Hearing interactions
« previous post | next post »
Listen to this 3-second audio clip, and think about what you hear:
What I hear:
| Speaker1: | On the last day that I was there like it was so awful be | cause |
| Speaker2: | Boy, |
(FWIW, I also hear Speaker2 sniffing before she chimes in.)
I'm less interested, right now, in the fact that I can understand the words spoken by both participants, and more interested in the fact that I can tell that there are indeed two speakers, and that the second speaker chimes in briefly at the end, for one syllable about a quarter of a second long. And I'm wondering whether this points to a missing piece in the recent history of psycholinguistics.
Over the past couple of weeks, I've spent quite a few hours helping to prepare material for the first DIHARD Speech Diarization Challenge, to be discussed in a special session at InterSpeech 2018. "Diarization" is the task of figuring out who spoke when in audio (or multimedia) recordings, and my preparation and checking of diarization data has included thousands of repetitions of the type of speaker-change detection represented by listening to that short clip.
As last summer's SALT workshop emphasized, automated diarization remains a difficult problem, so far unsolved in the general case. (See "Too cool to care", 8/12/2017, for some illustrative examples.) But there are some diarization-like problems that computers are better at than people are. For example, if a recording is accurately divided into single-speaker segments, and if there is a complete or nearly-complete inventory of speakers with a moderate amount training material for each of them, then accurate assignment of segments to speakers has been possible for some time. See e.g. Jiahong Yuan and Mark Liberman, "Speaker Identification on the SCOTUS Corpus", Acoustics 2008 — the background of that project is sketched in "NPR: oyez.org finishes Supreme Court oral arguments project", 4/13/2013.
A task of this type is generally hard for us humans to do, unless we're familiar with most if not all of the speakers — the reason that Jerry Goldman recruited Jiahong Yuan and me to work on SCOTUS speaker ID, almost 20 years ago, was that his student transcribers were having a very hard time learning to assign turns to speakers accurately in the oral-argument recordings.
But if the number of speakers is unknown, there is no prior training material, and speech segments involving overlapping or contiguous speaker changes are not divided into single-speaker segments, the automated diarization problem becomes much harder.
And when the speaker inventory is unknown, automated systems are similarly not very good (for example) even at deciding whether two arbitrary single-speaker segments are from the same speaker or different speakers. In an experiment that participants from JHU ran at last summer's workshop, comparing all pairs of speaker segments longer than three seconds taken from meetings in the AMI development corpus, the Equal Error Rate for a state-of-the-art speaker ID system in answering the question "same or different speaker" was between 17.5% to 30.2%, depending on choice of microphones and training techniques. And they limited the segment sizes to three seconds and up, because they knew that the error rate on shorter segments would be significantly higher, approaching chance levels — although such shorter segments are often a majority in interactive conversation. (In Supreme Court oral arguments, 74% of all speaker segments, defined as single-speaker stretches of speech separated by silent pauses longer than 200 milliseconds, are less than three seconds long; in ADOS (clinical) interviews, 94% of such speaker segments are less than 3 seconds long.)
But my experience with the DIHARD data prep underlined for me that there's one aspect of the general problem that we humans are good at: speaker change detection. Listening to single-channel recordings of multiple-speaker interactions, it's almost always obvious within a syllable or two when a change of speakers occurs, even for short clips taken out of context.
To illustrate the point, here are a few short clips from various sources taken out of context. In each case, there's a change of speakers within one or two syllables of the start or end of the selection — and I think you'll find that the change points are perceptually obvious.
| (1) | |
| (2) | |
| (3) | |
| (4) |
There's a substantial speech-technology literature on "speaker change detection". As far as I can tell, there's no standard test corpus and no standard evaluation metric, so it's hard to compare results across publications, but overall performance seems to be (unsurprisingly) rather poor.
Thus in J. Ajmera et al., "Robust speaker change detection", IEEE Signal Processing Letters 2004, the authors' contribution (the "Proposed" method) has a recall rate 0f 65%, with precision of 68%:
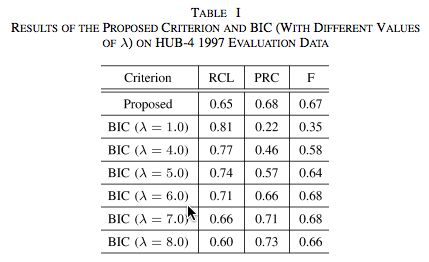
In other words, it misses 35% of the speaker change points, and 32% of its proposed speaker change points are false.
In a more recent paper using the currently fashionable type of algorithm (Vishwa Gupta, "Speaker change point detection using deep neural nets", IEEE ICASSP 2015), performance remains distinctly underwhelming.
They trained and tested their system on both English and French datasets. In English, depending on how they set the "confidence threshold", performance ranged between missing 11% of speaker changes with nearly 30 false alarms per minute (one every two seconds), and missing 43% of speaker changes with nearly 10 false alarms per minute (one every six seconds):
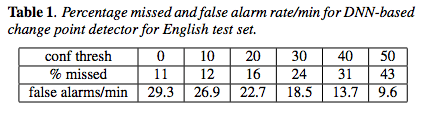
The performance in French is significantly worse — according to the authors, "The French dev set is more difficult than the English test set as it contains both broadcast news and talk shows", which have shorter turns and more overlapping speech:
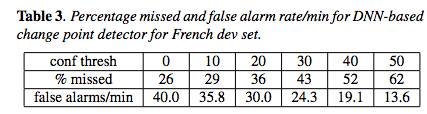
Practical experience tells us that speaker-change detection is a very easy task for human annotators — they rarely make a mistake, if they're paying attention. And as the samples above suggest, we need only a single syllable on one side of the change to hear the change. Based on a bit of informal exploration, I believe that this remains a fairly easy task even for conversation in a language unknown to the hearer. But I haven't been able to find any research that quantifies human performance on speaker-change detection, whether in known or unknown languages.
There's a bit of literature on cortical localization of some of the perceptual mechanisms involved — e.g. J.D. Warren et al., "Human brain mechanisms for the early analysis of voices", NeuroImage 2006, or Mesgarani and Chang, "Selective cortical representation of attended speaker in multi-talker speech perception", Nature 2012. But I could find nothing to validate (or refute) my belief that we're very good at speaker-change detection in languages we know, and pretty good at the same task even in languages we don't understand at all. If you know of any relevant research, please tell us in the comments.
So it might be useful to define some standard test datasets, and a quantitative evaluation metric, so that we can determine what human performance really is and how well our computer algorithms do in comparison. If I'm right that humans are very good at tasks of this type, that establishes a lower bound on how well computers ought to be able to do. And if I'm right that current algorithms are pretty terrible at tasks of this type, we've got an interesting challenge ahead of us.
Update — As anecdata in support of my belief that human speaker change detection doesn't necessarily depend on knowing the language in question, here are two examples from languages that I don't know. In each case I found an interview on YouTube, started listening in the middle, and took the first case where a change of speakers takes place without a silent pause.
Adrian Morgan said,
February 28, 2018 @ 7:08 am
How can you possibly hear all those words in the initial clip? What I hear: "Oh, I [see/say] there is there (thud) like (noise) so often (new speaker) but"
I'll give you that it's actually awful rather than often (I was listening in Australian), but "on the last day", etc? There isn't even a hint of all those consonants, and I saved the file and played it at half speed to be extra sure.
Philip Taylor said,
February 28, 2018 @ 7:15 am
After many many repetitions (initially the opening words were meaningless), I now think I hear "On the last day that I was there, like, it was so awful, be…" / "Boy …". but I have almost zero exposure to accents similar to those that appear in the recording.
mollymooly said,
February 28, 2018 @ 7:25 am
I matched Mark Liberman's text on the second listen; I think the first speaker has a cold, and since the other sniffs, it was probably winter.
TIC said,
February 28, 2018 @ 7:37 am
Very interesting stuff… As a complete layman in this area, it's rather surprising to me that, if I'm understanding and summarizing accurately, even the most advanced, experimental, automated transcription systems have so much difficulty distinguishing between individual voices and thereby detecting speaker changes…
FWIW, I'll add that this article didn't go in the direction that, after the initial sound clip and transcription, I thought sure it was going… I'm on occasion amazed that, in my experience at least, we humans have a quite reliable ability to identify the individual, unseen source of an extremely quick *nonverbal* interjection, such as that sniffle, or a sneeze, or a cough, or a hiccup, etc….
[(myl) Those abilities are certainly amazing. But my recent focus has been on diarization and speaker change detection, and I continue to be amazed at how hard those tasks seem to be for speech-technology systems that have gotten to the point of being pretty good at recognizing sequences of words.]
Ralph Hickok said,
February 28, 2018 @ 8:36 am
I had no trouble understanding what was said at the first hearing…but I often pride myself on my skill as an eavesdropper.
TIC said,
February 28, 2018 @ 8:53 am
myl: I've been following with interest all of your recent posts on the challenges of diarization… And this particular dilemma is fascinating… To this layman, at least, it would seem that the task of distinguishing between speakers, even those with similar-sounding voices, would be a relative (and literal?) "no-brainer" as compared to the task of recognizing, in all but the plainest and clearest of utterances, sequences of words…
[(myl) Agreed. Maybe it's just because there's been less research on diarization and speaker-change detection. Maybe it's because there's less a priori "language model" type of constraint in those areas. And maybe it's one of those cases where what's easy for people and what's easy for computers are very different at many levels, so that even once automatic speech recognition more or less works, things like speaker-change detection remain hard.]
Scott P. said,
February 28, 2018 @ 10:41 am
But there are some diarization-like problems that computers are better at than people are. For example, if a recording is accurately divided into single-speaker segments, and if there is a complete or nearly-complete inventory of speakers with a moderate amount training material for each of them, then accurate assignment of segments to speakers has been possible for some time.
Okay, so computers are better at this than humans.
A task of this type is generally hard for us humans to do, unless we're familiar with most if not all of the speakers
Wait — but in the example above (that you claim shows computers are better than humans), you specify that the computer has access to a list of all speakers, and has trained to become familiar with their voices.
This isn't an apples to apples comparison! You'd have to compare the computer to a human who had spent many hours listening to the voices of the various speakers.
I find this to be all too common in claims of computer superiority: Computer + massive amount of training is 'superior' to human with little or no training.
The question should be can a computer with X amount of experience or knowledge outperform a human with the same amount of experience or knowledge.
[(myl) I don't think we disagree about this. But it's unreasonable to try to train human listeners to identify hundreds of thousands of different speakers — say by making same/different judgments for a large-enough test sample against a large database of adequately enrolled reference speakers — whereas this is the sort of thing that computers can do fairly well.
And even learning to distinguish the seven different male speakers in the 2001 U.S. Supreme Court was something that student employees were empirically not able to learn to do accurately enough in a short enough time for Jerry Goldman to find it practical to use that method, although he wanted to do so.]
cervantes said,
February 28, 2018 @ 11:04 am
I work extensively with human-made transcripts of dialogic and trialogic encounters and I can affirm, absolutely, this is no problem at all for humans whatsoever. It's so easy and obvious we never even think about it, although getting the words right is often hard or impossible. It is surprising to me that this is difficult for machines, actually. Surely the differences in human voices that are obvious to humans must represent features that can be parsed — intonation, timbre, vowel shapes, whatever. Perhaps if two speakers happen to have similar voices it would be difficult, but what if you have a baritone and a soprano? Surely the computer can tell them apart.
TIC said,
February 28, 2018 @ 11:29 am
The curious fact that humans can distinguish voices SO quickly and easily (whereas computers, at least currently, have so much difficulty) is what I was, admittedly inelegantly, trying to get at with my initial comment about how we meatbags can do it (with, I suspect, tremendous accuracy) even with just an instantaneous sniffle or hiccup… A fascinating quandary… Of course, Mark's comment-thread note about the relative scarcity to date of research in this area is surely a big part of the 'splanation for this…
Y said,
February 28, 2018 @ 12:25 pm
Is there any psycholinguistic evidence for any one factor which, by modifying the recording, can severely degrade the human ability to distinguish speakers?
For a stereo recording, with the microphones situated typically, does the problem of speaker identification become trivial (using amplitude differences and perhaps phase differences)?
Philip Taylor said,
February 28, 2018 @ 12:32 pm
Scott P wrote : "You'd have to compare the computer to a human who had spent many hours listening to the voices of the various speakers". Why "many hours" ? If we are really to compare apples to apples (rather than, say, oranges), then both computer and human have to be trained for the same period of time. N'est-ce pas ?
Y said,
February 28, 2018 @ 12:43 pm
The toughest non-accidental challenge to speaker identification I've ever heard was at this talk at LSA 2012:
To me it sounded as if each speaker would start talking while the previous ones are still at it, in the manner of the beginning of a musical round. I was very quickly entirely lost (of course, I don't know the language, and this was a recording played at a presentation).
Eluchil404 said,
February 28, 2018 @ 1:13 pm
The first time I listened I understood few, if any words. But after 3 iterations I am confident of the following transcription:
Speaker 1: The last day that I was there was, like, so awful.
Speaker 2 (interjecting): Boy!
There is a fair amount of background noise as well.
cervantes said,
February 28, 2018 @ 1:18 pm
If two people are talking at once, we can usually isolate either of the voices and understand what is said. Crosstalk can be unintelligible, but the "cocktail party" is one of our most impressive abilities. I expect it depends more on picking out the words than the voices, though, but maybe a little bit of both.
Robot Therapist said,
February 28, 2018 @ 1:22 pm
Hmm. I didn't detect a speaker change at all in the very last example.
[(myl) If you mean the one labeling "(4)", perhaps you were focused on the end of the clip? The speaker change takes place after the first syllable. If you mean the second of the two non-English examples, the clip had an unfortunate length that seems to have caused not all of it to play in some browsers.]
The first one I found easy, except that I had to listen for a second time before I heard the "cause" at the end.
Rosie Redfield said,
February 28, 2018 @ 1:56 pm
In the set of four clips, I found that the overlaps were what made it obvious that a new speaker was contributing. In each example, although the original speaker could in principle have made the new speaker's sound, they couldn't have done it while they were saying their own word.
Gregory Kusnick said,
February 28, 2018 @ 2:27 pm
Philip Taylor: Perhaps what you mean is that computer and human should be trained on the same amount of data. How much time they spend in training seems less relevant, since it depends on how fast they process the training data, and presumably the computer wins that contest.
cs said,
February 28, 2018 @ 3:05 pm
Agree with Rosie Redfield: a human listener would be more likely to make a mistake where there is a pause between speakers, compared to overlapping speech. Are any of these computer speaker-change methods based on detecting overlap?
Philip Taylor said,
February 28, 2018 @ 3:46 pm
Gregory: well, no, I really did mean "for the same period of time", since the discussion was about whether computers are "better" than humans at a certain task. One of the criteria for "better" is "how quickly", so if a computer can achieve the same results as a human but in less time, then the computer is "better", is it not ?
Sean Richardson said,
February 28, 2018 @ 3:47 pm
There is an aspect of the pragmatics of human learning to recognize speaker changes that is unlikely to be replicated in machine training: failure to recognize an imperative interrupting utterance and immediately attend to its meaning can easily be lethal. Presumably parents and caregivers have been warning about serious hazards long before there were busy roads. In any case all of us reading this made it through that stage of life.
AntC said,
February 28, 2018 @ 4:37 pm
32% of its proposed speaker change points are false.
Does all the data (like Mark's clips here) exhibit overlaps of new speaker interjecting while old speaker is still talking? If OTOH there's a gap between speakers, the detector has to recognise some change in timbre or pitch, etc — and that might happen anyway as a continuing speaker starts a new sentence/topic. Legal arguments perhaps include a lot of that? I imagine that's a quite different challenge vs overlapping changes.
[(myl) No — in (for example) the broadcast news datasets, there is a significant silent gap at speaker changes, more often than not.]
As others have said, for the overlapping case I would (naively) expect it's easy to detect segments where there's two speakers rather than one. So get the voice characteristics of the single voice just before the overlap, and the other single voice just after, and work from each side to the middle.
[(myl) Actually, until recently the automatic detection of overlapped speech was especially poor. Work by Sriram Ganapathy and others for last summer's workshop made some improvements (see "Leveraging LSTM models for overlap detection in multi-party meetings", IEEE ICASSP 2018), but there's still a long way to go.]
Michael Watts said,
February 28, 2018 @ 6:02 pm
In the last foreign language example, I can tell that the speaker at the beginning of the clip and the speaker at the end of the clip aren't the same. But I have trouble telling where #2 begins or where #1 ends.
[(myl) Try downloading the clip, loading it into a digital audio editor like Audacity, and adjusting the selection gradually from (say) half way through the clip onwards. Up to a certain point you won't hear the second speaker, and then you will.
When we know the language, we can more easily retain the time-sequence pattern in memory; but in a case like this, we sometimes can detect the change without being able to associate it with a point in a remembered sequence of words or sounds.
Rubrick said,
February 28, 2018 @ 8:21 pm
I'm glad you included the other-language examples at the end. Until then, I was mulling the hypothesis that humans' better understanding of what constituted a sensible sequence of words for one speaker to say might be at the heart of our advantage.
I still suspect that's part of it. But now I'm leaning toward the importance of prosody — that the speaker transition has a different rhythm than would occur with a single speaker, even if that speaker is interrupting themselves or changing course mid-sentence. Even though I don't speak those last two languages, I think I still have some intuition as to how they "sound". And notably, I certainly found those two examples (especially the first) less trivial than the Engllish ones.
To test that idea, it would be interesting to see how difficult it was to diarize a passage in which rehearsed actors smoothly switched between speakers in the middle of a single spoken passage, leaving (ideally) only the quality of each speaker's voice as a cue.
And yet, running that experiment in my mind… I'll bet I'd still be pretty good at that, unless the actors had very similar voices. There's some quality of voices that makes them distinct, and it is indeed very hard to pinpoint what that is (and thus why computers are inferior at it).
D.O. said,
February 28, 2018 @ 10:05 pm
I would suggest (with 0 real data, just my own introspection) that detecting the speaker change is much easier task than figuring out who the speaker is. That is, two persons with overlapping speech or speaking in turns side-by-side is easy, but remembering a set of voices and then assigning a single-person speech fragment to someone in that set, is hard.
[(myl) Exactly the point. (Assuming that "easy" and "hard" imply "for human listeners"…)]
Andrew Usher said,
February 28, 2018 @ 11:31 pm
I may be late, but I'd like to reply to the first few comments. The people that had trouble with the first clip were non-American by their own admission. As an American used to hearing American speech, I had no trouble even without giving particular attention to hear the first time '… last day that I was there … it was so awful …' (my mind simply passed over the filler 'like'). All the sound are there, though of course not in isolated form. I can attest that Americans can certainly have this kind of problem with British speech if we're not expecting it, and it's not surprising it might be true the other way, also.
In general I'd say American speech is less likely than British-type to drop consonants or vowels and more likely simply to increase speed and coarticulation. I couldn't say either strategy is absolutely better; but I can say that some connected-speech reduction processes are unavoidable in any language, anywhere; and oral fluency requires the ability to deal with he type used in that community.
As to the main point of the article, well it's not really surprising that humans are good at what humans are good at (following real conversations) and computers are better at the sort of thing computers are better at (identifying a speaker from a large database). There isn't – and after a half-century one can be pretty sure there won't be – any magic breakthrough of AI; computers will simply be refined to use better and better algorithms to do what humans do easily, gradually and with effort and a lot of computational power. Frankly it should be admirable that computers are as good as they now are in dealing with speech, rather than frustrating (in concept, not a specific instance) that they're not perfect or human-like.
k_over_hbarc at yahoo.com
[(myl) One additional point — the main thing that pushed me to write the article — is that there has apparently never been any investigation of how good we humans actually are at detecting speaker change, what cues we use, etc.; and despite a considerable engineering literature on automatic speaker-change detection, there is no standard evaluation metric and no standard evaluation data sets.]
GH said,
March 1, 2018 @ 11:35 am
Listening to these clips, I was struck by the extent by which (it seemed to me) my ability to tell the speakers apart was driven by:
-Differences in the point of origin of the speech (closer or further from the mic), as indicated by differences in the acoustics
-For overlapping speech, understanding that the different sounds could not be simultaneously articulated by a single person
-My high-level model of what words were being said, and hence ability to separate out overlapping speech
In terms of thought-experiments, I would find it interesting to use audio editing to create clips where the same speaker is talking on top of themselves (recorded from different positions), and see if people are able to spot that it is the same voice.
In recorded music (where you often do get the same voice layered on top of itself for harmonies and other overlapping effects), I have a much harder time telling voices apart. I heard "I Know Him So Well" from Chess on the radio (FM, probably mono) the other day, and then wanted to listen to it again on YouTube. It was only when I saw the music video that I realized it was a duet between two different singers. Of course, this could be because of how voice is used in song vs. regular speech, but I wouldn't discount the lack or unreliability of these other cues as a factor.
BZ said,
March 1, 2018 @ 4:28 pm
I am an American (well an immigrant of 27 years), and at first I only heard "… that I was there … like so OF… / (new speaker) boy". Now that I know what they are saying from transcription I can't trust myself to say whether repeated hearings help.
Also, I find a hard time detecting the change in speakers in your last English example and both foreign language ones.
Mike Maxwell said,
March 3, 2018 @ 11:27 pm
Late to the party… Y mentioned a conversational style among indigenous people of Mexico which intentionally used overlap. The traditional greeting ceremony among Achuar (and Shuar) men also did this; both languages are spoken in Ecuador, and Achuar is also spoken in Peru. I believe there's a recording at https://ailla.utexas.org/islandora/object/ailla%3A124529, but my AILLA account must be tied to an email I no longer have, and my new account is pending…
I've also heard this in Ecuadorian Andean Spanish, where the two men (don't know if women do this) will ask overlapping questions about how the other is doing, how their family is, etc., without (IIRC) ever actually answering each other's questions.