
Corpus-based Linguistic Research: From Phonetics to Pragmatics
INTRODUCTION TO THE TOPIC
The Past
What corpus-based linguistic research was like 200 (or even 50) years ago: Working by hand through data on paper; keeping records on slips or file cards; doing analysis with handworked addition, multiplication, division; making figures by hand on graph paper; etc. See e.g. Alvar Ellegård, "The Auxiliary 'Do': The Establishment and Regulation of Its Use in English", 1953:
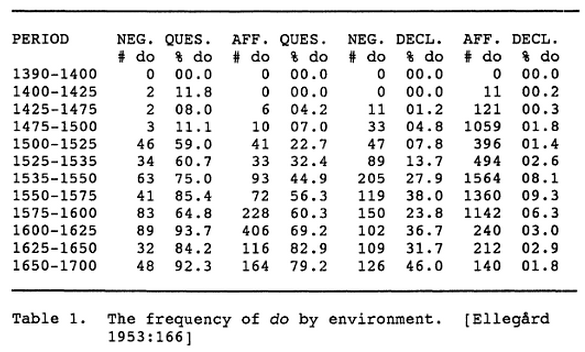
And for large-scale acoustic analysis, the situation of course was much worse. As of 1965 or so, the total amount of speech that had ever been subject to instrumental phonetic analysis in the scientific literature was well under ten hours, and may have been closer to one hour.
The Future
What corpus-based linguistic research will mostly be like 20 years from now: Investigating complete digital archives, using intuitive, expressive digital query systems whose results feed into intuitive, expressive digital analysis and display systems. For example, it will be possible to recapitulate Ellegård's work on "do", but applied to every extant piece of English text from the time-span in question, dividing the answers by geography, by genre, by verb, by the age of the writer, and so on -- framing queries in an intuitive way, and getting answers in a fraction of a second.
The Present
We're in a transitional period, where corpus-based linguistic research is many times easier than it was, before ubiquitous powerful-enough networked multimedia-capable computers, pervasive digital communication streams and archives, cheap mass storage in the terabyte range, excellent cheap or free software, etc.
As a result, there are some situations where you can use a somewhat intuitive, fairly expressive query system whose results can be transferred without too much difficulty to a somewhat intuitive, fairly expressive analysis system.
Still, recapitulating Ellegård on a larger scale, though much easier than it was in 1953, remains difficult.
For people who have mastered the less intuitive, less expressive ends of the search and analysis spectrum, and who have access to appropriate digital datasets, what would 60 years ago have been a heroic accomplishment is now a Breakfast Experiment™. For example, the counts for the Breakfast Experiment™ documented in "Yeah No", 4/3/2008, are roughly comparable in scale to Ellegård's investigation of do-support, but took me only a few seconds to create. For an analogous example dealing with instrumental analysis of speech, see e.g. "Nationality, Gender and Pitch", 11/12/2007.
And in specific relation to the history of do-support, see Aaron Ecay's handout "On the graduated evolution of do-support in English", 3/20/2010, and his slides for "Three-way competition and the emergence of do-support in English", DiGS14, which present and analyze numbers based on digital searching of two published historical "treebanks": PPCEME and PCEEC:
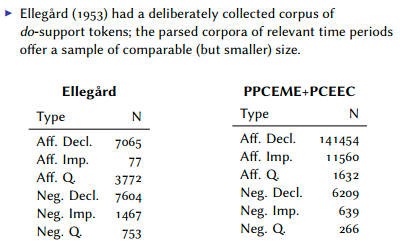
The goal of this course is to give you a sense of the landscape in this area, and to help you to make choices about selecting research topics, finding relevant data, learning and applying analysis skills, and so forth.
A Note on the Value of Shared Data
When research datasets are available, there's more research, because this lowers barriers to entry.
When research datasets are shared, the research is better, because results can be replicated, mistakes can be corrected, and algorithms and theories can be compared. In addition, shared datasets are typically much bigger and more expensive than any individual researcher's time and money would permit.
When datasets are associated with well-defined research questions, the whole field gets better, because the people who work on the "common tasks" form a community of practice within which ideas and tools circulate rapidly.
And finally, well-designed datasets usually turn out to be useful for many kinds of research besides those for which they were originally designed.
Advances in networking, computing, and mass storage mean that there's no longer any significant technical barrier to the publication of research datasets. It's past time for such publication to become the norm.
One (almost) good example: Bert Remijsen, "Tonal alignment is contrastive in falling contours in Dinka", Language 2013. You can download the dataset on which the acoustic analysis is based, and the stimuli used in the perception study. Later in the course, I'll discuss some work I was able to do in just a few hours, given access to Bert's data.
The only problem: these datasets are just stored on Bert's personal site that the University of Edinburgh -- a more permanent home for such material should be normal, provided by journals like Language, whose editors should not only offer to host such datasets, but should insist on doing so.