by a GPSG.
[(myl) With respect to things like the sluicing construction that plays a key role in the Postal & Langendoen paper, you should take a look at G. Pullum, "On Two Recent Attempts to Show that English is Not a CFL", 1985. For a slightly more modern take on the general question of the appropriate mathematical characterization of natural language syntax, you might be interested in e.g. Aravind Joshi et al., "The Convergence of Mildly Context-Sensitive Grammar Formalisms", 1990. The abstract:
Investigations of classes of grammars that are nontransformational and at the same time highly constrained are of interest both linguistically and mathematically. Context-free grammars (CFG) obviously form such a class. CFGs are not adequate (both weakly and strongly) to characterize some aspects of language structure. Thus how much more power beyond CFG is necessary to describe these phenomena is an important question. Based on certain properties of tree adjoining grammars (TAG) an approximate characterization of class of grammars, mildly context-sensitive grammars (MCSG), has been proposed earlier. In this paper, we have described the relationship between several different grammar formalisms, all of which belong to MCSG. In particular, we have shown that head grammars (HG), combinatory categorial grammars (CCG), and linear indexed grammars (LIG) and TAG are all weakly equivalent. These formalisms are all distinct from each other at least in the following aspects: (a) the formal objects and operations in each formalism, (b) the domain of locality over which dependencies are specified, (c) the degree to which recursion and the domain of dependencies are factored, and (d) the linguistic insights that are captured in the formal objects and operations in each formalism. A deeper understanding of this convergence is obtained by comparing these formalisms at the level of the derivation structures in each formalism. We have described a formalism, the linear context-free rewriting system (LCFR), as a first attempt to capture the closeness of the derivation structures of these formalisms. LCFRs thus make the notion of MCSGs more precise. We have shown that LCFRs are equivalent to muticomponent tree adjoining grammars (MCTAGs), and also briefly discussed some variants of TAGs, lexicalized TAGs, feature structure based TAGs, and TAGs in which local domination and linear precedence are factored TAG(LD/LP).
]
Rod Johnson said,
November 3, 2012 @ 6:54 pm
@Stephen: When I said GPSG was a context-free alternative, I meant alternative to Chomskyan theory. One of the major claims of LSLT (if I remember correctly—maybe it was Syntactic Structures), was that natural languages could not be described by a CFG, and a more powerful class of grammars (which might or might not include transformations) was necessary. As part of the late 1970s reaction what was felt to be a theory that was too powerful (or overly abstract or not learnable), a number of people tried to argue that this claim was incorrect, which meant that they had to show that English could be described by a CFG (in GPSG's case, augmented with "slash categories" to handle long-distance dependencies).
In that context, the Postal and Langendoen paper was an attempt to save the Chomskyan account by showing that even these enhanced CFGs were inadequate, but like most disputes of this sort, there was never a definitive resolution. I don't think Postal and Langendoen's "proof" was really accepted as such by their opponents; instead both sides just moved on. Gazdar's a good example—he ultimately stopped arguing about the explanatory value of the theory and focused on its practical value in natural language processing.
J.W. Brewer said,
November 3, 2012 @ 9:33 pm
I haven't lived in the location implied by my cell #'s area code since 2004 (although I didn't move far and still commute into that location to work). When I still lived in Manhattan, my landline # began 289- which I eventually realized was a relic of the old days, viz. BUtterfield 9, and my current landline number's first two digits correspond to the first two letters of the town's name, which I assume is not a coincidence. For an example of actual non-random information encoded past the exchange number, when I was in college in the 1980's (although I believe the situation has since changed on the campus in question, both as to the room-numbering system and as to the propensity of undergraduates to want to have a landline in their rooms), the vast majority of undergraduate rooms were numbered according to a master system with unique three or four digit identifiers which (with a leading zero for a three-digit number) corresponded to the last four digits of the room's phone number.
jf said,
November 3, 2012 @ 10:22 pm
Just one other point about NANP, the North American Numbering Plan. Once competition began to take hold for local ervice in the late 1980's, alternative suppliers were given numbers to llocate in blucks of 10,000, ie, they were given an entire three digit prefix in any area code they offered service. This leads to a large number of wasted numbers as each competitor gets 10,000 numers no matter how many customers he served and as soon as he got to 10,001 he got a new block of 10,000. Number portability rules in the mid 2000's (which are the source of the xkcd observation) are what freed up a lot of space, at the expense of much more complicated lookups
maidhc said,
November 3, 2012 @ 10:45 pm
I'm reminded of the old Harry Tate comedy where he had the telephone number "one one double-one eleven eleven one".
Lugubert said,
November 4, 2012 @ 5:32 pm
Close to an actual example: A person a few years older than me might have a Swedish civic registration number starting with 410410 – 1941, April 10. That number would normally be quoted as 41 04 10. If you say four hundred and ten four hundred and ten, there will be confusion.
Just another Peter said,
November 5, 2012 @ 12:47 am
I must admit it's interesting reading all this info about how phone numbers are/were assigned in US. I'll give some info about phone numbers in Australia:
Firstly, our area codes all start with 0. 1 as a first digit is for special numbers (national numbers, premium-rate numbers, etc). Our emergency number is 000 (or 112 from a mobile phone).
When I was growing up, capital cities were typically 7-digit phone numbers with a 2-digit area code (and the first three digits typically indicated the exchange, but not necessarily). Country towns were typically 6-digit phone numbers with a 3-digit area code. Sometime around 15 years ago (can't remember exactly when) they decided to change the system to be consistently 8-digit phone numbers with 2-digit area codes. The new numbers were typically generated from the old area code and phone number – my parents went from (09) 343 xxxx to (08) 9343 xxxx (the area codes were shuffled around a bit at the same time).
Mobile phones were, as far as I know, always on a separate system. Analogue mobiles were 015 xxx xxx or 018 xxx xxx. Digital mobile phones are 04xx xxx xxx. The first four digits of a digital mobile phone number indicate the telco the number was first purchased from, but with mobile number portability they might no longer be using that telco.
oldfeminist said,
November 5, 2012 @ 11:10 am
"Why insist on a length limit of one letter for profession information if you are then going to have to devote an eighth of a page of boilerplate to explaining the system of one-letter codes?"
Because the code letter lives a million times, on a computer, and the boilerplate lives once, maybe not even on a computer now, to be printed over and over again to a printed page with no changes. Duplication of information is not new information.
Not to mention that the time it takes YOU to fill out the form means nothing to the company that asks you to fill it out. Only the time THEY spend on the form counts.
But if that doesn't satisfy you, consider the bottom line: hash mapping.
If 26 or fewer profession types is enough, then why use another letter? If they used multiple letters, that would just mean greater likelihood that you will select an invalid profession type. In this case you want a heavily populated answer space to avoid invalid hits. You might type M when you meant N, but if only I and Q are not used, chances are you will type a correct code.
Adding one more letter to the code now opens up 676 possibilities. We probably don't care that much about your profession. Adding a number gives us 260. Again, too many professions to care about.
If we just tell you to write your profession on the line, then it will take OUR people time to interpret YOUR answer. When people complain about government waste, think of the forms they have to interpret, some of which are filled out by jokers.
Which is the opposite of the next situation:
"Some very long numbers, mostly when dealing with computers, are deliberately long so that you can generate a new unique number by picking one at random – that is, it's so unlikely that a valid number could be picked at random that it's safe to just randomly generate a new value and use it."
In this case a severely unpopulated answer space is a positive good because you don't want to share your ID (hash) with anyone else.
Another instance is credit card numbers. They are created out of multiple pieces of information. The type is coded in the first few digits, your account number comes next, and then there is a check digit at the end, which is calculated (again) from the other numbers. That is the first pass; if you type your CC number incorrectly you will probably fail the check.
However, in order to use this card, you have to have both the expiration date and the security code. The security code is generated from the number and the expiry with a secret key. The chance of guessing the security code is very very small, even if you create an otherwise numerically valid CC number. The ratio of right to wrong CC numbers is very low. As it should be.
Phone numbering systems were a lively source of discussion in the original 2600 days. It all had meaning. Area code, area. Exchange, neighborhood (or might also correlate with business versus home in an area). Even the number at the end could tell you, if you had some inside information or were willing to call a bunch of numbers at random asking for Jenny in Sales to map it out, whether it was part of a Centrex or standalone.
Dennis Paul Himes said,
November 5, 2012 @ 11:37 am
@Reinhold {Rey} Aman:
I find the exact opposite. At least in Connecticut, zip codes are spoken (2 digit) + (3 digit). After all, the first two digits tell which state you're in, and the last three digits are (as far as a typical citizen is concerned) random.
Grover Jones said,
November 5, 2012 @ 4:51 pm
@Dennis Paul Himes,
As a lifelong Midwesterner, I agree completely. In fact, you took the words right out of my mouth (or fingers).
JohnM said,
November 6, 2012 @ 5:27 am
@Just another Peter
My Australian number was changed in 1994, which I am quite certain about because it happened just before I moved away in January 1995.
In our case (outer Sydney suburbs), a 9 was just added to our 7 digit number, so it went from (02) 6xx-xxxx to (02) 96xx-xxxx
Ken Meltsner said,
November 7, 2012 @ 2:43 pm
I believe zip codes were originally set up to incorporate an older post code system — (city name) + 2 digit code. Plowing through old books and letters, I've often seen addresses with "Cambridge 39" or "Chicago 05." The first one becomes 02139, the second 60605.
I could see where this would encourage the pronunciation of zip codes as 3 + 2 digits; if you didn't live near a big city, you might go the other way, I suppose.
[Vaguely related side note: 12345 is the zip code for GE's main plant in Schenectady.]
Ken Meltsner said,
November 7, 2012 @ 2:53 pm
@J W Brewer:
MIT's Dormline, long gone, used a 1920s vintage rotary telephone switch, and numbers were assigned, in sequence, to each dorm and room. My dorm, for example, had 6 sections with the same room numbers in each, and no more than 15 rooms on each section's floor, so you had to add 15 * (section #) to your room number to get the last three digits of the phone number.
Andrew Rodland said,
November 8, 2012 @ 12:22 am
The details about a the structure of a 10-digit number in North America are actually quite interesting: one can be expressed as "NPA-NXX-XXXX", where "NPA" is the Numbering Plan Area (Area Code), NXX is the "exchange", and XXXX is the "line number". The allowable NPAs are [2-9][0-9][0-9] (formerly [2-9][01][0-9]); the allowable NXXes are [2-9][0-9][0-9], and the XXXX is [0-9]{4}. All of this is syntax.
Additional wrinkles: NPAs and NXXes ending in "11" are both disallowed; instead [2-9]11 are special three-digit telephone numbers (most famously 311 and 911). NPAs where the second and third digits are the same (other than "11") are either not assigned or somehow special, including toll-free numbers (800, 888, 877, etc.), premium-rate numbers (900), follow-me numbers (500), and others.
So what does this show? First, that the syntax is richer than most people realize; second, that although much of the semantics of ordinary numbers is vanishing, there are still some interesting things to be found in the less-ordinary numbers.
Joe said,
November 8, 2012 @ 5:10 pm
There's an obvious solution to Geoff's problem of "keeping track of pointless random digit strings and being unable to relate them to each other" which was, effectively, solved by DNS to manage the TCP\IP addressing scheme adopted by the Internet: create another layer of naming that humans can understand and have computers keep track of the associations between the names and the "pointless random" digits they refer to. This method allows me to remember the more meaningful "languagelog.ldc.upenn.edu" much easier than 128.91.252.31.
This was the role filled by phone books in the past and and is addressed by contact lists in smart phones today. With these tools, I doubt if Geoff is personally "keeping track" of any phone numbers at all, but, rather, referring to a contact on his cell phone instead.
mollymooly said,
November 9, 2012 @ 10:11 am
The fact that cellphones use the same prefixes as landline area codes is another US peculiarity. In Europe, your mobile phone number doesn't tell you where you lived in 2005; it tells you which mobile phone company you used in 1998.
@Just another Peter:
The initial 0 isn't really part of the area code; it's to indicate that the following digits are an area code and not a local number. Which is why if you direct dial home from abroad you're told to "leave out the initial 0".
Alex said,
November 12, 2012 @ 10:25 am
Is "There are techniques for abbreviating such grammars … but I haven't bothered to use them" ironic, in an essay decrying inefficiency of expression?
David Morris said,
November 13, 2012 @ 1:08 am
"Like the banking system I use that allows a 38-character text description (way too short) to accompany a transfer of money to someone else's account, but the system forbids commas, colons, semicolons, question marks, exclamation points, parentheses, plus signs, equals signs, quotation marks, and numerous other ASCII characters."
If 38 chars is too short, then that's just a bad usability decision by whoever made the database. It would be easy for them to make the field bigger, if they so chose, but it's probably not worth expending valuable engineer time fixing such an incredibly minor usability issue.
As for restricting certain ASCII characters, it's probably a security measure–another layer of protection that prevents the possibility of the program accidentally interpreting as code user-inputted text that ought to have been escaped. For most websites going so far as to restrict ASCII input would be overcareful so you don't see it too often, but I think for the heightened security of a bank it makes sense.