
Corpus-based Linguistic Research: From Phonetics to Pragmatics
RELATIONS BETWEEN THEORIES AND DATA
1. GOALS
Hypothesis testing
Often there's a hypothesis that we want to (dis)prove -- some examples:
Women are more talkative than men: "Gabby guys: The effect size", 9/23/2006.
Young people use discourse-particle "like" more than old people: "'Like' youth and sex", 6/28/2011.
The idiom "could care less" is marked with a sarcastic intonation: "Speaking sarcastically", 7/16/2004.
Barack Obama uses first-person singular pronouns unusually often: "A meme in hibernation", 3/31/2012.
Exploratory Data Analysis
But sometimes we don't really have a crisply-defined hypothesis, we're just exploring a phenomenon or a new kind of data:
What's going on with "um" and "uh"? "Young men talk like old women", 11/6/2005.
"Mitt Romney's rapid phrase-onset repetition", 10/28/2012
"Evaluative words for wines", 4/7/2012
"The quality of quantity", 4/24/2012
"Long is good, good is bad, nice is worse, and ! is questionable", 6/12/2013
"Significant (?) relationships everywhere", 6/14/2013
Most often, we start out with a hypothesis, and the process of trying to test it leads us to new ideas, perhaps about totally different questions.
Thus the work described in Mark Liberman & Janet Pierrehumbert, "Intonational Invariance under Changes in Pitch range and Length" (1984) began as an attempt to test two previously-published hypotheses about English intonation: (1) that pitch movements tended to correspond to musical intervals such as thirds and fifths; (2) that falling "nuclear tones" in English come to two distinct flavors, "high fall" and "low fall". We were skeptical of both of these ideas, so we gathered data to test them by getting people to perform various contour types in a variety of pitch ranges. The results certainly didn't support either of the two cited hypotheses, but instead showed some other interesting patterns; and in the end we wound up writing about these other patterns, and didn't even mention the two hypotheses that got us started.
Prediction / Classification / Diagnosis
Athanasios Tsanas et al., "Nonlinear speech analysis algorithms mapped to a standard metric achieve clinically useful quantification of average Parkinson's disease symptom severity", Journal of the Royal Society, 2010:
The standard reference clinical score quantifying average Parkinson's disease (PD) symptom severity is the Unified Parkinson's Disease Rating Scale (UPDRS). At present, UPDRS is determined by the subjective clinical evaluation of the patient's ability to adequately cope with a range of tasks. In this study, we extend recent findings that UPDRS can be objectively assessed to clinically useful accuracy using simple, self-administered speech tests, without requiring the patient's physical presence in the clinic. We apply a wide range of known speech signal processing algorithms to a large database (approx. 6000 recordings from 42 PD patients, recruited to a six-month, multi-centre trial) and propose a number of novel, nonlinear signal processing algorithms which reveal pathological characteristics in PD more accurately than existing approaches. Robust feature selection algorithms select the optimal subset of these algorithms, which is fed into non-parametric regression and classification algorithms, mapping the signal processing algorithm outputs to UPDRS. We demonstrate rapid, accurate replication of the UPDRS assessment with clinically useful accuracy (about 2 UPDRS points difference from the clinicians' estimates, p < 0.001).
Note that the standard UPDRS test "comprises a total of 44 sections where each section spans the numerical range 0–4 (0 denotes healthy and 4 denotes severe symptoms), and the final UPDRS is the summation of all sections (numerical range 0–176, with 0 representing perfectly healthy individual and 176 total disability)".
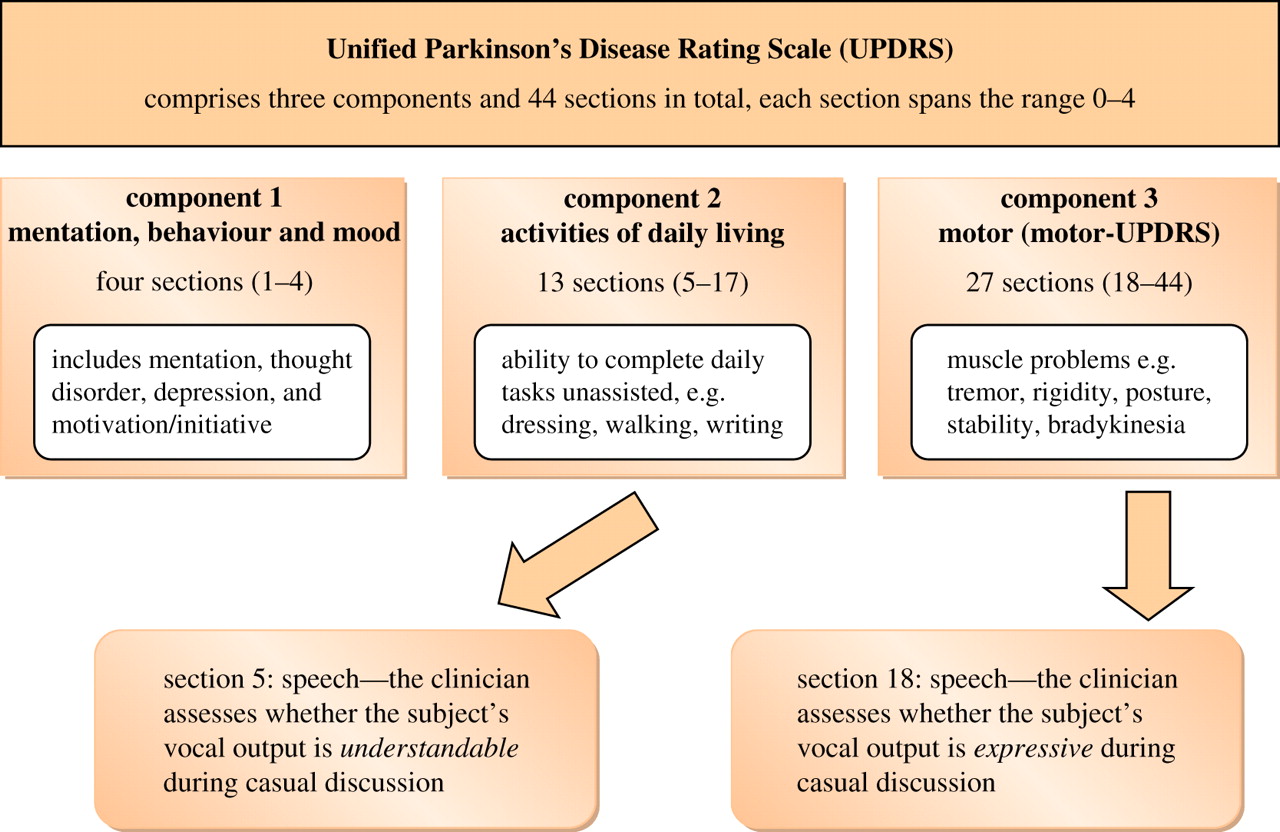
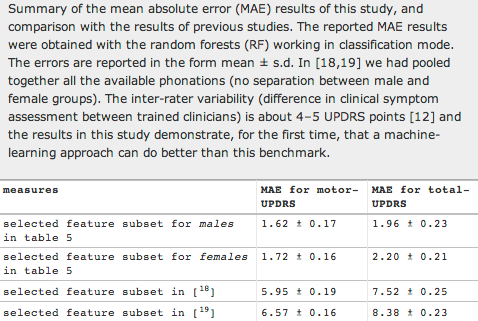
Based only on automated analysis of phonation features, Tsanas et al. were able to match expert clinicians' overall UPDRS ratings better than clinicians agree with one another:
Molly Ireland et al., "Language Style Matching Predicts Relationship Initiation and Stability", Psychological Science 2011.
Previous relationship research has largely ignored the importance of similarity in how people talk with one another. Using natural language samples, we investigated whether similarity in dyads' use of function words, called language style matching (LSM), predicts outcomes for romantic relationships. In Study 1, greater LSM in transcripts of 40 speed dates predicted increased likelihood of mutual romantic interest (odds ratio = 3.05). Overall, 33.3% of pairs with LSM above the median mutually desired future contact, compared with 9.1% of pairs with LSM at or below the median. In Study 2, LSM in 86 couples' instant messages positively predicted relationship stability at a 3-month follow-up (odds ratio = 1.95). Specifically, 76.7% of couples with LSM greater than the median were still dating at the follow-up, compared with 53.5% of couples with LSM at or below the median. LSM appears to reflect implicit interpersonal processes central to romantic relationships.
Dan Jurafsky et al., "Extracting Social Meaning: Identifying Interactional Style in Spoken Conversation", ACL/HLT 2009.
2. APPROACHES
Observations vs. Intuitions
Intuitions about "what people say" or even about "what I say" are quick and convenient but often unreliable:
"Why are negations so easy to fail to miss?", 2/26/2004
"This is not to say that I don't think that it isn't illogical", 11/3/2012
"Going it together", 11/15/2005
"Singular y'all: a 'devious Yankee rumor'?", 12/31/2009
"Grown and growner", 9/1/2012
And for a more serious discussion of the impact of dubious judgments on linguistic theorizing, see Tom Wasow and Jennifer Arnold, "Intuitions in linguistic argumentation", Lingua 2005.
Anecdotes vs. Experiments
Informed judgment is valuable, and stories are how we make sense of the world. But informed judgment is not always right, and telling anecdotes are subject to stereotypes, selection bias, confirmation bias, and other problematic influences. "The plural of anecdote is not data".
"Your brain on ____?", 11/23/2010
"The social psychology of linguistic naming and shaming", 2/27/2007
"'At the end of the day' not management-speak", 9/26/2009
"David 'Semi True' Brooks", 3/20/2013
"David Brooks, Social Psychologist", 8/13/2008
"The butterfly and the elephant", 11/28/2009
"An invented statistic returns", 2/22/2013
"Factlets", 6/3/2012
"Uptalk anxiety", 9/7/2008
Laboratory Data vs. the Real World
In various papers from 1976 onwards, (various combinations of) Donna Jo Napoli, Martina Nespor, and Irene Vogel argued for a categorical distinction between e.g.
le mappe di città [v:]ecchie "the maps of old cities"
le mappe di città [v]ecchie "the old maps of cities"
This concusion was originally based on native-speaker intuitions, but intuition was later supported by a small speech-production experiment. And an important theoretical conclusion was drawn, namely that well-defined prosodic consitutents exist, arranged in a "prosodic hierarchy", and that crisp formal rules define the relationship between syntactic structures and prosodic structures, which in turn govern the application of certain external sandhi rules, of which raddoppiamento fonosintattico was a paradigm example.
This argument was very influential throughout the 1980s and 1990s.
But in fact, the basic observation was completely wrong. Italian RS works rather like English flapping and voicing -- it can apply anywhere in connected speech, and is only categorically blocked by actual pauses. For a detailed summary of the history of the "fact" and its interpretations, see e.g. Matthew Absalom et al., "A Typology of Spreading, Insertion and Deletion or What You Weren't Told About Raddoppiamento Sintattico in Italian", ALS 2002.
The view of RS as an "anywhere" rule was strongly supported by corpus-based work, e.g. in Agostiniani "'Su alcuni aspetti del rafforzamento sintattico in Toscana e sulla loro importanza per la qualificazione del fenomeno in generale", Quaderni del Dipartimento di Linguistica, Università degli studi di Firenze (1992). And in 1997, Irene Vogel admitted that "… notably in Tuscan and romanesco, raddoppiamento fonosintattico [RS] seems to apply throughout sentences without regard to their syntactic (and [derived] phonological) constituency" ("Prosodic phonology", in Maiden & Parry (eds), The Dialects of Italy).
Despite the refutations by Agostiniani and other, and the retraction by Vogel, the original story continues to be repeated uncritically to this day, including by major figures in the field.
How did this happen? We're not concerned in this class with the sociological process whereby a 35-year-old false generalization, abandoned by its originators 15 years ago, continues to be treated by some as part of the foundations of the field. Rather, I want to disucss the natural processes that led to the wrong generalization in the first place.
1. "Facultative disambiguation" -- The natural contrastive effect of considering a minimal pair in juxtaposition usually leads to an exaggeration of the natural distinctions, and sometimes to the deployment of unusual (phonetic or pragmatic) resources in order to create a clear separation.
2. "Selection bias" -- It's natural to choose cases where a phenomenon of interest seems to be especially clear, and this often leads to the selection of examples from the ends of a continuum or from widely-separated regions of a more complex space; or perhaps examples where some additional associated characteristics re-inforce the apparent differences.
3. "Confirmation bias" -- As a pattern begins to emerge, we (individually or as a field) tend to focus on evidence that confirms the pattern, and to put problematic or equivocal evidence into the background.
All of these things can easily happen with laboratory experiments as well as with intuitions: We choose experimental materials that seem to work especially well ("selection bias"); experimental subjects are likely to notice (near-) minimal pairs, and to exaggerate the contrasts that they imply ("facultative disambiguation"); and experiments often don't work for irrelevant reasons, and so it's tempting (and often correct) to put "failed" experiments aside in favor of "successful" ones.
Of course, all of these things -- especially selection bias and confirmation bias -- can also happen in corpus-based research.
For another clear (though non-linguistic) example of why experiments might not always mean what people tell you they mean, see
"How to turn Americans into Asians (or vice versa)", 8/15/2008.
Still, in determining the facts of linguistic usage, experiments are on average somewhat more reliable than intuitions, and corpus-based investigations tend to be somewhat more reliable than laboratory experiments.
3. Controversies
... in this area are mostly nontroversies, in my opinion. Details to follow.