|
This is a research project that began in September, 2002, based at the Institute for Research in Cognitive Science (IRCS) at the University of Pennsylvania. It is funded for five years via award EIA-0205448 from the National Science Foundation's Information Technology Research (ITR) program. |
|
|
Abstract: Our goal is qualitatively better methods for automatically extracting information from the biomedical literature, relying on recent progress and new research in three areas: high-accuracy parsing, shallow semantic analysis, and integration of large volumes of diverse data. We are focusing initially on two applications: drug development, in collaboration with researchers in the Knowledge Integration and Discovery Systems group at GlaxoSmithKline, and pediatric oncology, in collaboration with researchers in the eGenome group at Children's Hospital of Pennsylvania. These applications, worthwhile in their own right, provide excellent test beds for broader research efforts in natural language processing and data integration. In particular, we propose to develop and test new general methods for information extraction from text, based on on-going research at Penn in corpus-based algorithms for parsing, predicate-argument analysis and reference resolution. We will collaborate with groups led by Robert Gaizauskas at the University of Sheffield (UK) and by Jun-ichi Tsujii at the University of Tokyo (Japan), as well as with the GSK and CHOP groups, in applying these general methods to particular problems in biomedical information extraction. The GSK group has already made effective use of the best available information-extraction technology, so that the new techniques can be assessed in the drug-development application for their added value relative to the state of the art. To give a simple, concrete example, we want a program that will read a phrase like
and add to a database a set of entries whose ordinary-language presentation is
This project will also address several database research problems, including methods for modeling complex, incomplete and changing information using semistructured data, and also ways to connect the text analysis process to an information integration environment that can deal with the wide variety of extant bioinformatic data models, formats, languages and interfaces. Such problems are central to current database research at Penn. Our work will build on the progress represented by Penn's K2/Kleisli data integration environment, by extending it to deal with semi-structured data. This will be important managing the information that is extracted, and also in making use of the many specialized data resources that can be brought to bear in generating the high-accuracy text analysis required to extract the information effectively in the first place. Because the K2/Kleisli system is widely used in bioinformatics applications, and in particular has been used for several years at GSK, these extensions will facilitate collaboration with biomedical researchers as well as supporting the IE research itself. The engine of recent progress in language processing research has been linguistic data: text corpora, treebanks, lexicons, test corpora for information retrieval and information extraction, and so on. Much of this data has been created by Penn researchers and published by Penn's Linguistic Data Consortium. As part of the proposed project, we will develop and publish new linguistic resources in three categories: a large corpus of biomedical text annotated with syntactic structures (Treebank) and shallow semantic structures ("proposition bank" or Propbank); a large set of biomedical abstracts and full-text articles annotated with entities and relations of interest to researchers, such as enzyme inhibition, or mutation/cancer connections (Factbanks); and broad-coverage lexicons and tools for the analysis of biomedical texts. |
| A sister project entitled "Language, Learning and Modeling Biological Sequences", funded via NSF ITR award EIA-0205456, is also underway at IRCS. |
|
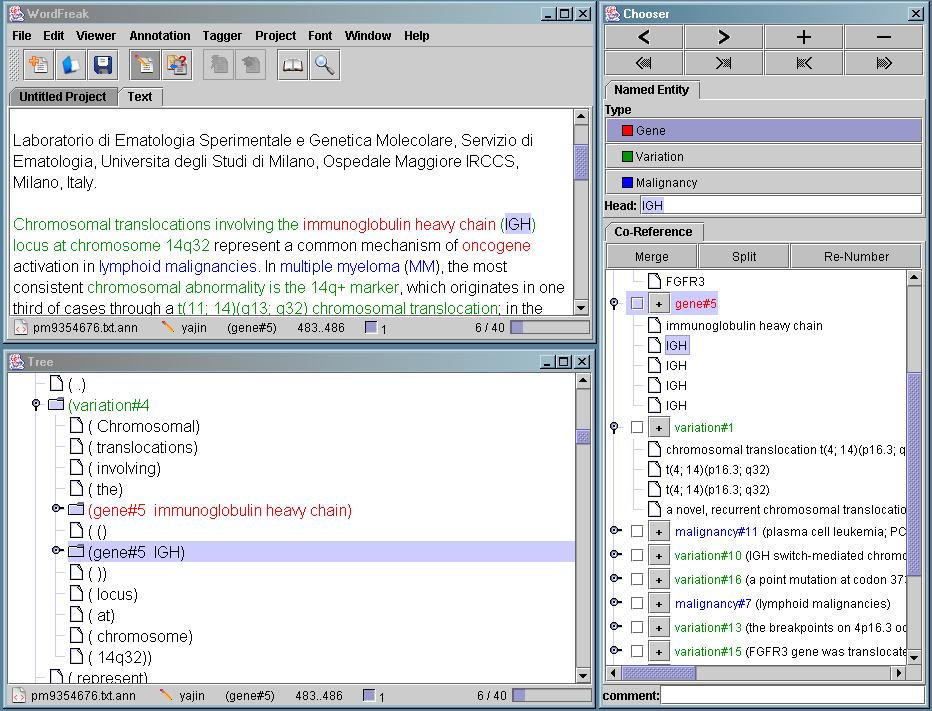
| Screenshot
of text annotation tool as of fall 2003 |
|
|
Seth Kulick, Mark Liberman, Martha Palmer, and Andrew Schein. Shallow Semantic Annotation of Biomedical Corpora for Information Extraction. To appear in the 2003 ISMB Special Interest Group Meeting on Text Mining (a.k.a. BioLink). June 2003. Brisbane, Australia. [.ppt, .pdf] Winters, McDonald, Jin, Kim, Wooster, Liberman, Pereira, and White. Extraction of cancer-specific genomic variation from the biomedical literature. HGVS Scientific & Annual General Meeting November 4, 2003. [.pdf, .ppt] Seth Kulick, Ann Bies, Mark Libeman, Mark Mandel, Ryan McDonald, Martha Palmer, Andrew Schein and Lyle Ungar, Integrated Annotation for Biomedical Information Extraction (HLT/NAACL, Boston, May 2004) [Paper .pdf , Slides .ppt] Rishi Talreja, Andrew Schein, Scott Winters and Lyle Ungar. GeneTaggerCRF: An Entity Tagger for Recognizing Gene Names in Text. (submitted, May 2004). [.pdf] |
|
Annotation tool ("Wordfreak"): http://www.sf.net/projects/wordfreak Taggers: http://www.cis.upenn.edu/datamining/software_dist/biosfier/ Workflow management system (LAW): http://www.sf.net/projects/law |
|
{kind=link}