Mechanisms for gradual language change
« previous post | next post »
A few years ago, I wrote about a presentation by Bridget Jankowski on the trend towards increasing use of 's as opposed to of, in phrases like "the government's responsibility" vs. "the responsibility of the government". My post was "The genitive of lifeless things", 10/11/2009, and the slides from her talk are here.
I was reminded of this recently, while looking at usage changes in State of the Union messages over the centuries. Apostrophe-s has seen a recent radical increase in SOTU frequency, reflecting in amplified form a more gradual increase in the English language as a whole. Such gradual, long-term trends are a puzzle: why and how do linguistic changes keep going for several centuries in the same direction, as they often do? You could ask the same question about other cultural changes, I guess, but for linguistic features that are preserved in the written form of a language with a textual history, like English, we have quantitative evidence over hundreds of years.
In the case of gradual genetic changes, there's a clear explanation in terms of gene-pool proportions driven by a fitness gradient. But in the case of most linguistic changes, it's not obvious what the analogue to "fitness" is, or whether a concept like fitness is even relevant, unless it's defined circularly as whatever it is that causes the population frequency of a feature to increase.
I don't have a general answer to this question. But in the course of a dinner conversation the other day, Gareth Roberts and I came up with a couple of new (at least to me) ideas that might work for the on-going increase in s-genitive frequency, and for some other cases as well. The general idea is to combine a simple "linear learner" (which adjusts internal probability estimates based on current experience) with two additional kinds of influence: first, effects that bias the learner to pay a bit more attention to certain inputs; and second, forces that exert a small biasing effect on probability estimates due to weak analogies across constructions.
Let's start by establishing that there's something here to explain. This plot shows the decade-by-decade change in the SOTU messages and in the Corpus of Historical American English:

These changes are a mixture of s-contractions ("That's why I believe…") and s-genitives ("America's graduation rate"). But both constructions have been getting more frequent in written English — we can isolate the s-genitive almost completely by searching COHA for patterns like
children 's [n*] vs. [n*] of children
where [n*] means "any noun" — and the relative frequency of the s-genitive forms has more than doubled over the past 150 years or so:

We see a similar — or even larger — increase for patterns like
china 's [n*] vs. [n*] of china
where contraction is possible but rare (in a random sample of 100 instances of this pattern from 2010-2012, none were s-contractions):

And similarly for patterns like
god 's [n*] vs. [n*] of god

This change is part of a much older story — of-phrases and s-genitives have been waxing and waning in English for more than a millennium. According to Benedikt Szmrecsanyi et al., "Culturally conditioned language change? A multi-variate analysis of genitive constructions in ARCHER", 2013:
Historically speaking, the of-genitive is of course the incoming form, which appeared during the ninth century. […] [T]he inflected genitive vastly outnumbered the periphrasis with of up until the twelfth century. In the Middle English period, we begin to witness “a strong tendency to replace the inflectional genitive by periphrastic constructions, above all by periphrasis with the preposition of”. The Early Modern English period, however, sees a revival of the s-genitive, “against all odds”. […] [T]he s-genitive is comparatively – and increasingly – popular in Present-Day English, especially American English ….
Here are some numbers illustrating this process, from Charles C. Fries, "On the Development of the Structural Use of Word-Order in Modern English", Language 1940:
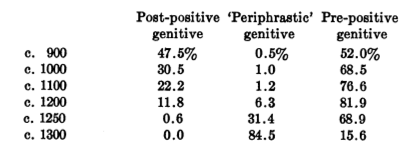
The "periphrastic genitive" is what we've called the "of-genitive" — the other cases are inflected genitives, the ancestors in some sense of the modern s-genitive. In Old English, these followed the head noun about as often as they preceded it. During the transition to Middle English, the post-head genitives died out and the pre-head genitives replaced them, only to be replaced in their turn by the of-genitives, except in the case of human possessors. But then, according to Anette Rosenbach ("Emerging variation: determiner genitives and noun modifiers in English", English Language and Linguistics 2007), "s-genitives have been shown to become more frequent from about late Middle/early Modern English onwards", due to a gradual increase in the frequency of s-genitives with collectives and inanimates:

In "A correlate of animacy", 9/27/2008, I sketched a crude and somewhat tongue-in-cheek picture of the gradient animacy relationship in modern web texts:
| __'s | of __ | ratio | |
| Giuliani | 1.14M | 140K | 8.14 |
| McCain | 23.6M | 4.42M | 5.34 |
| Clinton | 11.6M | 2.81M | 4.13 |
| Obama | 26M | 7.6M | 3.42 |
| Apple | 22.6M | 9.39M | 2.41 |
| IBM | 6.97M | 4.03M | 1.73 |
| Microsoft | 35.5M | 21.3M | 1.67 |
| 17M | 13.4M | 1.27 | |
| America | 113M | 131M | 0.863 |
| Canada | 26.8M | 60.5M | 0.443 |
| Thailand | 3.96M | 11.8M | 0.336 |
| England | 10.9M | 48M | 0.227 |
| Belgium | 799K | 6.31M | 0.127 |
| lithium | 60.7K | 1.73M | 0.035 |
| arsenic | 21.7K | 1.19M | 0.018 |
| silicon | 50.9K | 5.93M | 0.0086 |
| hydrogen | 45.3K | 9.44M | 0.0048 |
| cadmium | 4.01K | 2.2M | 0.0018 |
There's a more serious animacy hierarchy in Annete Rosenbach, "Animacy and grammatical variation", Lingua 2008:
| human | animal | collective | temporal | locative | inanimate |
| the boy's bike | the dog's collar | the company's director | Monday's mail | London's suburbs | the building's door |
There's also an effect of length, with longer possessor-phrases preferring the of-genitive. And I'm glossing over many syntactic, semantic, and lexical issues here: for example, "women's groups" and "groups of women" are not simply alternative ways of saying the same thing. But this post is already way too long. So trust me, doing a more careful job of characterizing the underlying phenomena leaves us faced with the same fact, which is that s-genitives declined relative to of-genitives for several hundred years, and then turned around and increased for few hundred years.
Why? One possible source of gradual changes in text statistics might be contact effects — we start with two different languages or language varieties, and patterns from one source gradually leak into the other. One plausible general case of this type would be gradually diminishing diglossia, where vernacular patterns gradually leak into the formal written language. This seems to me to be a plausible account of the increase over time in the frequency of contractions in English text — see e.g. "True Grit isn't true", 12/29/2010, for some relevant background.
There are clearly some genre differences with respect to English genitive choice — but in the end I don't believe that this is a plausible place to look for the forces driving the long-term trends.
In the 1940s, Otto Jespersen noted that poetic language tended to use more s-genitives, apparently due to rhetorical personification (A Modern English Grammar on Historical Principles: Volume 7, 1949, p. 346):
In poetry and in higher literary style the gen. of lifeless things is used in many cases where of would be used in ordinary speech; the gen. here conveys more or less a notion of personification […]
For example, he quotes Elizabeth Barrett Browning "at poetry's divine first finger-touch". But 19th-century poetic diction is surely not where we're going to find the forces driving long-term changes in English genitive choices.
Jespersen also notes a tendency for quite prosaic text to go in the same direction, if not by exactly the same route:
During the last few decades the genitive of lifeless things has been gaining ground in writing (especially among journalists): in instances like the following the of-constructions would be more natural and colloquially the only one possible:
His examples include several where the s-genitive now seems entirely colloquial to me, at least in their choice of genitive form:
the rapidity of the heart's action
a glass knob was the door's sole fitting
to affect a book's good or evil fortune
There's some quantitative evidence for Jespersen's remark about journalism in Bridget Jankowski's work, which shows that s-genitive proportion has increased over time in two corpora of Canadian English text, with Maclean's (a magazine) always ahead of the Hansards (parliamentary proceedings):

A comparison of s-genitive percentages for various head nouns, across COCA registers and the LDC's archive of conversational telephone speech, shows a somewhat similar picture:
| Spoken | Fiction | Magazine | Newspapers | Academic | LDC CTS | |
| "children" | 63.9% | 53.3% | 71.1% | 76.9% | 53.7% | 68.6% |
| "women" | 51.0% | 56.5% | 62.6% | 72.1% | 55.8% | 55.4% |
| "men" | 46.6% | 46.0% | 53.6% | 72.9% | 42.6% | 51.2% |
| "china" | 45.3% | 20.6% | 48.8% | 59.5% | 49.8% | 62.3% |
| "russia" | 39.5% | 17.9% | 53.5% | 55.4% | 59.1% | 56.8% |
But if journalism has somehow been driving other varieties, this simply raises the question of what forces have been driving the journalists. And the vernacular doesn't seem to be different enough from other registers to be the source of the long-term trends.
So what could be the mechanism?
Whatever else is happening, we can assume that individuals are adjusting some internal probability-like "belief" about the distribution of forms, which derives from their linguistic experience and also governs their linguistic behavior. One relevant source of evidence for this process can be found in the literature on syntactic priming, e.g. Martin Pickering and Holly Branigan, "Syntactic Priming in Language Production", Trends in Cognitive Science 1999.
In this situation, any bias that causes certain cases to have a somewhat larger impact, or to fade a bit more gradually, and to feed more strongly from short-time (priming-like) effects into long-term (baseline) values, could potentially drive a gradual long-term change in a speech community's distribution of probability estimates.
Thus in the history of s-genitive increase over the past few hundred years, we might hypothesize that animate references are on average more salient than inanimate ones; and therefore that animate genitives have a slightly greater impact on the relevant underlying constructional variable(s); and therefore that the perceived proportion of s-genitives tends to be slightly over-estimated, leading in turn to a slight increase in production; and recursively onwards.
A similar trend might also arise due to affinities across constructions, as Fries (1940) suggests:
The progressive fixing of the word-order pattern for modification can be illustrated by the facts concerning the position of the inflected genitive modifying a noun. Adjectival in its function, the inflected adnominal genitive in Old English appears, like the adjective, either before or after the noun it modifies. […]
Before the end of the 13th century the post-positive inflected genitive has completely disappeared. By this time the general word-order pattern to express the direction of modification has become well established: single word modifiers of the noun or adjective class preceding the nouns they modify remain in that position, whereas single word modifiers in other positions are not so kept.
If possessive constructions are treated as a form of modification, then ever since modifiers came to precede heads in English, maybe every adjective+noun or noun+noun modifier/head sequence has exerted a small force on speakers' internal estimates of s-genitive proportions.
To make these ideas plausible, we'd have to start by showing that the right kind of thing happens in simulations, and then look for experimental as a well as historical evidence to support the assumptions involved. It's possible that someone has already done this, or part of it — relevant references will be appreciated.
Update — A relevant reference has already arrived: Catherine O'Connor, Joan Maling & Barbora Skarabela, "Nominal categories and the expression of possession", in Kersi Börjars et al., Eds., Morphosyntactic Categories and the Expression of Possession, 2013. The abstract:
In this cross-linguistic study we present parallels between (a) the stochastic patterns found in corpus studies of English prenominal possessives, and (b) the rule-governed, categorical features of a highly constrained prenominal possessive construction found in some Germanic, Slavic, and Romance languages. The well-known English tendency for prenominal possessor NPs to be low-weight, animate, and discourse-old or highly accessible corresponds to categorical requirements in what we call the Monolexemic Possessor Construction (MLP). This construction is recognizable by its pre-nominal, one-word, animate possessor that is highly accessible in the discourse context. We identify an accessibility hierarchy of nominal categories in which the MLP can be expressed. This hierarchy is consistent with all 17 languages with MLPs we have found. We show that this accessibility hierarchy (pronoun< proper noun< kinship term< common noun) is a function of the intrinsic discourse-pragmatic features of these nominal categories. While the categorical restriction to pronoun and proper noun possessors in Icelandic, German, and Russian may be largely grammaticized, we show that the discourse-pragmatic constraint is recognizably active in Czech and Bosnian/Croatian/Serbian. These results complement studies that attempt to understand how language structure responds to communicative forces and processing constraints.
DaveK said,
February 9, 2014 @ 6:23 pm
"In poetry and in higher literary style the gen. of lifeless things is used in many cases where of would be used in ordinary speech; the gen. here conveys more or less a notion of personification"
Perhaps. But wouldn't a simpler explanation be that it's easier to cast a phrase into meter when there aren't small unstressed words like "of" cluttering things up?
Lazar said,
February 9, 2014 @ 6:40 pm
I remember seeing ads a few years ago for an initiative called "The Campaign for Nursing's Future", and finding that usage very odd – perhaps something to do with "nursing" being not only abstract but also anarthrous.
Jerry Friedman said,
February 9, 2014 @ 7:16 pm
These changes are a mixture of s-contractions ("That's why I believe…") and s-genitives ("America's graduation rate"). I like the BYU corpora a lot, but the tagging of every 's as a verb is really annoying.
DaveK: It depends. Sometimes you need those small unstressed words for the meter ("The slings and arrows of outrageous fortune") or to have the rhyming word in the right place. But I'd say in addition to personification, the more common use of 's in poetry probably comes from the desire for concision. Also, if I dare make a testable hypothesis here, I'd guess that whenever one construction is more common than another in prose, the ratio in metered verse is closer to 50-50 (or 33-33-33, etc.) because the decision is made according to the meter rather than whatever favors the common prose construction.
Angus Grieve-Smith said,
February 9, 2014 @ 7:41 pm
This is analogical extension, driven by relative productivity, as described by Bybee and Thompson (2000, PDF). I talk about a similar change in French negation in my dissertation.
[(myl) I was familiar with Bybee and Thompson (2000), which is relevant but does not, I think, deal with the same issues. They discuss two effects of token frequency and their interaction with an effect of type frequency: the "Reduction Effect" and the "Conserving Effect" of high token frequency, where the "Reduction Effect" involves grammaticalization of phonetic reduction in high-frequency tokens, while the "Conserving Effect" operates via resistance of high-frequency tokens to productive patterns with high type frequency.
None of these cases postulates a tendency towards probability mis-estimation due to greater salience of certain cases, as this post suggests for the role of animacy. And the idea that s-genitive frequency might also be affected by analogy with modifier-head order is due to Fries 1940, who found similar arguments from constructional analogy in many earlier works. Our innovation in this area, if any, is the idea that the analogy is weak enough that its effects on estimated s-genitive probability variables might take centuries to work themselves out. And this genitive/modifier analogy (or homology?) involves two different constructional types, or perhaps two levels of a type hierarchy, not the interaction of a construction type and various lexical tokens.
Grieve-Smith (forthcoming?) was not known to me, and looks like a terrific piece of work. (The link you supply leads to a 404 error — searching for your name turns up a proposal draft — is the final document available somewhere else?) The proposal deals with long-term gradual changes (in French negation). But I don't see the idea that greater salience of some cases might lead to systematic mis-estimation of probabilities; and the central questions raised deal (as in Bybee and Thompson 2000) with relations between (construction?) type and (lexical?) token frequencies, which may well be relevant to the evolution of the English genitive, but were not among the issues raised in this post.]
Mai Kuha said,
February 9, 2014 @ 9:33 pm
Could it have something to do with information structure – placing given information before new?
Angus Grieve-Smith said,
February 9, 2014 @ 9:41 pm
Mai, that could be the motivation for the reanalysis, but clearly the reanalysis has happened and the two constructions are already considered to be "the same" in some contexts. Once that happens it's pretty much frequency autopilot.
the other Mark P said,
February 9, 2014 @ 10:55 pm
The 12th century saw the advent in England of a lot of bilingual speakers of Norman French and English. Moreover French was the higher status language. French stayed the highest status language in high culture well into the nineteenth century.
French speakers tend to use the "of" form, as it is most similar to French. (This is true, in my experience, of Germans, Estonians and Swedes as well – it's much easier form for them. I don't know any Latin, so I don't know the effect that it had.) If people were language swapping a lot, the likely result would be a rise in the "of" form.
So I would surmise, as a first guess, that as English speakers have lost the French element, we have slowly reverted back to the native usage.
Angus Grieve-Smith said,
February 10, 2014 @ 12:37 pm
Sorry, that was the wrong link for my dissertation! Here's the correct link.
Thanks for your interest! It's the effect of type frequency in Bybee and Thompson (2000) that I'm referring to.
The general idea is that once we think of two constructions as "the same" (interchangeable in a particular context), we continue the previous distribution (from when there was some semantic or pragmatic motivation) as best we can remember.
Because our memories are not perfect, we tend to forget what the old distribution was, and use whichever construction comes to mind first. The likelihood of each construction is roughly proportional to its type frequency (or mindshare).
The two constructions may not be considered exactly "the same," which would lead to some interaction with the semantics of animacy. But this is not necessary to produce the S-curves in your charts.
Looking forward to further discussion!
Mark F. said,
February 10, 2014 @ 1:33 pm
The way ML phrases his explanation suggests that people are on some level trying to emulate the relative frequencies used by everyone else, while AG-S mentions the idea of using the first one that comes to mind, so that it's "mind share" that determines what is used. I think those are two different hypotheses, although I'm not ML meant to take sides.
On some level, I assume some parts of the brain have to have estimates of what constructions will be right in certain contexts, so that options can be presented to the next higher level of processing in sentence construction. So in that sense, "the first thing that comes to mind" might in fact be determined by sampling from a probability distribution that has been learned. So in that sense there aren't really two competing hypotheses.
But it's also possible that some of those higher levels get rewarded for matching community frequencies of usage when multiple options are permitted. I would even say it's quite likely. But I'm not sure how one would test it.
But then that suggests a higher level of prescriptivism where style guides would prescribe frequency bands for the usage of various constructions. Perhaps I shouldn't be releasing this idea into the wild.
Charles in Vancouver said,
February 10, 2014 @ 1:35 pm
the other Mark P:
Interesting if German speakers prefer the "of" form. German does have post-positive genitives, the type that English lost and never got back, e.g. "das Auto meines Bruders". But apparently that's becoming less common in spoken conversation. I would think in English post-positives made the most sense when we still had a more visible system of case markings, and as those eroded our word order became more rigid.
GeorgeW said,
February 10, 2014 @ 2:26 pm
@Angus Grieve-Smith and Mark F:
Do we really have instances of different constructions for the same context that can alternate freely? It seems to me that there will almost(?) always be some, at least slight, semantic or social difference.
Mark F. said,
February 10, 2014 @ 2:35 pm
GeorgeW – Probably not perfectly, but some are fairly close. The fact of this drift shows that there are places where both options are live. Anyway, you could imagine a map from contexts to probability distributions, and so what people would be trying to match would be that map.
Chris C. said,
February 10, 2014 @ 3:32 pm
I wonder if this is simply a case of gradual loss of separate registers for literary and oratorical English, as compared to the colloquial spoken one? The -'s form came back with Early Modern English, but it strikes me that much of that corpus is probably in the form of plays, and the playwrights may have been making a conscious effort to represent natural-sounding colloquial speech. (And also poetry, given the observation that -'s is more prevalent there.)
Angus Grieve-Smith said,
February 10, 2014 @ 4:32 pm
George W:
Bill Croft talks about this in his 2000 book. Complete interchangeability is an unstable state, and never lasts very long. One of the ways it disappears is by being whittled away like this over the course of a few centuries. Compare the "have" and "be" perfect tense constructions in English, or the Portuguese possessives with and without definite articles.
Rubrick said,
February 10, 2014 @ 5:36 pm
Might not the transition have been at least partly driven by a simple increase in brevity over time, and by brevity being increasingly seen as a virtue? Certainly "the tree's leaves" is more Strunkian than "the leaves of the tree"; and as MYL has already mentioned earlier in this series of posts, overall sentence length has been decreasing for a long time.
Mar Rojo said,
February 11, 2014 @ 7:58 am
Hey, guys, if I dare ask: I'm off to an ESL class right now and need to cover usage of the two forms. What advice can I now give to my students?
Michael Rank said,
February 11, 2014 @ 3:56 pm
I'm not sure just how relevant this is but I am under the strong impression that in journalistic usage e.g. China's president Xi Jinping has become much more common in recent decades than Chinese president Xi Jinping. Same goes for e.g. Italy's government/the Italian government.
the other Mark P said,
February 12, 2014 @ 4:34 am
MIchael Rank:
I wonder if that has something to do with the increasing movement of people across borders.
I'm sure it has happened with sports teams. People who used to be English rugby players, are now England rugby players. The reason, I suspect, is that the players playing for England are often not English. (It seems odd to be calling a player like Manu Tuilagi "English" when he is clearly Samoan. But he is definitely an England player.)
Journalists get into the habit, then apply it everywhere. And China's president, at least in theory, might not be Chinese.
Also, they often drop the possessive. It can be just "China president".
Oliver said,
February 12, 2014 @ 12:09 pm
German also has pre-positive genitive, but it is terribly old fashioned.
Kevin Stadler said,
February 13, 2014 @ 9:00 am
The same Anette Rosenbach you cited a number of times has also explicitly elaborated on this asymmetric priming-based mechanism in Jäger and Rosenbach: Priming and unidirectional language change (Theoretical Linguistics 34(2), 2008)
Jane Lamb-Ruiz said,
February 13, 2014 @ 1:52 pm
[T]he s-genitive is comparatively – and increasingly – popular in Present-Day English, especially American English [T]he s-genitive is comparatively – and increasingly – popular in Present-Day English, especially American English.
I wonder about this statement. What about the plural s-genitive?
UK usage: drugs war? Is the lack of an apostrophe a sign this is not a genitive without the apostrophe or apostrophe s? The UK usage war of drugs is prevalent. So, it would seem that drugs war is an s-genitive without an apostrophe. In the US, this is not an issue since it is viewed as a war **on** drugs. And adjectivized noun becomes: the drug war….
Matt_M said,
February 14, 2014 @ 8:08 am
@Jane Lamb-Ruiz:
Before speculating about usage issues, it's worth checking out what the usage actually is. Google Ngrams provides an easy way of researching such matters.
A quick search shows that "the drug war" is about five times more prevalent than "the drugs war", even in British English. And in British English, the phrase "the war of drugs" is practically nonexistent in edited prose, in contrast with "the war on drugs", which is quite frequent.
As for the idea that "the drugs war" means "the drug's war", we would expect that people at least sometimes spell it to match the way they intend it, but again, "the drug's war" is nonexistent in British English. Likewise, if it was a plural possessive, we would expect it to sometimes be anarthrous, like "women's clothing" instead of "the women's clothing", especially as it corresponds to the phrase "the war on drugs" (not "the war on the drugs"). But again, phrases like "of drugs war" (as opposed to "of the drugs war") do not occur in edited British prose.
Ran Ari-Gur said,
February 16, 2014 @ 2:39 am
Inflected genitives became less common in English around the same time that the other case distinctions disappeared as well. This is a common pattern cross-linguistically. By the time '-'s' started to increase in popularity, it was no longer a case ending: rather, the '-s' or '-es' of many genitives had been reanalyzed as a clitic or phrasal affix, and that pattern was generalized. (Other traces of Old English genitives came to be viewed as completely separate; no one associates "three-foot-tall" or "always" with the possessive '-s'.) So I think that Benedikt Szmrecsanyi et al. are simplifying the narrative a bit, in a misleading way: what was revived was not the same as what had been lost, and it did not recover the properties that caused it to become lost. There's no "against all odds" about it.
Florian Blaschke said,
April 4, 2014 @ 12:08 pm
Headlinese (and telegraphese) is conceivably one factor favouring the more succinct "Saxon" genitive, but it can hardly be the only factor.
Ran: True, "against all odds" is an unfortunate way to phrase it. "Unexpectedly" is better because a reversal of a seemingly well-entrenched linguistics tendency is just that; it's not as such exceedingly unlikely.
By the way, "szmr" struikes me as a rather excessive consonant cluster for (I have to assume) Hungarian; are you sure that there is not an accidentally dropped (accented?) consonant here? A web search brings up a Benedikt Szemrecsányi.
Florian Blaschke said,
April 4, 2014 @ 12:15 pm
(Actually, there's a notoriously strong tendency to avoid word-initial consonant clusters in Hungarian, apparently throughout its history and even pre-history.)