Recently a colleague asked me for advice about how to quantify "degree of prosodic modulation", or some similar concept, for the purposes of a clinical study evaluating the hypothesis that a two clinical populations differ in their use of prosody.
The goal is to find some simple but sensible measures in terms of which such groups can be compared. Since the hypothesis has something to do with differences in the extent to which prosody is used, it seems appropriate to start with very simple measures of degree of F0 modulation, considered independent of any linguistic analysis.
In order to get a sense of what such comparisons will be like, I began with two randomly selected 20-30-second samples of female speech.. One is an NPR newsreader; the other is giving a diet counseling session (part of the CSAE corpus). The discussion below is a sort of informal exploration of the problem rather than a finished prescription.
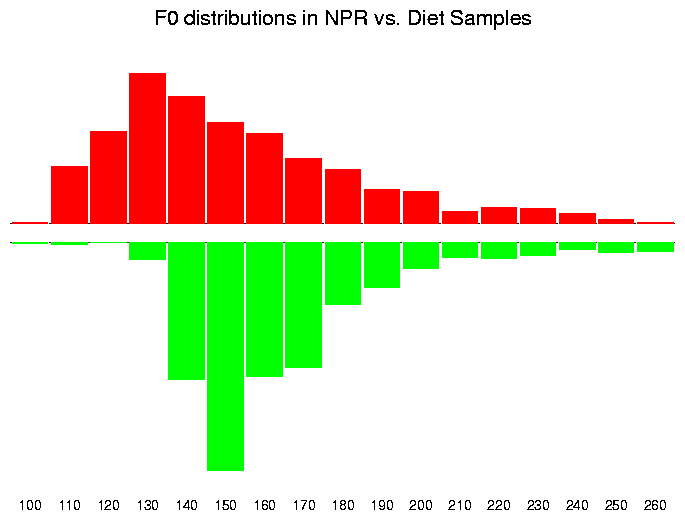
The range of pitches employed by the two women are similar. The diet counselor has a somewhat higher voice, at least in this sample: a median F0 of 162 Hz as opposed to 150 Hz., a mode of around 150 instead of around 130 Hz, a maximum of over 300 rather than around 270, etc.:
However, there are other F0 differences besides a modest upward shift in range for one sample vs. the other. These other differences probably have a larger effect on how we hear the two passages. There are many ways to approach the description and/or quantification of such differences, but let's start by listening:
The NPR sample exhibits a characteristic intellectual-newsreader style, in which an elaborate and even exaggerated system of prosodic modulation is constantly being deployed to signal the structure and information content of the message. The Diet-counselor sample, although lively enough in prosodic terms, is much less ubiquitously modulated.
There are some simple ways to quantify such differences, purely in terms of the observed distributions of F0 and F0 change, without requiring any human classification of the linguistic details of the pitch contours or their relationship to the structure of the speaker's messages.
We can start by trying to compare the shapes of the distributions more closely, abstracting away from the shift in average or median value. One way to do this is to re-plot the distributions after re-expressing each speaker's F0 values in terms of semitone intervals relative to her median F0:
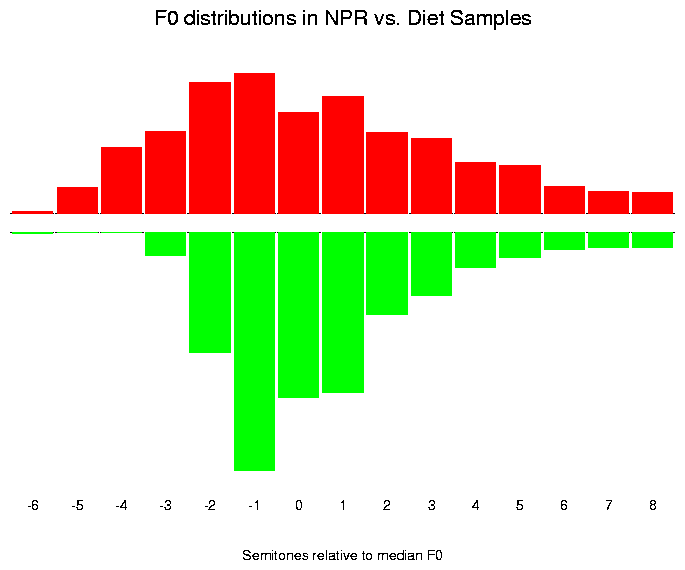
This helps us to verify visually that the F0 distributions really do have different shapes.
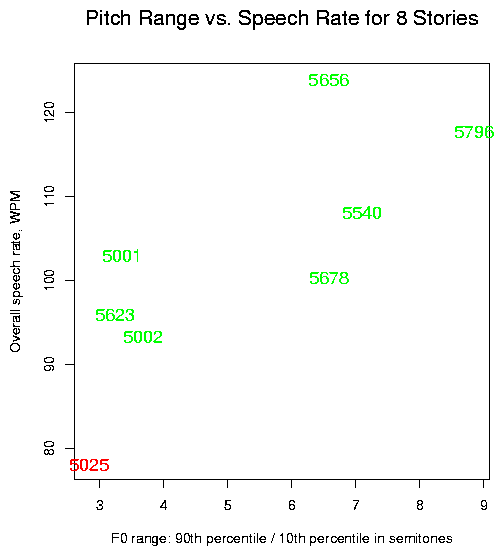
We will go on to quantify the pitch distributions differences in a more specific way, but we need first to recognize that the two samples show a quite different use of pitch range across time.
The NPR newsreader maintains a wide pitch range throughout, expanding and contracting the pitch range with topic shifts. The diet counselor start with a similarly wide range, but then rapidly declines into a lower and more monotonous performance. As a result, after about 400 (centisecond) frames of open-tract voiced speech, the two show a similar range in semitones (taking the ratio between the 90th and 10th percentile as representative), but as we look at longer and longer stretches, the ranges diverge more and more.
To make this plot, I pitch tracked the samples, then selected (by hand) the regions of voiced speech with an open vocal tract (basically vowel sounds). After extracting the F0 values for these stretches, I calculated the 90th and 10th percentiles for the first 400 F0 values, and then for the first 401, 402, 403 values etc., up to the end of the values found (there happened to be more for one speaker than for the other). I then took the ratio of these quantile estimates, and converted to semitones.
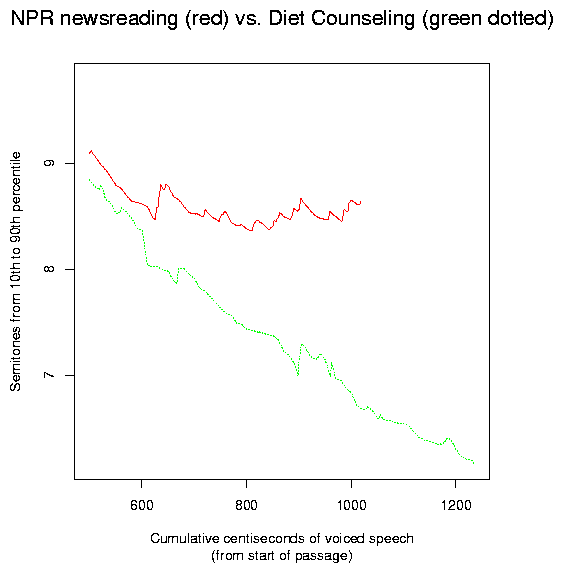
If we ignore the temporal differences and simply take the interquantile ratio for each sample as a whole, we'd see a difference of more than 2 semitones. This reflects the fact that the NPR passage is "livelier" and more consistently varied in prosodic terms, though the other passage is by no means unmodulated.
|
10% (in Hz)
|
90% (in Hz)
|
Ratio in semitones
|
|
| NPR |
123.1
|
202.7
|
8.6
|
| Diet |
144.5
|
206.3
|
6.2
|
There are lots of ways to re-calculate or re-display data like this. In addition to looking at overall quantile-based measurements, one could calculate pitch range for each breath group, or for each fixed chunk of time, and look at variation across such chunks; we can look at the rate of change of F0, or at comparisons of the F0 of neighboring syllables, etc.
Another measurement of interest is the distribution of first differences in F0 from frame to frame. This also shows that the NPR passage is "livelier" -- the mode of the distribution is the bin from -3 to -2 Hz. per centisecond (i.e. a fall at between 200 and 300 Hz per second), while the mode of the Diet passage distribution is the bin from -1 to 0 Hz per centisecond (i.e. a fall at between 0 and 100 Hz per second).
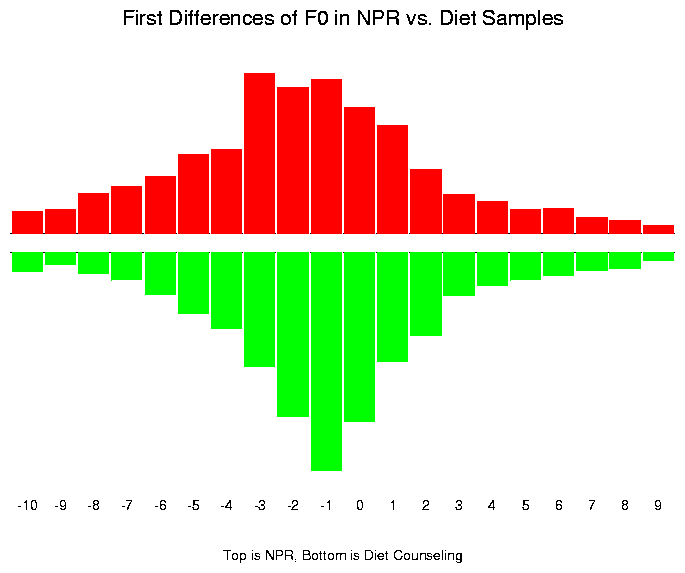
One way to quantify these distributions of first differences would be in terms of percentiles. In the table below, the rates of change are expressed as Hz/sec. The median F0 rate of change is falling for both samples, but falls almost twice as fast for the NPR sample. The NPR distribution is more "spread out" throughout, meaning that it makes systematically more use of faster rates of change, both downwards and upwards. Thus the 10th percentile (the value such that 10% of the measured rates of change are lower, and 90% are higher) is -676 Hz/sec for the NPR passage, and -513 Hz/sec for the Diet passage.
|
10%
|
20%
|
50%
|
70%
|
90%
|
|
| NPR |
-676
|
-442
|
-123
|
62
|
372
|
| Diet |
-513
|
-320
|
-72
|
44
|
319
|
I have not bothered to normalize these into relative changes (e.g. as ratios or as fractions of a semitone), since the two samples occupy similar pitch ranges. Such normalization would slightly magnify the differences seen in this case, since the NPR speaker tends to use somewhat lower pitches, so that her larger absolute rates of change would be magnified further if expressed in relative terms.
In general, however, rates of change should probably be compared in relative terms, since F0 modulations are closer to being multiplicative than additive with respect to individual difference in F0 range.
In material like this, a meaningful quantitative comparison of speech rate is difficult, because the kind (and especially sizes) of the words used are so different.
|
Words
|
Syllables
|
Time
|
WPM
|
SPM
|
|
| NPR |
57
|
107
|
21.3
|
161
|
301
|
| Diet |
98
|
123
|
30.9
|
190
|
239
|
Nothing has been said so far about how to evaluate the "significance" of differences in such distribution-based measurements. If the data to be evaluated involve sets of different speakers and conditions, as would normally be true, then the summary statistics can be processed in the normal way, say comparing a particular interquantile range for N trials in condition X with the same measure for M trials in condition Y. However, one can also calculate confidence intervals for such measures based on a single passage, for instance by using resampling techniques. In addition, there are techniques for comparing distributions as a whole that might be useful.
To validate such techniques (or the others that come easily to mind) as measuring "prosodic modulation" in some interesting sense, we would need systematic comparison across many passages from many speakers, relative to some independent expectation of degree of prosodic modulation. This might come from subjective evalutation via listening, or from consideration of the circumstances of utterance, or both. However, I think that measures like these, based on properties of the distribution of F0 and F0 rate of change, are certain to be well correlated with subjective judgments of degree of prosodic modulation, and also communicative contexts that tend to produce such differences. These simple prescriptions may not be the best measures -- there are issues to consider having to do with the size of the units over which measurements should be made, and the scaling functions that should be assumed in comparing distributions, and so on -- but they are likely to work well enough if used with care.
The most likely sources of artefact are errors in pitch tracking, or frequent cases of glottalization, diplophonia or register shift. The best way to avoid these is to look over the pitch tracts with an informed eye, and to restrict attention to well-tracked regions without glottalization or vocal fry, whose F0 is not too strongly affected by the rapid shifts and extreme F0 values that can be found in the one or two glottal pulses near some consonants.
This is a possible source of bias, since (for instance) the expressive use of register shifts will not be captured. For cases in which this is an issue, some other set of measures should also be used. One obvious need would be for a way to deal with the period-doubling that often occurs in phrase-final low regions, especially for adult female speakers. If such regions are including in the basic F0 distribution, then the discontinuities involved make it dangerous to use inter-quantile measures, because small sampling differences may then lead to sudden jumps in the lower quantile locations, which is obviously not a good thing. Some further investigation of this is needed, comparing speakers who differ markedly in their use of final period-doubling. One possibility would be to model the basic F0 distribution as the sum of two distributions, and to look at their properties separately.
The most useful feature of measures based on F0 and delta-F0 distribution (like those exemplified above) is that they don't require any description of the speech in terms of prosodic phrasing, accent types and locations, classification of junctural types, or any other analytic categories not concerned with the physical articulations involved. Such descriptions are intrinsically interesting, and will be necessary for some other kinds of analysis; however, they require a choice of descriptive systems in an area where experts continue to disagree on fundamental issues, and they also require descriptive judgments whose intersubjective validity may be low.
The measures recommended here do require some subjective judgments -- about where the pitch tracking has gone astray, and about the location of modally-voiced open-tract regions. However, these are judgments about physically definable states of speech production, and one could find suitable automatic procedures without too much trouble that would have roughly the same results. In general, furthermore, the effects (on these measures) of small differences in judgment will also be small.